Clear Sky Science · de
Vorausgeconditioniertes inexactes stochastisches ADMM für tiefe Modelle
Intelligenteres Training für intelligentere KI
Moderne KI-Systeme, von Chatbots bis zu Bildgeneratoren, basieren auf riesigen neuronalen Netzen, die bekanntlich schwer und teuer zu trainieren sind. Wenn Unternehmen und Forscher Daten auf viele Geräte und Server verteilen, verlangsamen sich die heutigen Standard-Trainingsverfahren oft, werden instabil oder kommen mit der Unordnung realer Daten schlicht nicht zurecht. Dieser Artikel stellt eine neue Familie von Trainingsalgorithmen vor, die auf einer Methode namens PISA basiert und schnelleres, zuverlässigeres Lernen für eine breite Palette tiefer Modelle verspricht, während sie weniger mathematische Annahmen über die Daten macht.
Warum aktuelle Trainingsmethoden ins Straucheln geraten
Die meisten Deep-Learning-Modelle werden mit Varianten des stochastischen Gradientenabstiegs trainiert, einem Ansatz, der Modellparameter wiederholt in Richtungen verschiebt, die den Fehler reduzieren. Im Laufe der Jahre haben viele Verfeinerungen – etwa Adam, RMSProp und andere – versucht, diese Schritte durch Anpassung von Schrittweiten oder Zusatz von Momentum intelligenter zu machen. Diese Methoden setzen jedoch meist voraus, dass Trainingsdaten ordentlich durchmischt und statistisch ähnlich über Rechenmaschinen verteilt sind und dass bestimmte mathematische Größen beschränkt bleiben. In der Praxis, insbesondere in Szenarien wie dem föderierten Lernen, in denen Telefone oder Edge-Geräte sehr unterschiedliche Daten halten, werden diese Annahmen oft verletzt, was zu langsamer Konvergenz oder schlechter Leistung führt.
Ein neuer Weg zur Koordination vieler Lernender
Die Autoren bauen auf einem anderen Optimierungsrahmen auf, der als alternierende Richtungs-Multiplikatoren-Methode (ADMM) bekannt ist und sich gut dafür eignet, ein großes Problem in viele kleinere zu zerlegen, die parallel gelöst werden können. Ihr Hauptbeitrag, PISA (preconditioned inexact stochastic ADMM), bewahrt die Stärken von ADMM und vermeidet gleichzeitig dessen übliche Nachteile – etwa die Notwendigkeit, vollständige Gradienten über alle Daten zu berechnen oder teure Matrixinversionen durchzuführen. Stattdessen lässt PISA jeden Client oder Worker-Knoten seine eigene Modellkopie nur mit einer Mini-Batch von Daten aktualisieren und koordiniert diese Aktualisierungen über eine zentrale Variable. Sorgfältig entworfene "Preconditioning"-Matrizen formen die Aktualisierungsrichtungen so um, dass das Lernen gleichmäßiger und effizienter voranschreitet. 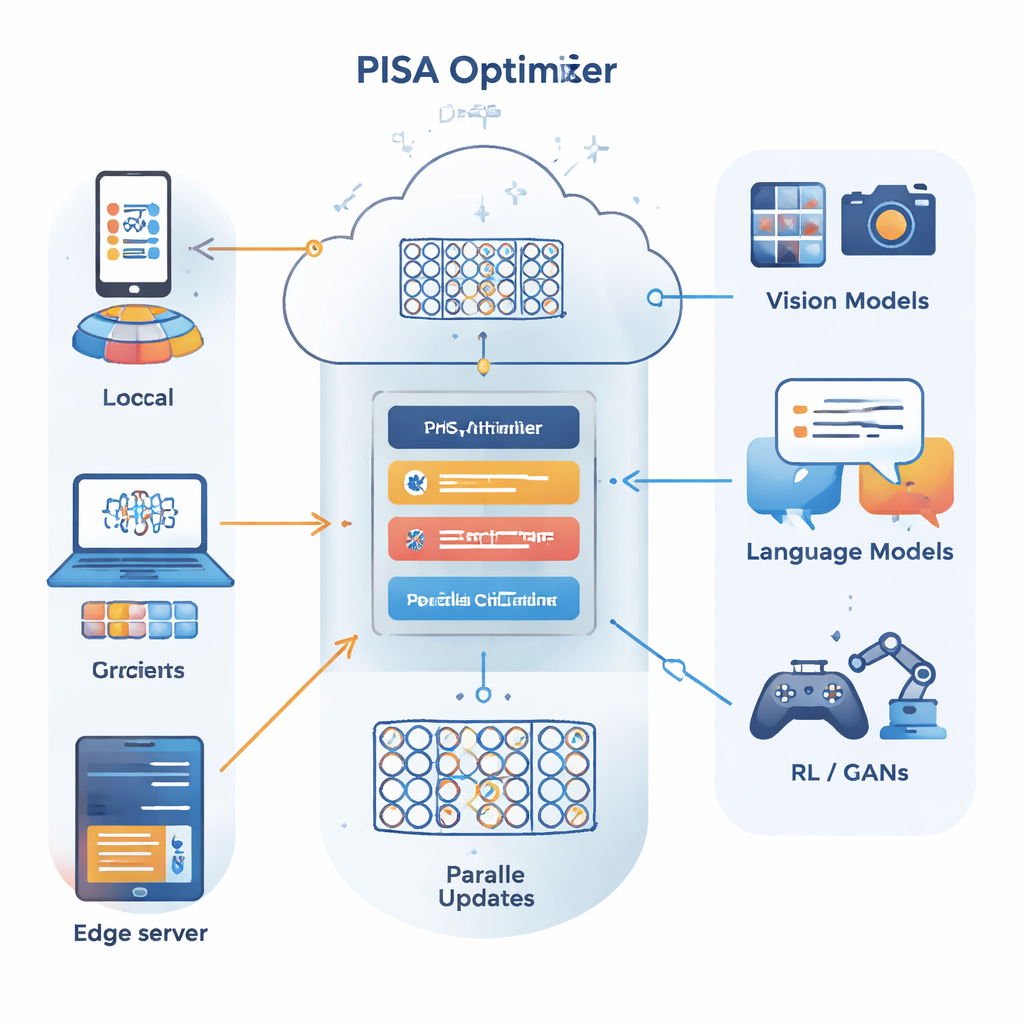
Stärkere Garantien bei milderen Annahmen
Ein markantes Merkmal von PISA ist seine theoretische Fundierung. Die Autoren beweisen, dass ihr Algorithmus unter genau einer relativ milden Annahme konvergiert: dass der Gradient der Verlustfunktion innerhalb eines beschränkten Bereichs Lipschitz-stetig ist, eine Bedingung, die von vielen Standardverlusten in neuronalen Netzen erfüllt wird. Anders als die meisten stochastischen Methoden verlangt PISA nicht, dass Gradienten unverzerrt sind, eine beschränkte Varianz haben oder aus perfekt durchmischten Daten stammen. Trotz dieses gelockerten Setups erreicht die Methode eine lineare Konvergenzrate hinsichtlich der Stabilisierung von Funktionswerten und Parameteraktualisierungen und reiht sich damit unter die leistungsstärksten Algorithmen in der Vergleichstabelle ein. Das macht PISA besonders attraktiv für heterogene, nicht-uniforme Datenverteilungen, wie sie in realen Anwendungen häufig vorkommen.
Praktische Varianten für reale tiefe Netzwerke
Um das Framework für große neuronale Netze praktisch nutzbar zu machen, führen die Autoren zwei effiziente Varianten ein: SISA und NSISA. SISA verwendet Informationen aus dem zweiten Momentum – im Wesentlichen die Nachverfolgung, wie groß vergangene Aktualisierungen in jeder Parameter‑Richtung waren – um einfache diagonale Preconditioner zu bilden, ähnlich den Ideen hinter Adam und RMSProp, aber eingebettet in die ADMM-Struktur. NSISA geht einen Schritt weiter und integriert eine Technik, die als Newton–Schulz-Orthogonalisierung bekannt ist und vom Muon-Optimizer inspiriert wurde, um Momentum besser mit nützlichen Richtungen im Parameterraum auszurichten. Beide Varianten behalten die Konvergenzgarantien von PISA bei und halten den Rechenaufwand zugleich leichtgewichtig genug für moderne GPUs und große Modelle.
Leistung in Vision-, Sprach- und Generativmodellen
Die Autoren testen SISA und NSISA über eine breite Palette von Deep‑Learning-Aufgaben. In föderierten Lernexperimenten mit absichtlich verzerrten Label‑Verteilungen – einem schwierigen Szenario, in dem jeder Client nur eine Teilmenge der Klassen sieht – übertrifft SISA populäre Methoden wie FedAvg, FedProx, FedNova und Scaffold deutlich und erzielt wesentlich höhere Testgenauigkeiten bei Benchmarks wie MNIST und CIFAR‑10. Für Standardbildklassifikation mit Modellen wie ResNet und DenseNet auf CIFAR‑10 und ImageNet erreicht SISA gleichwertige oder bessere Ergebnisse als starke Optimierer, darunter SGD mit Momentum, AdaBelief und AdamW. Beim Fine‑Tuning von GPT2‑Sprachmodellen wachsender Größe liefert NSISA niedrigere Validierungsverluste in kürzerer Echtzeit als spezialisierte Optimierer wie Shampoo, SOAP, Adam‑mini und Muon; der Vorteil wird bei den größten Modellen deutlicher. Es stabilisiert außerdem das Training generativer adversarischer Netzwerke und erzielt niedrigere Fréchet‑Inception‑Distance‑Werte, die die visuelle Qualität und Vielfalt generierter Bilder messen. 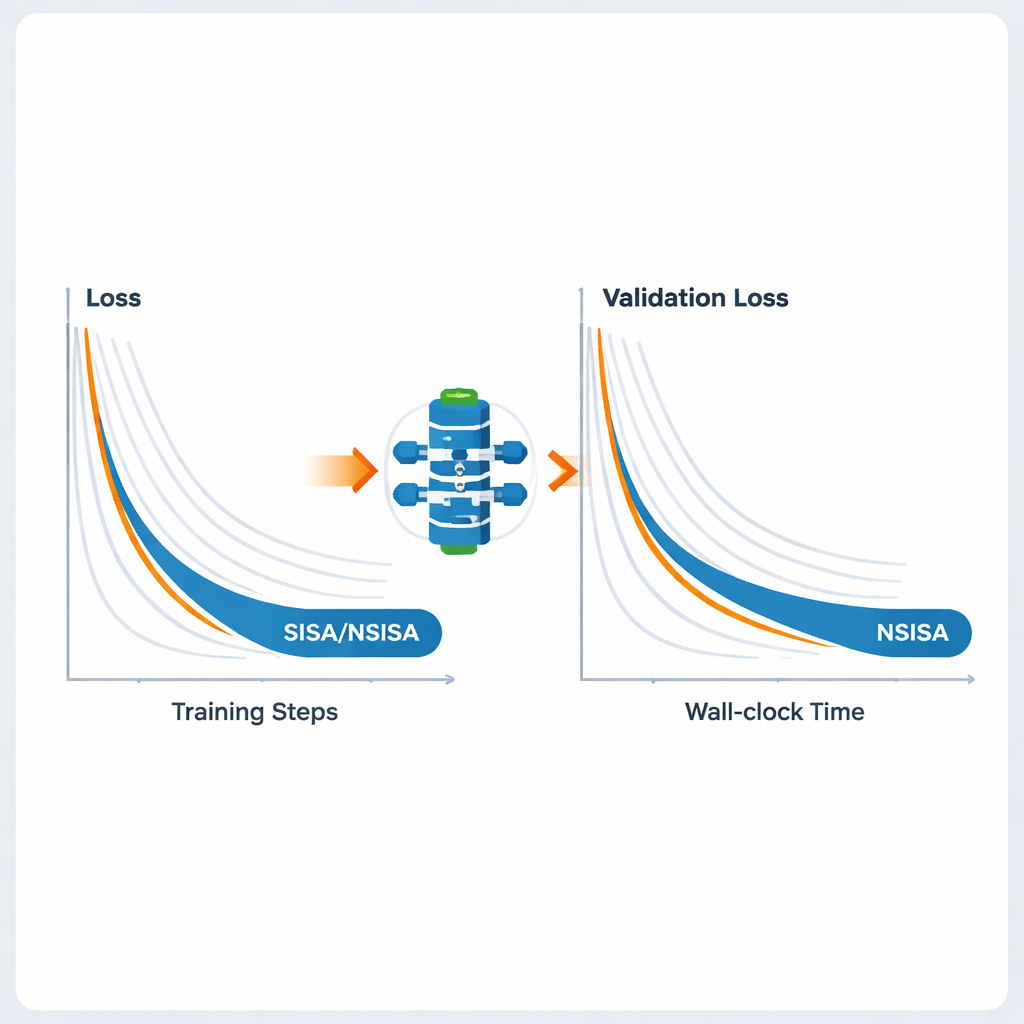
Was das für den Alltag der KI bedeutet
Einfach gesagt zeigt diese Arbeit, dass es möglich ist, leistungsstarke KI‑Modelle schneller und zuverlässiger zu trainieren, selbst wenn Daten ungeordnet, unausgewogen oder über viele Geräte verteilt sind. Indem der zugrundeliegende Optimierungsprozess neu gestaltet statt nur Lernraten feinjustiert werden, bieten PISA und seine Varianten ein einheitliches Werkzeug, das in Vision-, Sprach-, Reinforcement‑Learning‑ und Generativaufgaben gut funktioniert. Für Endanwender könnte sich das in intelligenterer Personalisierung auf Phones, leistungsfähigeren Sprach‑ und Bildmodellen und effizienterer Nutzung von Rechenressourcen in großen Rechenzentren auszahlen – alles ermöglicht durch einen Trainingsalgorithmus, der besser zu den Realitäten moderner KI‑Systeme passt.
Zitation: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Schlüsselwörter: Optimierung im Deep Learning, Föderiertes Lernen, stochastisches ADMM, große Sprachmodelle, heterogene Daten