Clear Sky Science · de
Wenn große Sprachmodelle zuverlässig sind, empathische Kommunikation zu beurteilen
Warum maschinelle Empathie für Sie wichtig ist
Immer öfter wenden sich Menschen an Chatbots und digitale Assistenten, wenn sie gestresst, einsam oder vor schwierigen Entscheidungen stehen. Diese Systeme können fürsorglich und verständnisvoll klingen — aber können sie auch beurteilen, ob eine Nachricht wirklich unterstützend und freundlich ist? Dieser Artikel untersucht, wann große Sprachmodelle (LLMs), die Technik hinter vielen Chatbots, verlässlich einschätzen können, wie empathisch eine schriftliche Antwort wirkt, und was das für Alltagswerkzeuge wie Wellness‑Apps, virtuelle Therapeutinnen und Kundenservice‑Bots bedeutet. 
Untersuchung unterstützender Gespräche
Die Forschenden analysierten 200 reale textbasierte Gespräche, in denen eine Person ein persönliches Problem schilderte — etwa Stress bei der Arbeit, familiäre Konflikte, Geldsorgen oder psychische Belastungen — und eine andere Person versuchte, unterstützend zu antworten. Diese Gespräche stammen aus vier bestehenden Datensätzen, die jeweils an unterschiedliche Bewertungsfragen zur Empathie gebunden sind. Einige konzentrierten sich darauf, ob die Antwortende Verständnis zeigte oder emotionalen Trost bot; andere fragten, ob praktische Ratschläge gegeben wurden, zur weiteren Äußerung ermutigt wurde oder ob das Gespräch stattdessen auf die eigene Person gelenkt wurde. Zusammen zerlegen diese Rahmenwerke „empathisch sein“ in 21 spezifische Verhaltensweisen, die auf Skalen bewertet werden können — ähnlich wie bei einer Kundenzufriedenheitsumfrage.
Expertinnen, Crowds und Maschinen
Um zu prüfen, wie gut LLMs Empathie bewerten können, verglich das Team drei Arten von Bewerterinnen: Kommunikations‑Expertinnen, Online‑Crowdworker und moderne Sprachmodelle. Drei erfahrene Wissenschaftlerinnen im Bereich empathische Kommunikation bewerteten unabhängig voneinander jedes Gespräch in allen 21 Verhaltensweisen. Crowdworker — alltägliche Internetnutzerinnen — hatten in früheren Studien bereits Bewertungen für dieselben Nachrichten geliefert. Schließlich wurden drei führende Sprachmodelle mit leicht verständlichen Richtlinien und Beispielbewertungen der Expertinnen sorgfältig instruiert und dann gebeten, jedes Gespräch nach denselben Skalen zu bewerten. Dieses Vorgehen ermöglichte es den Autorinnen, zu messen, wie eng die Gruppen übereinstimmten — nicht nur mit einer „richtigen“ Antwort, sondern miteinander. 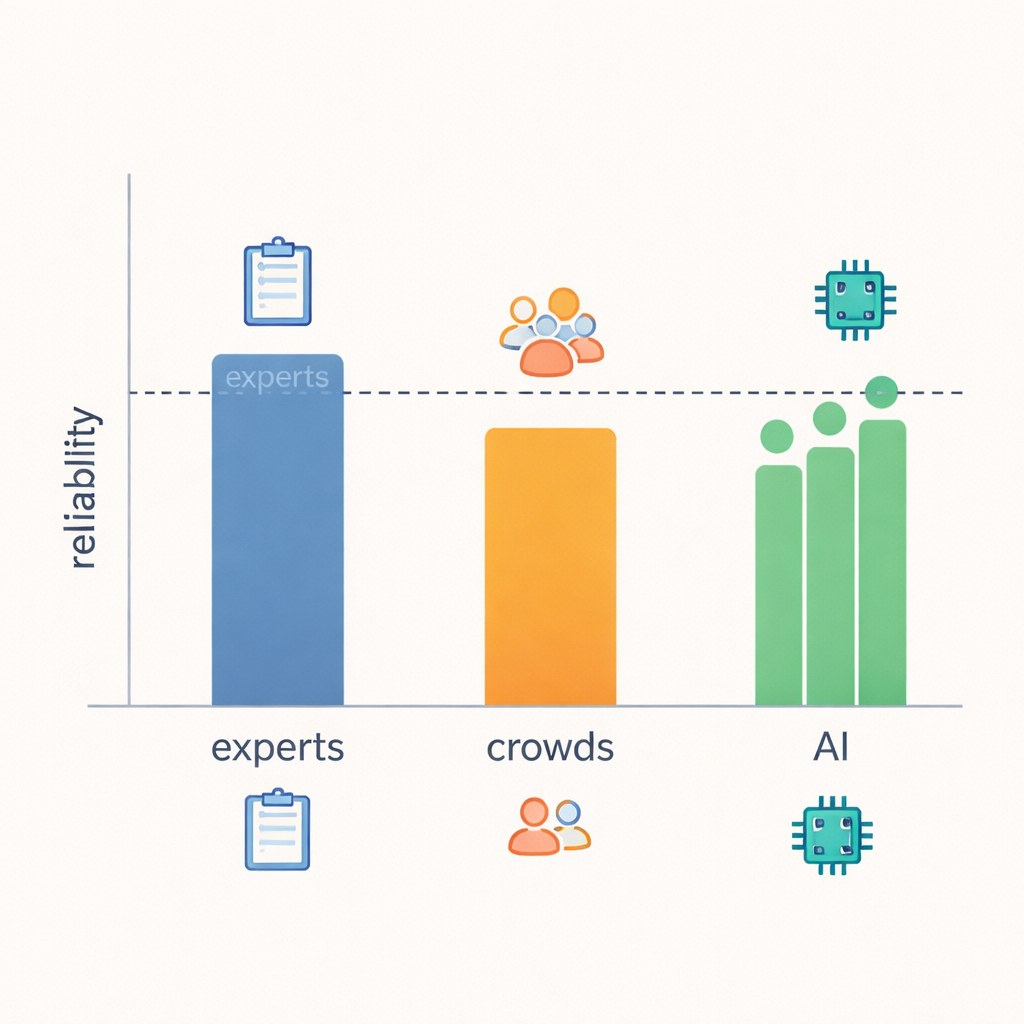
Wie stark stimmen sie überein?
Der zentrale Befund ist, dass LLMs überraschend nahe an die Zuverlässigkeit von Expertinnen herankamen. Wenn die Forschenden maßen, wie oft Bewertungen übereinstimmten und wie groß die Meinungsverschiedenheiten waren, erreichten die Modelle in den meisten der 21 Verhaltensweisen das Niveau der Expertinnen oder kamen ihm sehr nahe, und sie übertrafen deutlich die Crowdworker. In Bereichen mit klaren, beobachtbaren Hinweisen — etwa ob eine Antwort praktische Ratschläge gab, Folgefragen stellte oder die Aufmerksamkeit auf die Sprecherin zurücklenkte — neigten Expertinnen, LLMs und sogar die Crowd zu stärkerer Übereinstimmung. Wenn es jedoch um unschärfere Konzepte ging, wie etwa ob eine Antwort wirklich „Verständnis zeigte“ oder welche Absichten die Antwortende hatte, stimmten selbst Expertinnen öfter weniger überein, und die Zuverlässigkeit der LLMs sank mit der der Expertinnen. Das legt nahe, dass einige Aspekte von Empathie schlicht schwer allein aus Text zu bestimmen sind, unabhängig davon, wer bewertet.
Warum einfache Scores täuschen können
Viele KI‑Studien berichten von Erfolgen mit vertrauten Klassifikations‑Scores — indem jede Expertenbewertung als unangefochtene Wahrheit behandelt und gemessen wird, wie oft ein Modell damit übereinstimmt. Die Autorinnen zeigen, dass dieses Vorgehen ein verzerrtes Bild liefern kann, wenn es um subtile menschliche Urteile geht. Ein System kann zum Beispiel gut abschneiden, indem es meist die Mehrheitsbewertung auf einer unausgewogenen Skala vorhersagt, selbst wenn es in selteneren, aber wichtigen Fällen versagt. Ebenso kann eine Methode, die meist „fast richtige“ Bewertungen abgibt — nur um einen Punkt daneben — auf einer strengen Treffer‑Metrik schlecht dastehen, obwohl sie sich ähnlich wie ein menschlicher Experte verhält. Indem die Studie auf Interrater‑Reliabilität fokussiert — wie konsistent verschiedene Bewerter dasselbe beurteilen — bietet sie ein ehrlicheres Bild dessen, was sowohl Menschen als auch Maschinen verlässlich einschätzen können.
Was das für Alltags‑KI bedeutet
Für Laien ist die Schlussfolgerung zugleich hoffnungsvoll und warnend. Gut konfigurierte LLMs können inzwischen helfen zu überprüfen, ob schriftliche Antworten — von menschlichen Helferinnen oder anderen Bots — den Expertenstandards empathischer Kommunikation entsprechen, und sie tun dies oft konstanter als ungeschulte menschliche Bewerterinnen. Das könnte die Überwachung und Verbesserung von Chatbots in Gesundheitswesen, Bildung und Kundenservice erleichtern. Zugleich warnt die Studie davor, dass nicht alle „Empathie‑Tests“ gleich geschaffen sind: vage oder sich überschneidende Fragen führen zu schwacher menschlicher Zustimmung und damit zu unsicheren maschinellen Urteilen. Bevor man KI vertraut, etwas so Delikates wie emotionale Unterstützung zu bewerten, sollte man daher sicherstellen, dass die Expertinnen selbst darin übereinstimmen, wie „gutes“ Verhalten aussieht — und diesen Maßstab nutzen, um zu entscheiden, wo Maschinen sicher unterstützen können und wo menschliches Urteilsvermögen unverzichtbar bleibt.
Zitation: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Schlüsselwörter: empathische Kommunikation, große Sprachmodelle, KI‑Begleiter, Unterstützung bei psychischer Gesundheit, Mensch–KI‑Interaktion