Clear Sky Science · de
Verbesserung der kcat‑Vorhersage durch restbewussten Aufmerksamkeitsmechanismus und vortrainierte Repräsentationen
Warum schnellere Enzymvorhersagen wichtig sind
Enzyme sind die winzigen Arbeitskräfte, die Zellen – und ganze Industrien – am Laufen halten. Sie beschleunigen chemische Reaktionen, die unseren Stoffwechsel antreiben, Medikamente ermöglichen und umweltfreundlichere Herstellungsverfahren fördern. Eine Schlüsselgröße, die beschreibt, wie schnell ein Enzym arbeitet, ist die Umsatzzahl, kcat. Die Messung von kcat im Labor ist zeitaufwändig und teuer, weshalb Wissenschaftler KI einsetzen, um sie aus Sequenz‑ und Reaktionsdaten vorherzusagen. Diese Arbeit stellt PMAK vor, ein neues KI‑Modell, das kcat nicht nur genauer vorhersagt als frühere Werkzeuge, sondern auch hilft zu identifizieren, welche Teile eines Enzyms für seine Aktivität am wichtigsten sind.
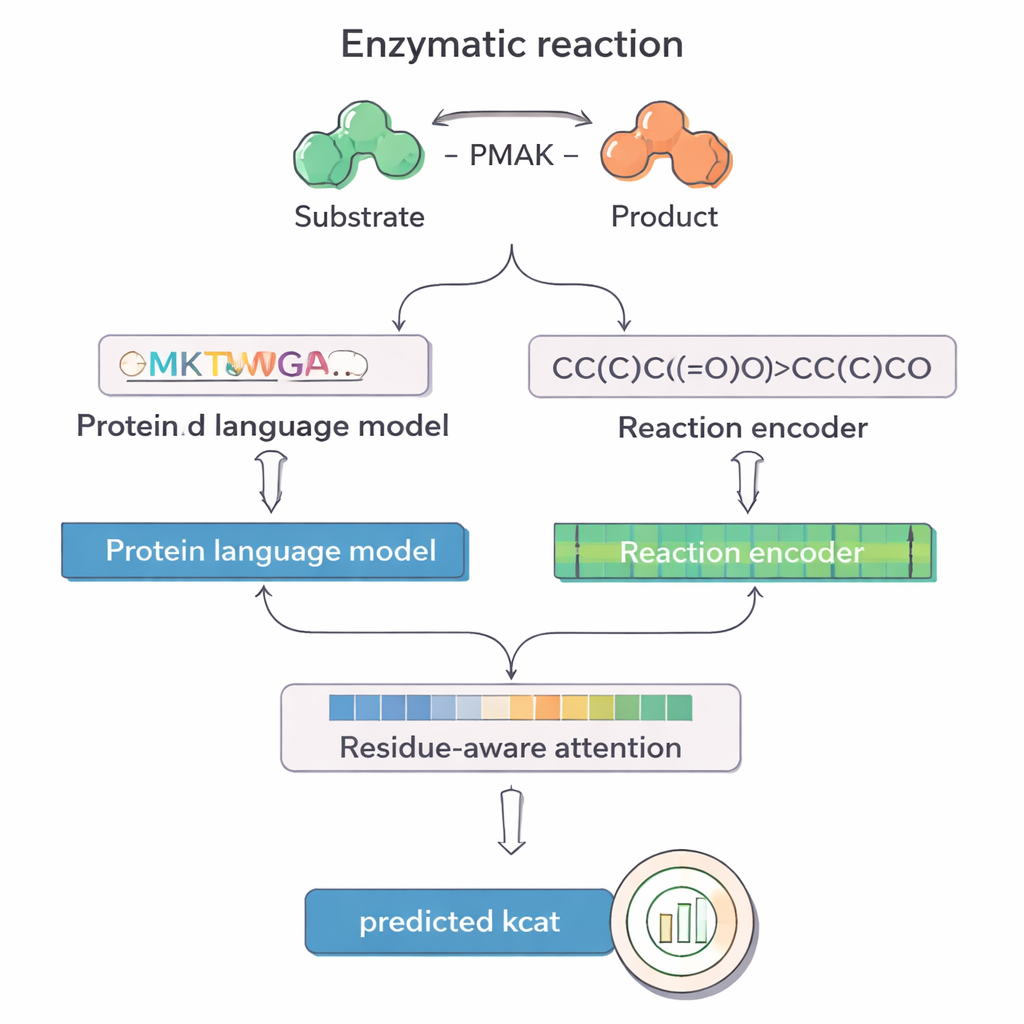
Vom mühsamen Labor zur smarten Vorhersage
Traditionell bedeutet die Bestimmung von kcat, sorgfältig zu messen, wie schnell ein Enzym sein Substrat unter streng kontrollierten Bedingungen—wie konstanter Temperatur und pH—in Produkt umsetzt. Das für Tausende von Enzymen durchzuführen ist unpraktisch, was die Modellierung ganzer Stoffwechselnetzwerke oder das Design neuer Biokatalysatoren einschränkt. Frühere Computerverfahren versuchten, diese Lücke zu schließen, stützten sich jedoch oft auf manuell erstellte Merkmale oder betrachteten nur ein vereinfachtes Bild eines Enzyms und eines einzelnen Substrats. Sie funktionierten häufig nur dann gut, wenn neue Enzyme den bereits im Trainingssatz gesehenen sehr ähnlich waren, und hatten Schwierigkeiten mit echten Neuerungen, neuen Reaktionen oder konstruierten Mutanten.
Computern die „Sprache“ von Enzymen und Reaktionen beibringen
PMAK nutzt jüngste Fortschritte bei „Sprachmodellen“, die ursprünglich für Text entwickelt, dann aber auf riesige Sammlungen von Proteinsequenzen und chemischen Reaktionen umtrainiert wurden. Ein Modell namens ProT5 verwandelt die Aminosäuresequenz eines Enzyms in eine reichhaltige numerische Repräsentation, die Muster einfängt, die aus Millionen von Proteinen gelernt wurden. Ein anderes Modell, RXNFP, macht Ähnliches für ganze Reaktionen, dargestellt als SMILES‑Strings, die alle Reaktanten und Produkte kodieren. PMAK führt diese beiden gelernten Repräsentationen in ein neuronales Netz, das ihre Dimensionen anpasst und dem Modell erlaubt, sowohl das Enzym als auch den vollständigen Reaktionskontext gemeinsam zu berücksichtigen, anstatt sie getrennt zu behandeln.
Die wichtigsten Bausteine hervorheben
Eine zentrale Neuerung in PMAK ist ein „rest‑bewusster Attention‑Mechanismus“. Anstatt jede Aminosäure in einem Enzym als gleich wichtig zu behandeln, lernt das Modell, bestimmten Resten höhere Gewichte zuzuweisen, die für die jeweilige Reaktion besonders relevant sind. Diese Attention‑Scores wirken wie ein Scheinwerfer auf der Sequenz: Als die Forschenden sie mit bekannten aktiven und Bindungsstellen aus Proteinstrukturen verglichen, stellten sie fest, dass PMAK funktionelle Reste deutlich häufiger hervorhob als durch Zufall zu erwarten wäre. Das Modell zeigte zudem gute Leistung, selbst wenn aktive Stellen weiter gefasst wurden, um benachbarte Reste im 3D‑Raum einzubeziehen, was darauf hindeutet, dass es subtile strukturelle und chemische Hinweise erfasst, die für die Katalyse relevant sind.
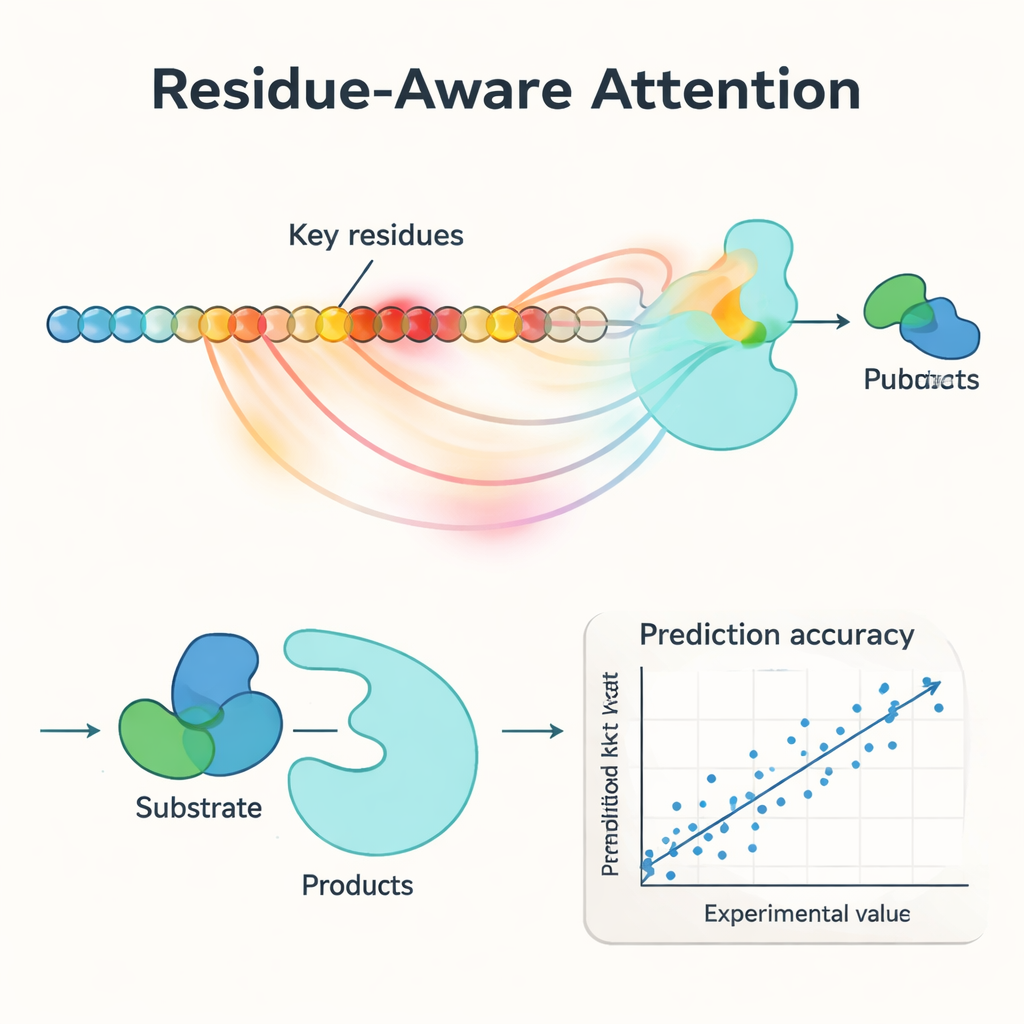
Gute Leistung bei neuen Enzymen, neuen Reaktionen und Mutanten
Die Autor:innen testeten PMAK rigoros an einem kuratierten Datensatz mit mehr als 4.000 kcat‑Werten, die fast 3.000 Enzyme und 2.800 Reaktionen abdecken. Unter „Warm‑Start“‑Bedingungen – bei denen ähnliche Enzyme und Reaktionen sowohl im Trainings‑ als auch im Testsatz vorkommen – erreichte PMAK die Leistung der besten bestehenden Modelle oder übertraf sie. Noch beeindruckender zeigte sich das Modell in „Cold‑Start“‑Tests, in denen entweder das Enzym oder die Reaktion im Testsatz zuvor nie vorkam: Hier übertraf PMAK eine Reihe führender Methoden. Es blieb nützlich selbst für Enzyme mit sehr geringer Sequenzähnlichkeit zu den Trainingsdaten und für Reaktionen, die sich deutlich von denen unterschieden, aus denen das Modell gelernt hatte. PMAK verbesserte zudem Vorhersagen in realistischen Anwendungen, etwa bei der Abschätzung, wie Zellen ihre begrenzten Proteinressourcen aufteilen, und bei der Prognose der Auswirkungen von Mutationen in Datensätzen zum Enzym‑Engineering.
Was das für Biologie und Biotechnologie bedeutet
Für Nicht‑Spezialisten lässt sich PMAK als ein intelligenter Assistent ansehen, der aus riesigen Protein‑ und Reaktions„bibliotheken“ lernt, um abzuschätzen, wie schnell ein gegebenes Enzym in einer bestimmten Reaktion arbeitet — und um zu erklären, welche Aminosäuren dieses Verhalten antreiben. Durch die Kombination höherer Genauigkeit mit Einsicht auf Reste‑Ebene kann dieser Ansatz Forschenden helfen, bessere Enzyme zu entwerfen, verlässlichere Stoffwechselmodelle zu bauen und zu untersuchen, wie Mutationen die Funktion beeinflussen, ohne jedes Experiment im Labor durchführen zu müssen. Wenn ähnliche Modelle auf andere kinetische Eigenschaften ausgeweitet werden, könnten sie zu wichtigen Werkzeugen für die Entwicklung saubererer Industrieprozesse, die Optimierung von Mikroben für nachhaltige Produktion und ein tieferes Verständnis dafür werden, wie die molekularen Maschinen des Lebens ihre bemerkenswerte Geschwindigkeit erreichen.
Zitation: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Schlüsselwörter: Enzymkinetik, Tiefenlernen, kcat‑Vorhersage, Protein‑Engineering, Stoffwechselmodellierung