Clear Sky Science · de
Definition operativer Sicherheit in klinischen KI-Systemen
Warum sichere KI in der Medizin wichtig ist
Krankenhäuser führen schnell künstliche Intelligenz ein, um Bildbefunde zu lesen und Krankheiten zu markieren, doch eine Frage können gewöhnliche Genauigkeitswerte nicht beantworten: Wann ist es tatsächlich sicher, der Maschine die Entscheidung zu überlassen? Dieses Papier stellt eine praxisnahe Methode vor, mit der entschieden werden kann, wann Ärztinnen und Ärzte einer KI vertrauensvoll folgen können, wann sie sie ignorieren sollten und wann sie selbst genauer hinschauen müssen. Ziel ist es nicht nur, intelligentere Algorithmen zu entwickeln, sondern sie so in die tägliche Versorgung einzubetten, dass Patientinnen und Patienten geschützt werden, unnötige Untersuchungen reduziert werden und die Arbeitslast für Kliniker sinkt statt zu steigen.
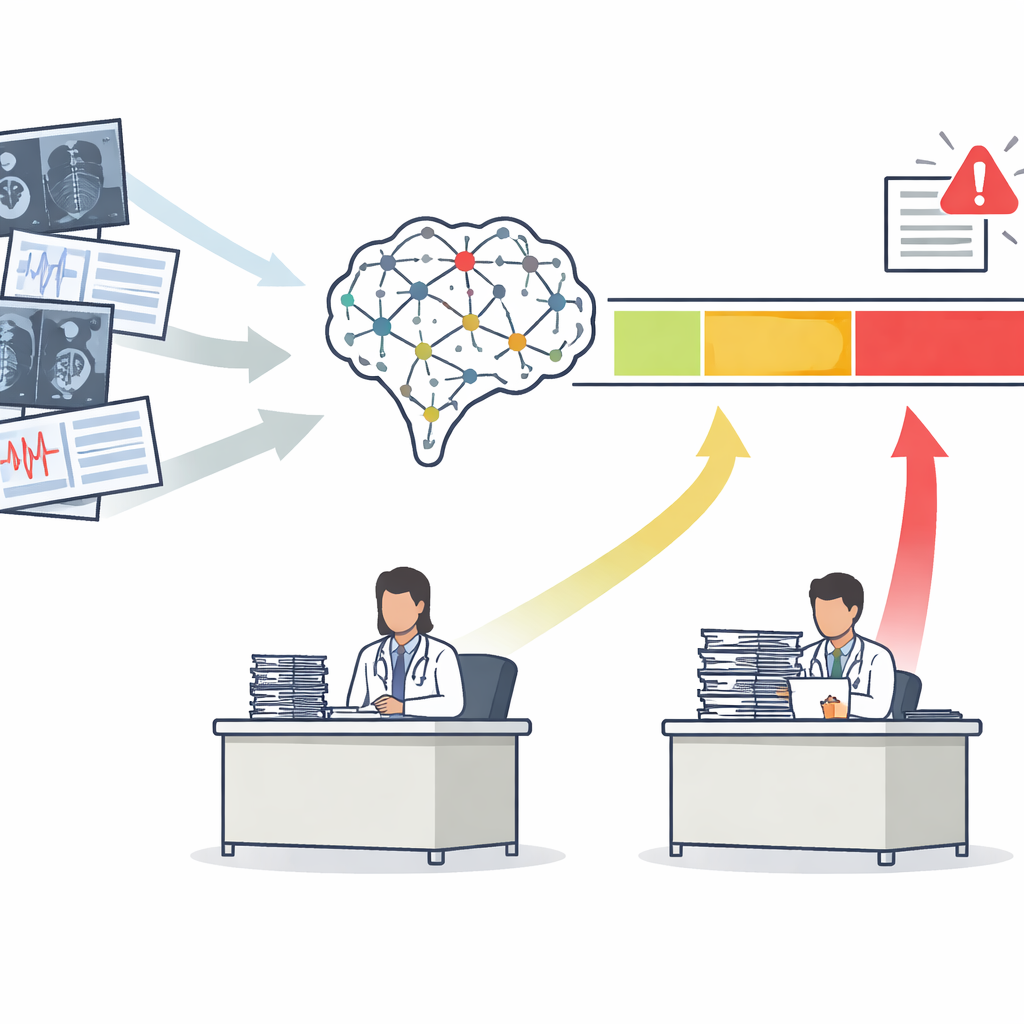
Von einer Kennzahl zu drei klaren Handlungszonen
Die meisten medizinischen KI‑Werkzeuge liefern eine einzige Risikobewertung, etwa die Wahrscheinlichkeit, dass eine Mammographie Krebs zeigt. Üblicherweise bewerten Entwickler diese Werkzeuge mit einer Kurve, die zusammenfasst, wie gut sie Kranke von Gesunden insgesamt trennen. Die Autorinnen und Autoren argumentieren, dass das nicht ausreicht. Sie schlagen den Safety-Aware ROC (SA-ROC)-Rahmen vor, der mit denselben Risikowerten beginnt, diese aber in drei praktische Bereiche umformt. Eine hochbewertete „rule-in“-Zone enthält Patientinnen und Patienten, deren Befunde zuverlässig genug sind, um Maßnahmen wie dringende Nachverfolgung auszulösen. Eine niedrig bewertete „rule-out“-Zone enthält Patientinnen und Patienten, deren Befunde zuverlässig genug sind, um sie sicher zurückzustellen. Dazwischen liegt eine „graue Zone“ der Unsicherheit, in der die KI nicht vertrauenswürdig genug ist und ein menschlicher Experte den Fall prüfen muss.
Ärztinnen und Ärzte legen die Sicherheitsanforderung fest
Entscheidend ist, dass SA-ROC Kliniker und Institutionen erlaubt, ihre eigenen Sicherheitsziele vorab zu definieren. Sie wählen, wie sicher sie vor einer Handlung bei einem positiven Ergebnis sein wollen (die minimale akzeptable Wahrscheinlichkeit, dass ein markierter Befund tatsächlich abnormal ist) und wie sicher sie bei einem negativen Ergebnis sein wollen (die minimale akzeptable Wahrscheinlichkeit, dass ein als unauffällig eingestufter Fall tatsächlich normal ist). Ausgehend von diesen Zielen durchsucht der Rahmen die Modellwerte, um die genauen Grenzen zu finden, die sie erfüllen. Werte oberhalb der oberen Grenze bilden die rule-in‑Sicherheitszone, Werte unterhalb der unteren Grenze die rule-out‑Sicherheitszone, und alles Dazwischen wird zur grauen Zone. Der Rahmen quantifiziert dann, wie viele Patientinnen und Patienten in jedem Bereich landen und wie viel unsichere Arbeitslast — Fälle, die an Menschen zurückgegeben werden — die KI ungelöst lässt.
Verborgene Unterschiede zwischen ähnlichen KIs aufdecken
Die Autorinnen und Autoren zeigen, dass zwei KI‑Systeme mit nahezu identischer traditioneller Genauigkeit sehr unterschiedlich funktionieren können, wenn man sie durch diese Sicherheitsbrille betrachtet. In Simulationen erzeugten Modelle mit derselben Gesamtleistung sehr unterschiedliche Größen für rule-in-, rule-out- und graue Zonen, abhängig davon, wie ihre Scores verteilt waren. Das eine konnte besonders gut Krankheit mit hoher Sicherheit bestätigen, das andere war besonders gut darin, große Mengen von Niedrigrisiko‑Patienten sicher freizugeben. In einer realen Fallstudie zweier von der US Food and Drug Administration zugelassener Werkzeuge zur Brustkrebsfrüherkennung war das System mit dem höheren Standard‑Genauigkeitswert tatsächlich schlechter für hochsichere Screenings. Bei der strengsten Sicherheitseinstellung — keine verpassten Krebserkrankungen in der Niedrigrisikogruppe — entfernte das vermeintlich schwächere System nahezu doppelt so viele Frauen sicher aus der Radiologenwarteschlange. SA-ROC legt damit eine Art „Leistungsumkehr“ offen, die konventionelle Metriken verschleiern.
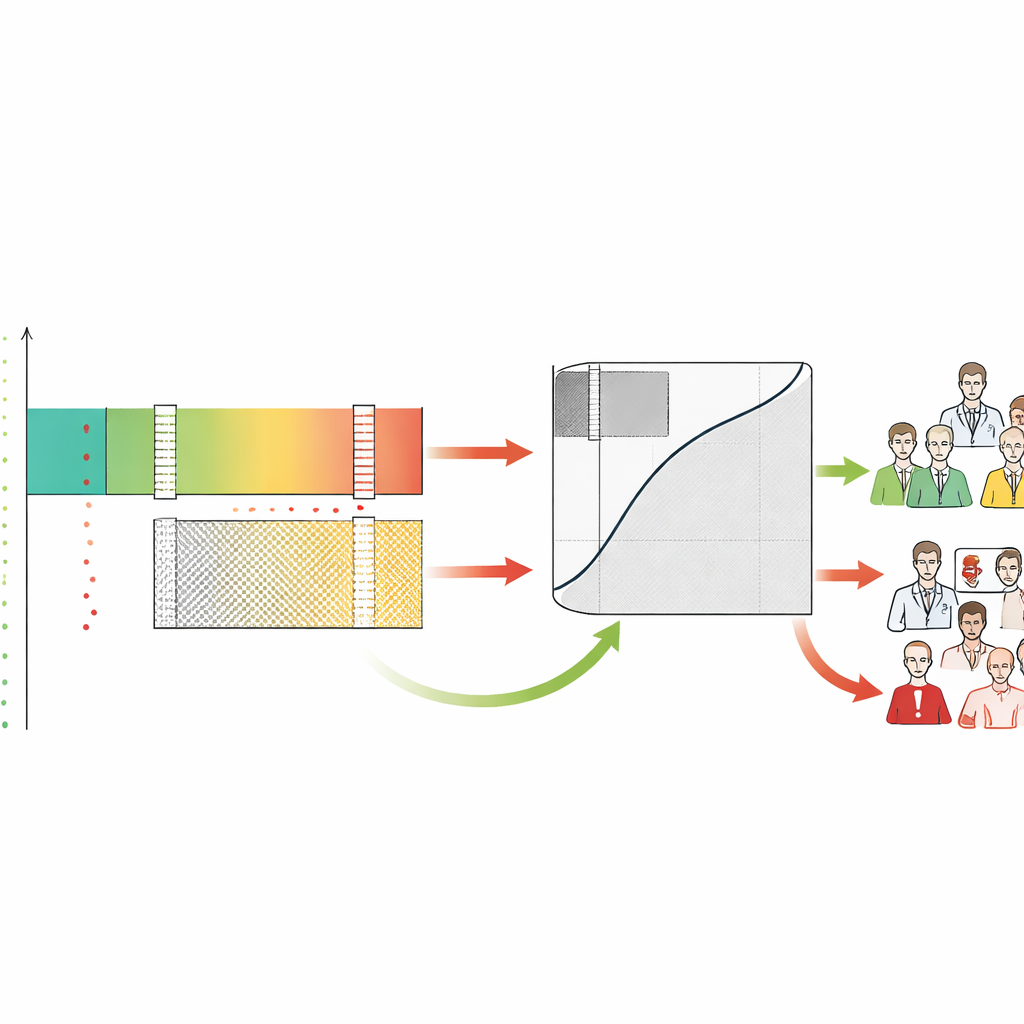
Spannung zwischen Mensch und KI sowie Arbeitslast verstehen
Indem jeder Fall als rule-in, rule-out oder grau etikettiert wird, zeigt der Rahmen auch, wie menschliche Ärztinnen und Ärzte sich in diesen Zonen verhalten. Die Autorinnen und Autoren fanden heraus, dass Radiologinnen und Radiologen Fälle, die die KI als sicher niedrig einschätzte, häufig überdiagnostizierten und viele Fehlalarme erzeugten — gerade in jenem Bereich, in dem die Maschine am zuverlässigsten war. Im Gegensatz dazu hatten sowohl Menschen als auch KI in der grauen Zone Probleme, was diese als den Bereich bestätigt, der wirklich Expertenaufmerksamkeit benötigt. SA-ROC fasst die Größe dieser grauen Zone in einer einzigen Zahl zusammen, die die Kosten der Unentschlossenheit repräsentiert. Eine kleine graue Zone bedeutet mehr sichere Automatisierung und weniger menschliche Arbeitslast; eine große graue Zone bedeutet, dass viele Fälle weiterhin sorgfältige manuelle Prüfung erfordern und das System eher zu erhöhter Belastung als zu Entlastung führen kann.
Sicherheitsregeln in den Alltag überführen
Über die Messung hinaus ist der Rahmen als Governance‑Werkzeug gedacht, das Richtlinien in konkretes KI‑Verhalten überführt. Krankenhäuser können ihn auf zwei Arten nutzen. Erstens können sie Sicherheitsanforderungen oder Limits dafür vorgeben, wie viele Fälle sie bereit sind, in die graue Zone zu senden, und den Rahmen die entsprechenden Schwellen berechnen lassen. Zweitens können sie Werte und Strafen für unterschiedliche Ergebnisse zuweisen — einen Krebs entdecken, einen übersehen, eine unnötige Untersuchung veranlassen oder an menschliche Prüfung verweisen — und den Rahmen nach der Politik suchen lassen, die den Gesamtnutzen maximiert. Diese Strategien lassen sich für sehr unterschiedliche Ziele anpassen, etwa Massen‑Screening‑Programme, Fachüberweisungen oder Forschungskohorten, alle basierend auf demselben zugrunde liegenden Modell.
Was das für Patientinnen, Patienten und Kliniker bedeutet
Einfach ausgedrückt bietet diese Arbeit eine Möglichkeit zu sagen: nicht nur „diese KI ist genau“, sondern „hier ist genau, wann und wie man ihr in der Klinik vertrauen kann“. Indem KI‑Ausgaben in sichere, unsichere und unklare Bereiche gegliedert werden, die an explizite Sicherheitsversprechen gebunden sind, hilft SA-ROC Gesundheitssystemen zu entscheiden, wann Maschinen eigenständig handeln dürfen und wann Menschen klar die Kontrolle behalten müssen. Es wird deutlich, dass traditionelle Genauigkeitswerte täuschen können und echte Sicherheit davon abhängt, wie sich ein Modell an den Extremen verhält, an denen Fehler am teuersten sind. Wenn dieses Framework breit übernommen und in größeren, realen Settings validiert wird, könnte es zuverlässigere Automatisierung fördern, unnötige Alarmierungen und Tests reduzieren und die schwierigsten KI‑Fälle — die graue Zone — zu einer fokussierten Quelle des Lernens und der Verbesserung für sowohl Algorithmen als auch die Medizin selbst machen.
Zitation: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Schlüsselwörter: klinische künstliche Intelligenz, operative Sicherheit, medizinische Bildgebung, Entscheidungsunterstützung, Risikostratifizierung