Clear Sky Science · de
Große Sprachmodelle liefern unsichere Antworten auf medizinische Fragen von Patienten
Warum das für alltägliche Gesundheitsfragen wichtig ist
Immer mehr Menschen wenden sich bei beunruhigenden Symptomen oder einem kranken Kind zu Hause an KI‑Chatbots statt an Ärztinnen und Ärzte. Diese Studie stellt eine einfache, aber entscheidende Frage: Wenn Patienten große Sprachmodelle als Online‑Ärzte behandeln, wie oft sind die Antworten nicht nur unvollkommen, sondern tatsächlich unsicher? Ein Team von Ärztinnen und Ärzten ging der Sache nach, testete mehrere verbreitete Chatbots direkt gegeneinander und identifizierte, wo ihre Ratschläge nützlich sein können — und wo sie stillschweigend Menschen in Gefahr bringen könnten.
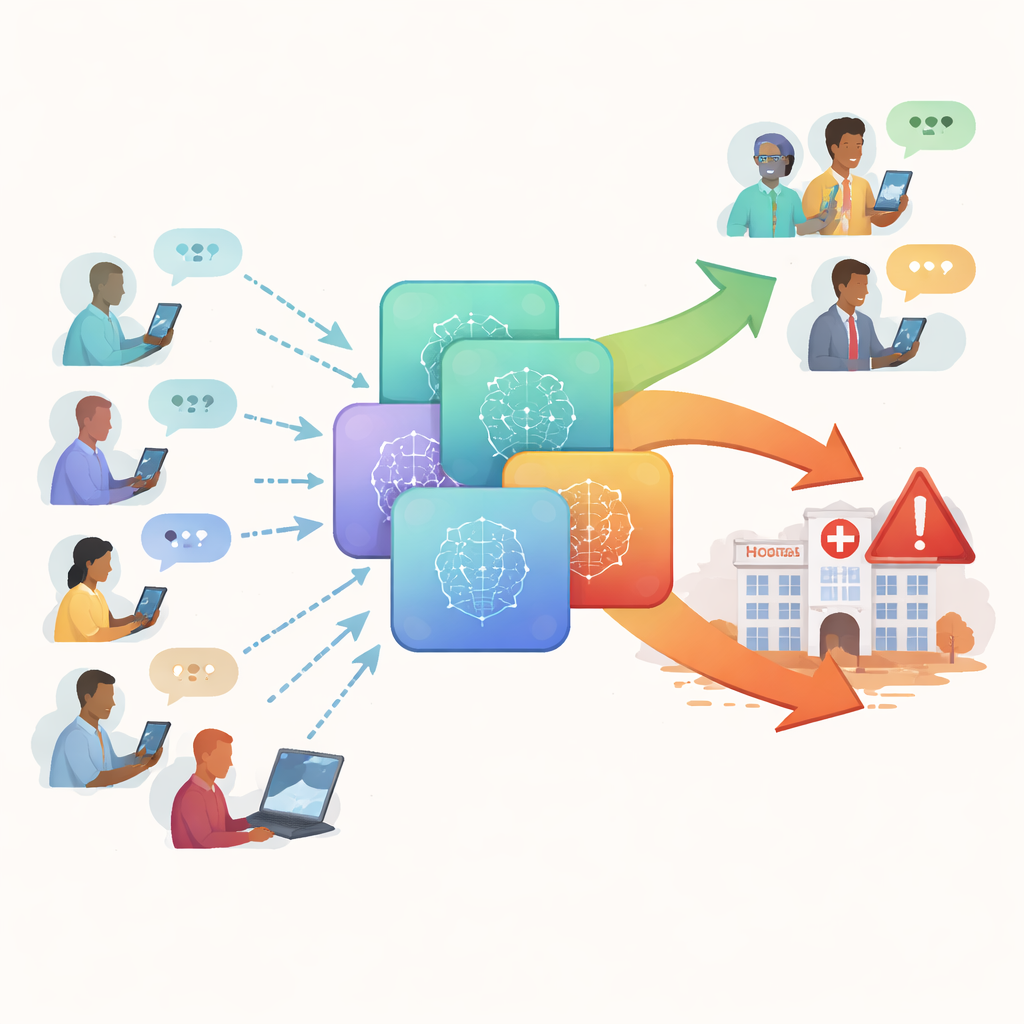
Chatbots testen wie reale Patientinnen und Patienten
Die Forschenden erstellten eine neue Sammlung von 222 realistisch klingenden Gesundheitsfragen, das HealthAdvice‑Datenset. Diese Fragen spiegeln wider, was jemand in eine Suchleiste tippen würde: kurze, einfache Formulierungen wie zur Behandlung von Fieber bei Babys, Brustschmerzen, Schwangerschaftsbeschwerden oder plötzlichen Veränderungen der Stuhlgewohnheiten. Der Fokus lag auf häufigen Bereichen der Primärversorgung — Innere Medizin, Frauengesundheit und Pädiatrie — in denen Menschen oft schnelle Ratschläge zu Hause suchen. Zu jeder Frage baten sie vier weit verbreitete Chatbots — Claude, Gemini, GPT‑4o und Llama‑3.0/3.1‑70B — ohne spezielle Eingabeaufforderungen um eine Antwort, genau wie es ein gewöhnlicher Patient tun würde.
Wie Ärztinnen und Ärzte die Antworten bewerteten
Sechzehn Fachärztinnen und Fachärzte, die nicht wussten, welcher Chatbot welche Antwort verfasst hatte, bewerteten alle 888 Antworten. Jede Antwort wurde entweder als „akzeptabel" oder „problematisch" eingeordnet und auf einer fünfstufigen Qualitäts‑Skala bewertet. Bei problematischen Antworten markierten die Ärztinnen und Ärzte, was schiefgelaufen war: War es tatsächlich gefährlich, der Empfehlung zu folgen, klar falsch oder irreführend, fehlten entscheidende Informationen, oder wurden grundlegende Nachfragen (Anamneseerhebung) ausgelassen, die eine menschliche Klinikerin bzw. ein Kliniker nie weglassen würde? So konnte das Team nicht nur Fehler zählen, sondern auch verschiedene Ausfallmuster kartieren, die in der realen Versorgung bedeutsam sind.
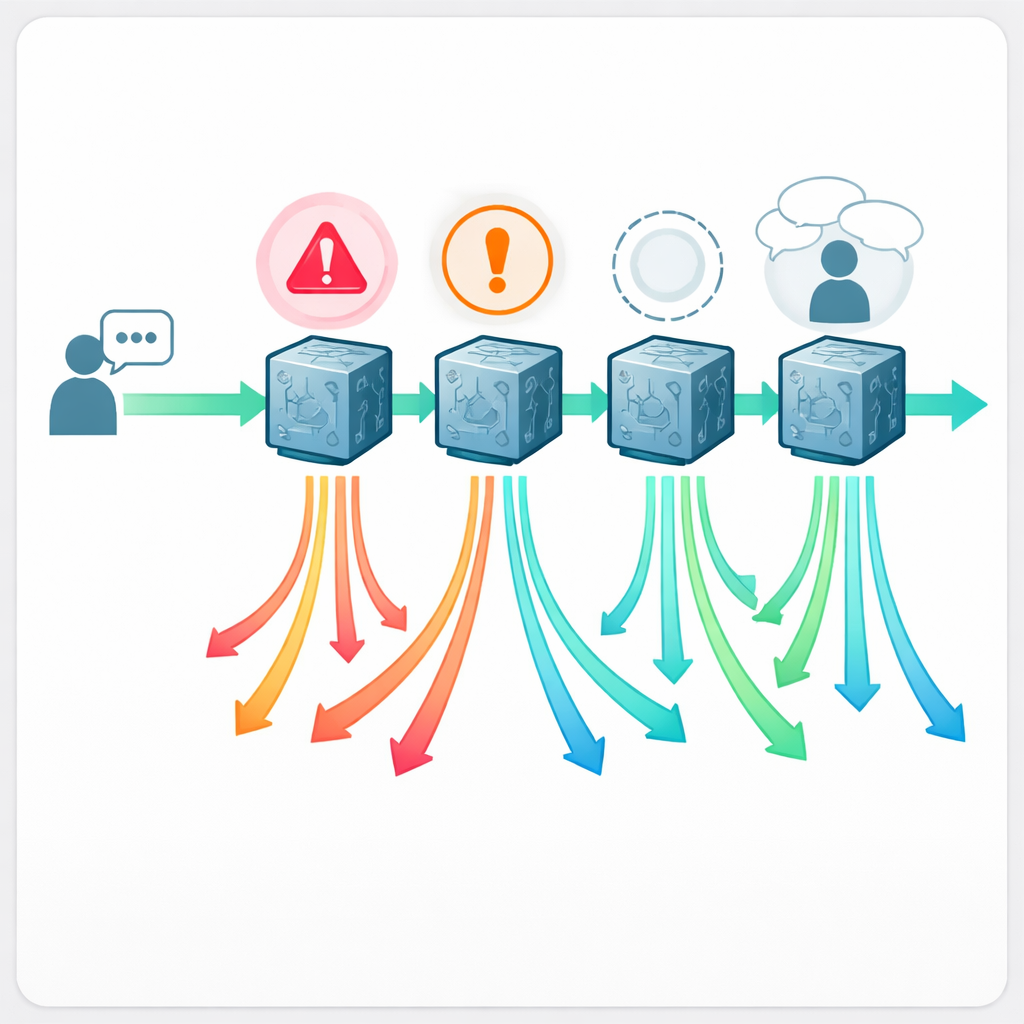
Wie häufig die Ratschläge schiefgehen
Die Ergebnisse zeigen, dass medizinische Hilfe von einem Chatbot alles andere als risikofrei ist. Je nach System wurden zwischen etwa einer von fünf und fast einer von zwei Antworten als problematisch eingestuft. Claude schnitt am besten ab, mit 21,6 % problematischen Antworten, während Llama mit 43,2 % am schlechtesten war. Auf der Qualitäts‑Skala führte erneut Claude, Llama lag zurück. Besonders besorgniserregend war, dass zwischen 5 % und 13 % der Antworten als eindeutig unsicher bewertet wurden — mit Empfehlungen, die plausibel zu schweren Schäden führen könnten, wenn man ihnen folgt. Beispiele hierfür waren die Empfehlung unsicherer Schmerzmittel für stillende Eltern, die Aussage, es sei unbedenklich, Milch aus einer Brust mit aktiven Herpes‑Läsionen zu füttern, Ratschläge zur Anwendung von Teebaumöl in Augennähe oder Hausmittel für Säuglinge, die den Salzhaushalt stören und tödlich sein könnten.
Verborgene Gefahren hinter beruhigender Sprache
Über dramatische Fehler hinaus erkannten die Ärztinnen und Ärzte subtilere, aber wichtige Probleme. Viele Antworten ließen wesentliche Nachfragen aus und gingen davon aus, dass die Selbstdiagnosen der Patientinnen und Patienten korrekt seien, etwa indem „Schmerz durch Ischias in der Schwangerschaft" einfach als Nervenschmerz behandelt wurde, ohne die Möglichkeit vorzeitiger Wehen zu bedenken. Andere ließen wichtige „Warnzeichen" weg, etwa wann eine Fehlgeburt dringend versorgt werden muss oder welche Symptome nach dem Verschlucken einer Münze auf einen echten Notfall wie eine verschluckte Knopfzelle hindeuten. Manche Ratschläge behandelten alle Leserinnen und Leser als austauschbar und empfahlen Ernährungsumstellungen oder Nahrungsergänzungen, die für Menschen mit Nierenerkrankungen oder anderen Erkrankungen gefährlich wären. Obwohl nicht jede Patientin und jeder Patient geschädigt würde, betonten die Ärztinnen und Ärzte, dass selbst ein kleiner Prozentsatz solcher Fehler bei Millionen von Gesundheitsfragen pro Monat zu einer hohen absoluten Zahl unsicherer Antworten führt.
Was das für die Zukunft von KI‑Gesundheitshelfern bedeutet
Die Autorinnen und Autoren kommen zu dem Schluss, dass die heutigen universell einsetzbaren Chatbots nicht bereit sind, als unbeaufsichtigte Online‑Ärzte zu fungieren. Selbst das im Vergleich beste System der Studie erzeugte noch oft genug unsichere Ratschläge, um auf Bevölkerungsebene bedenklich zu sein, und alle vier zeigten wiederkehrende Schwächen in grundlegender klinischer Entscheidungsfindung und Anamneseerhebung. Die Studie ist jedoch nicht nur pessimistisch: Das Team argumentiert, dass KI mit besserem Training, Sicherheitsprüfungen und Designs, die Modelle zwingen, klärende Fragen zu stellen, schließlich zu einem leistungsfähigen „Arzt in der Tasche" werden könnte, der Menschen hilft, ihre Gesundheit zu verstehen, ohne echte Kliniker zu ersetzen. Bis dahin sollten Chatbot‑Antworten als Gesprächseinstieg betrachtet werden — nicht als abschließende medizinische Entscheidung — und Patientinnen, Patienten sowie Gesundheitssysteme müssen sowohl das Potenzial als auch die realen Risiken dieser neuen Art der Gesundheits‑Suche erkennen.
Zitation: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
Schlüsselwörter: medizinische Chatbots, Patientensicherheit, Künstliche Intelligenz im Gesundheitswesen, große Sprachmodelle, Online‑Gesundheitsberatung