Clear Sky Science · de
Ein schwach überwachter Transformer zur Diagnose seltener Erkrankungen und Subphänotypisierung aus elektronischen Gesundheitsakten mit pulmonalen Fallstudien
Warum eine schnellere Erkennung seltener Erkrankungen wichtig ist
Für Familien mit seltenen Krankheiten kann es Jahre dauern, bis die Ursache benannt wird. Die Symptome sind häufig unspezifisch, Ärztinnen und Ärzte sehen im Leben oft nur wenige solcher Fälle, und vorhandene Tests liefern nicht immer eindeutige Ergebnisse. Diese Studie untersucht einen neuen Weg, die digitalen Spuren in elektronischen Gesundheitsakten zu nutzen, um zwei schwer zu diagnostizierende Lungenerkrankungen früher zu erkennen und Patienten in Gruppen zu unterteilen, die sehr unterschiedliche Verlaufsrisiken haben können.
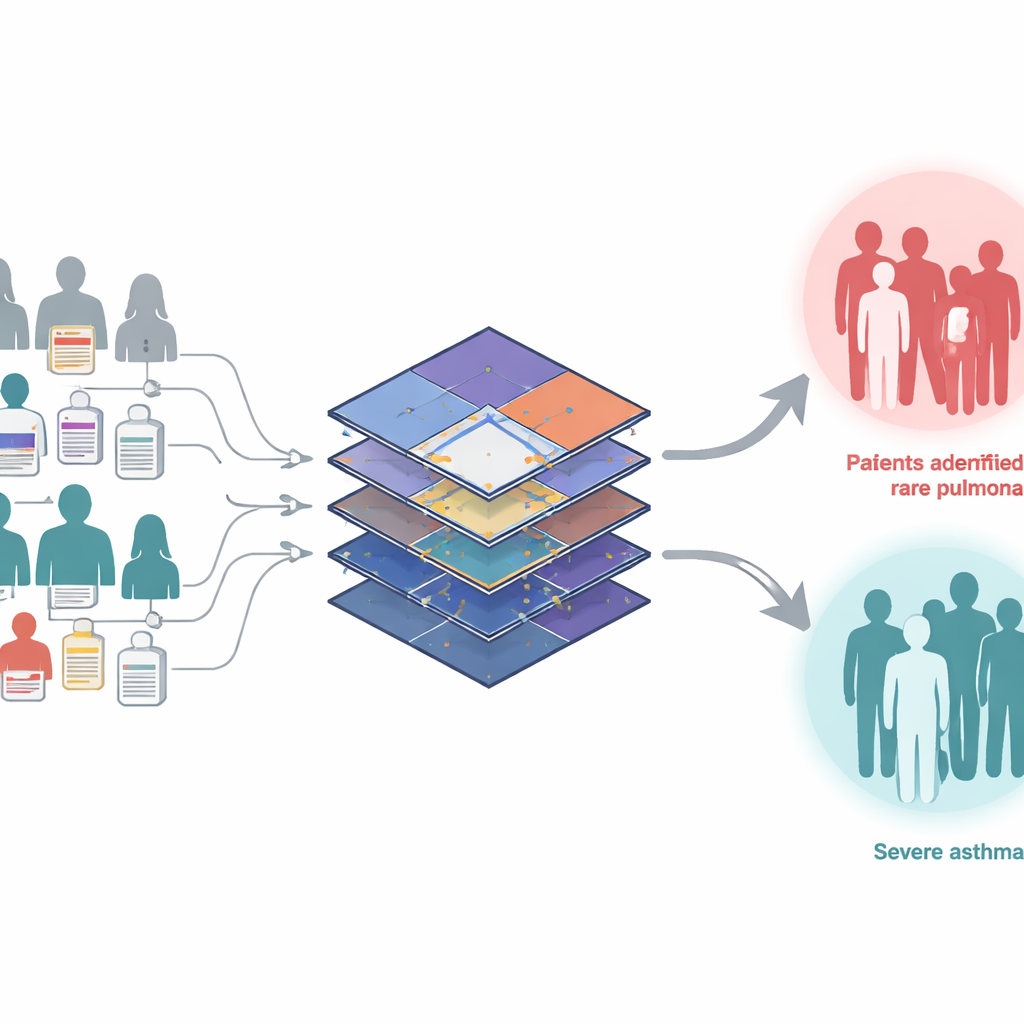
Der lange Weg zur seltenen Diagnose
Seltenerkrankungen sind einzeln selten, zusammen betreffen sie jedoch weltweit Hunderte Millionen Menschen. Viele beginnen im Kindesalter und können lebensbedrohlich sein, wenn sie übersehen werden. Der Artikel konzentriert sich auf seltene Lungenerkrankungen, bei denen alltägliche Beschwerden wie Atemnot oder Keuchen leicht für Asthma oder andere häufige Probleme gehalten werden können. In der Folge sehen Kinder mit Erkrankungen wie pulmonaler Hypertonie oder schweren Formen von Asthma oft viele Spezialistinnen und Spezialisten und warten Jahre auf die richtige Diagnose, wodurch wertvolle Zeit verloren geht, in der eine frühe Behandlung den Krankheitsverlauf verändern könnte.
Chaotische Krankenakten in Hinweise verwandeln
Moderne Krankenhäuser speichern riesige Mengen an Informationen in elektronischen Gesundheitsakten – von Diagnosecodes und Verordnungen bis hin zu Laborwerten und Arztberichten. In diesen Daten verbergen sich Muster, die auf eine seltene Krankheit lange bevor sie offiziell benannt ist, hinweisen können. Es gibt jedoch einen Haken: Nur ein kleiner Bruchteil der Patienten wurde von Expertinnen und Experten genau überprüft, sodass hochwertige Labels, die sicher angeben, wer wirklich erkrankt ist, knapp sind. Die meisten Aufzeichnungen liefern nur grobe, „rauschende“ Signale – Codes, die Abrechnungsgewohnheiten, vorläufige Vermutungen oder veraltete Einträge widerspiegeln können. Herkömmliche Computermodelle tun sich in diesem Umfeld schwer, weil sie darauf ausgelegt sind, aus großen Sammlungen sauberer, vertrauenswürdiger Beispiele zu lernen.
Ein neuer Weg, aus unvollkommenen Daten zu lernen
Die Autorinnen und Autoren stellen WEST vor, einen „schwach überwachten Transformer“, der dafür entworfen ist, aus dieser Mischung aus wenigen genauen Labels und vielen unsicheren zu lernen. Das System beginnt mit zwei Patientengruppen am Boston Children’s Hospital, die möglicherweise pulmonale Hypertonie oder schweres Asthma haben, identifiziert durch breit angelegte Screening‑Codes. Innerhalb jeder Gruppe wurde ein kleiner Teil von Spezialistinnen und Spezialisten bestätigt, während der Rest probabilistische Scores aus früheren, regelbasierten Werkzeugen erhält. WEST verwendet einen Transformer – eine fortschrittliche Mustererkennungsarchitektur, die ursprünglich für Sprache entwickelt wurde –, um die gesamte Krankengeschichte jedes Kindes in ein kompaktes numerisches Porträt zu verwandeln. Entscheidend ist, dass es die groben Labels nicht als endgültige Wahrheit behandelt: Nach jedem Trainingsdurchgang aktualisiert das Modell seine eigenen Schätzungen, wer wahrscheinlich krank ist, und speist diese verfeinerten Wahrscheinlichkeiten in die nächste Runde zurück, wodurch das Signal schrittweise bereinigt wird.
Was das Modell bei Lungenerkrankungen entdeckte
Getestet an zurückbehaltenen, von Experten validierten Patienten war WEST genauer als mehrere Alternativen, darunter einfache Code‑Zählregeln, gradientenverstärkte Bäume und Transformer, die entweder die verrauschten Labels ignorierten oder sie als bare Münze akzeptierten. Es benötigte erstaunlich wenige Goldstandard‑Fälle, um gute Leistung zu erzielen – etwa 100 sorgfältig geprüfte Patienten reichten aus, um andere Ansätze zu erreichen oder zu übertreffen. Über die reine Vorhersage, wer wahrscheinlich die jeweilige Erkrankung hat, hinaus gruppierten die internen Repräsentationen des Modells Kinder auf natürliche Weise in klinisch sinnvolle Cluster. Für die pulmonale Hypertonie trennte WEST die Patienten in eine langsam voranschreitende und eine schnell voranschreitende Gruppe, die über fünf Jahre deutlich unterschiedliche Überlebensmuster zeigten. Für das schwere Asthma unterteilte es Patienten in solche mit häufigen, gefährlichen Exazerbationen und solche mit vergleichsweise weniger Anfällen, was sich in Unterschieden bei Krankenhausaufenthalten, Hypoxie‑Episoden und respiratorischem Versagen widerspiegelte.
Wie sich die Versorgung von Patienten dadurch ändern könnte
Für Nicht‑Fachleute ist die Kernbotschaft, dass WEST lernt, komplexe Krankheitsmuster in routinemäßigen Krankenhausdaten „zu sehen“, ohne auf riesige, perfekt gelabelte Datensätze angewiesen zu sein. Durch das clevere Wiederverwenden unvollkommener Signale und einer kleinen Menge Experteninput kann es wahrscheinliche Fälle seltener Erkrankungen genauer markieren und verborgene Untergruppen aufdecken, die unterschiedliche Risiken tragen. Langfristig könnten Systeme wie WEST dazu beitragen, die diagnostische Odyssee für Kinder mit seltenen Lungenerkrankungen zu verkürzen, Ärztinnen und Ärzte zu früheren Überweisungen an Spezialisten zu leiten und eine gezieltere Überwachung und Behandlung zu unterstützen, abgestimmt auf den voraussichtlichen Krankheitsverlauf eines Patienten.
Zitation: Greco, K.F., Yang, Z., Li, M. et al. A weakly supervised transformer for rare disease diagnosis and subphenotyping from EHRs with pulmonary case studies. npj Digit. Med. 9, 211 (2026). https://doi.org/10.1038/s41746-026-02406-x
Schlüsselwörter: Diagnose seltener Erkrankungen, elektronische Gesundheitsakten, Maschinelles Lernen in der Medizin, pulmonale Hypertonie, schweres Asthma