Clear Sky Science · de
Groß angelegtes selbstüberwachtes Video-Grundlagenmodell für intelligente Chirurgie
Intelligentere Unterstützung im Operationssaal
Moderne Chirurgen verlassen sich zunehmend auf Kameras und Computer, um ihre Arbeit zu steuern, doch die heutige künstliche Intelligenz hat noch Schwierigkeiten, vollständig zu erfassen, was während einer Operation geschieht. Dieses Papier stellt eine neue Methode vor, KI mit Tausenden von Operationsvideos zu trainieren, damit sie Abläufe besser verfolgen, Instrumente und Gewebe erkennen und beurteilen kann, wie sicher und fachgerecht die Operation voranschreitet. Langfristig könnte eine solche Technologie Chirurgen in Echtzeit unterstützen, die Ausbildung verbessern und die Chirurgie für Patientinnen und Patienten sicherer machen.
Warum das Lehren von Maschinen über Chirurgie schwierig ist
Computern Chirurgie beizubringen ist nicht so einfach wie ihnen ein paar beschriftete Bilder zu geben. Jede Prozedur beinhaltet bewegte Kameras, wechselnde Blickwinkel, Rauch, Blut sowie Hände und Werkzeuge, die einander ständig verdecken. Hinzu kommen Tausende unterschiedlicher Operationsarten, von denen viele selten sind. Eine sorgfältige Frame-für-Frame-Beschriftung von Videodaten erfordert knappe Expertenzeit und wird schnell zu teuer. Frühere KI-Systeme versuchten, diese Last mit Methoden zu mindern, die aus unlabeled Bildern lernen, betrachteten dabei aber meist nur Standbilder und ergänzten erst später ein Zeitverständnis. Dadurch verpassten sie oft die sich entfaltende Geschichte einer Operation: was zuvor geschah, was jetzt passiert und was wahrscheinlich als Nächstes folgt.
Direktes Lernen aus chirurgischen Filmen
Die Autoren argumentieren, dass eine KI, die in der Chirurgie assistieren soll, besser auf Videos statt auf isolierten Bildern trainiert werden sollte. Dazu stellten sie eine der bisher umfangreichsten Sammlungen endoskopischer OP-Videos zusammen: 3.650 Aufzeichnungen mit 3,55 Millionen Frames, entnommen aus öffentlichen Forschungsdatensätzen und einer breiten Auswahl online verfügbarer chirurgischer Aufnahmen. Diese Videos decken mehr als 20 Arten von Eingriffen und über 10 anatomische Regionen ab, von Gallenblasenentfernung bis zu Leber- und gynäkologischen Operationen. Diese Vielfalt erlaubt es der KI, viele Erscheinungsformen eines Eingriffs im realen Leben zu sehen, einschließlich unterschiedlicher Krankenhäuser, Instrumente und Kamerastile.
Ein neues, videozentriertes Lernkonzept
Aufbauend auf diesem Datenschatz entwarf das Team SurgVISTA, ein „Foundation Model“, das speziell auf OP-Videos abgestimmt ist. Anstatt zu versuchen, jeden Frame zu beschriften, lernt SurgVISTA, fehlende Inhalte zu ergänzen. Während des Trainings werden Teile jedes Videoclips verborgen, und das Modell muss die fehlenden Bereiche rekonstruieren. Das zwingt es dazu, darauf zu achten, wie Gewebe, Instrumente und Bewegungen sich über die Zeit verändern. Gleichzeitig lernt ein zweiter Zweig des Systems, die detaillierten visuellen Hinweise eines starken bildbasierten Expertenmodells nachzuahmen, das bereits viel über chirurgische Szenen weiß. Diese Kombination hilft SurgVISTA, sowohl die feinen Details innerhalb einzelner Frames als auch den größeren Fluss der gesamten Operation zu erfassen — und das in einem einzigen, vereinheitlichten Netzwerk.
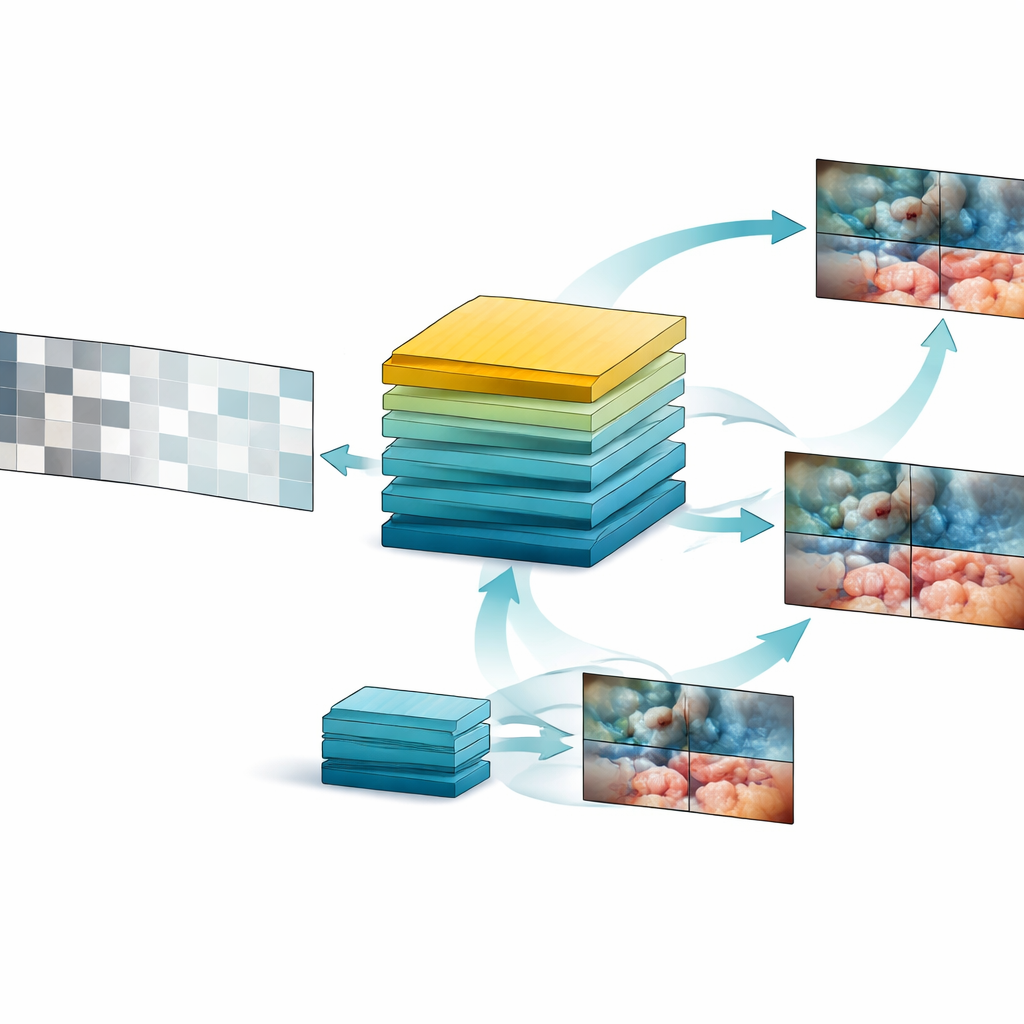
Der Modelltest
Um zu prüfen, ob sich dieser Ansatz wirklich auszahlt, testeten die Autoren SurgVISTA auf 13 verschiedenen Datensätzen, die sechs OP-Typen und vier praktische Aufgaben abdeckten. Zu diesen Aufgaben gehörten die Erkennung, in welcher Phase sich ein Eingriff befindet, die Identifikation spezifischer chirurgischer Handlungen, das Erfassen der Dreierbeziehung zwischen Instrument, Aktion und Zielgewebe sowie die Beurteilung, wie sicher zentrale Schritte ausgeführt wurden. In allen Bereichen übertraf SurgVISTA führende Modelle, die auf Alltagsvideos trainiert waren, sowie die besten bisher verfügbaren, auf Standbildern basierenden chirurgischen Systeme. Es zeigte starke Leistungen selbst bei Verfahren, die es während des Trainings nie gesehen hatte, was darauf hinweist, dass die gelernten Muster nicht an ein einzelnes Organ, Set an Instrumenten oder Krankenhaus gebunden sind.
Warum mehr und reichhaltigere Videodaten wichtig sind
Die Studie untersuchte außerdem, wie sich die Leistung mit wachsender Datenmenge verändert. Als die Autoren die Größe und Vielfalt des Videopools schrittweise erweiterten, verbesserten sich SurgVISTAs Ergebnisse nahezu überall, auch bei Eingriffen, die im Trainingsdatensatz überhaupt nicht vorkamen. Interessanterweise profitierte das Modell nicht nur von mehr Beispielen desselben Eingriffs, sondern auch von unterschiedlichen Operationsarten: die Exposition gegenüber vielfältigen chirurgischen „Geschichten“ half ihm, allgemeine visuelle und Bewegungsmuster zu erkennen, die fachspezifisch übertragbar sind. Weitere Experimente zeigten, dass die zusätzliche Anleitung durch das bildbasierte Expertenmodell die Fähigkeit des Modells weiter schärfte, feine anatomische Details zu erhalten — entscheidend, um beispielsweise eine lebenswichtige Struktur von umgebendem Gewebe zu unterscheiden.
Was das für die Chirurgie der Zukunft bedeutet
Einfach gesagt zeigt diese Arbeit, dass eine auf großen Mengen realer OP-Videos trainierte KI, die Raum und Zeit berücksichtigt, ein deutlich tieferes Verständnis dafür entwickeln kann, was im Operationssaal geschieht. SurgVISTA ist noch kein System, das eigenständig Entscheidungen trifft, aber es liefert ein leistungsfähiges Rückgrat, an das sich andere Anwendungen anschließen können — sei es zur Verfolgung des OP-Fortschritts, zum Markieren riskanter Momente, zur Unterstützung der Ausbildung oder zum Vergleich von Techniken zwischen Kliniken. Die Autoren weisen darauf hin, dass breitere Datenbasen und klinische Erprobungen weiterhin nötig sind, doch ihre Ergebnisse legen nahe, dass videobasierte Foundation-Modelle zu einem Schlüsselbestandteil künftiger intelligenter chirurgischer Systeme werden könnten, mit dem Ziel, Eingriffe sicherer, konsistenter und besser auf einzelne Patientinnen und Patienten zugeschnitten zu machen.
Zitation: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
Schlüsselwörter: chirurgische Video-KI, selbstüberwachtes Lernen, operativer Ablauf, computerassistierte Chirurgie, raumzeitliche Modellierung