Clear Sky Science · de
Maschinelle Lernmodelle zur Vorhersage von Arzneimittelwechselwirkungen: von der computergestützten Entdeckung bis zur klinischen Anwendung
Warum die Kombination von Arzneimitteln riskant sein kann
Die moderne Medizin beruht oft darauf, mehrere Medikamente gleichzeitig einzusetzen – bei Krebs, Herzkrankheiten, Infektionen oder zur Behandlung der zahlreichen Beschwerden, die mit dem Alter auftreten. Wenn Arzneimittel aber im Körper aufeinandertreffen, können sie sich gegenseitig in ihrer Wirkung verändern und so eine Behandlung unwirksam oder sogar gefährlich machen. Dieser Übersichtsartikel untersucht, wie künstliche Intelligenz, insbesondere moderne Methoden des maschinellen Lernens, genutzt wird, um solche Arzneimittelwechselwirkungen vorab vorherzusagen, damit Ärztinnen und Ärzte sicherere Kombinationen wählen und Behandlungen individueller anpassen können.
Vom Versuch-und-Irrtum zur datengetriebenen Sicherheit
Traditionell wurden problematische Arzneimittelkombinationen auf die harte Tour entdeckt – in späten klinischen Studien oder erst, nachdem ein Medikament bereits auf dem Markt war und Patientinnen und Patienten zu Schaden kamen. Laborversuche an Zellen, Tieren und Freiwilligen bleiben der Goldstandard, sind aber langsam, teuer und lassen sich nicht auf die enorme Zahl möglicher Wirkstoffkombinationen anwenden. Die Autorinnen und Autoren argumentieren, dass rechnergestützte Vorhersagen einen Ausweg aus diesem Engpass bieten. Indem sie aus umfangreichen digitalen Sammlungen von Arzneimittelinformationen lernen – etwa chemische Strukturen, Zielmoleküle im Körper, bekannte Nebenwirkungen und Meldungen über unerwünschte Reaktionen aus der Praxis – können maschinelle Lernsysteme riskante Paare lange bevor sie viele Patientinnen und Patienten erreichen, kennzeichnen.
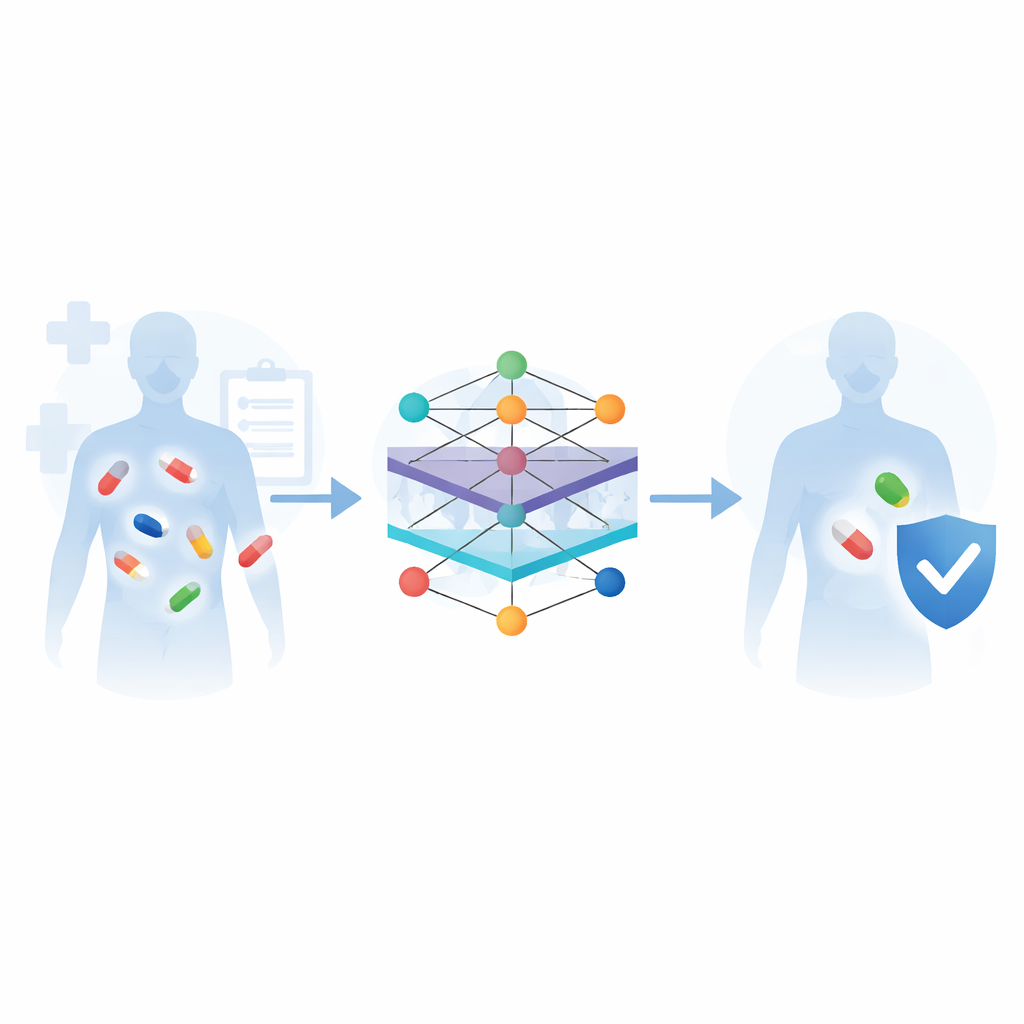
Wie Maschinen aus vielfältigen Arzneimitteldaten lernen
Die Übersicht erklärt einen typischen Arbeitsablauf für solche Vorhersagesysteme. Zuerst werden Informationen aus großen biomedizinischen Datenbanken gesammelt: chemische Bibliotheken, die beschreiben, wie jede Verbindung aufgebaut ist; Signal- und Stoffwechselwege, die zeigen, wie Medikamente im Körper verarbeitet werden; sowie kuratierte Listen bekannter Wechselwirkungen und Nebenwirkungen. Anschließend wandeln Algorithmen diese Rohdaten in numerische Muster um, die Computer verstehen können – zum Beispiel durch Messung der Ähnlichkeit zweier Wirkstoffe oder durch die Darstellung jedes Arzneimittels als Knoten in einem Netzwerk, das mit seinen Zielen, Wegen und früheren Reaktionen verknüpft ist. Verschiedene Modelle des maschinellen Lernens werden dann darauf trainiert, Muster zu erkennen, welche Wirkstoffpaare Probleme verursachen, und ihre Leistung wird anhand von Benchmark-Datensätzen mit üblichen Gütemaßen überprüft.
Verschiedene Modellfamilien gehen das Problem auf ihre Weise an
Weil Wechselwirkungen zwischen Arzneimitteln komplex sind, gibt es nicht das eine Modell, das für alle Situationen optimal ist. Einige Ansätze setzen auf traditionelle Klassifikatoren, die mit handgestalteten Merkmalen arbeiten, während andere direkt aus der Molekülstruktur oder dem Beziehungsgeflecht zwischen Arzneimitteln und biologischen Entitäten lernen. Graphbasierte und Deep-Learning-Methoden waren dabei besonders erfolgreich: Sie behandeln Medikamente und ihre Beziehungen als Netzwerk und erlauben dem Algorithmus, über Verbindungsketten zu „schließen“, die für einfachere Modelle unsichtbar bleiben könnten. Weitere Strategien teilen Informationen über verwandte Aufgaben hinweg, etwa indem sie zugleich vorhersagen, ob zwei Wirkstoffe interagieren und welche Art von Effekt sie hervorrufen – das hilft besonders bei knappen Daten. Der Beitrag hebt zudem neue Richtungen hervor, wie große Sprachmodelle, die wissenschaftliche Texte und klinische Notizen lesen, sowie generative Modelle, die mögliche Interaktionsmuster in sehr großen, dünn besetzten Datensätzen explorieren.
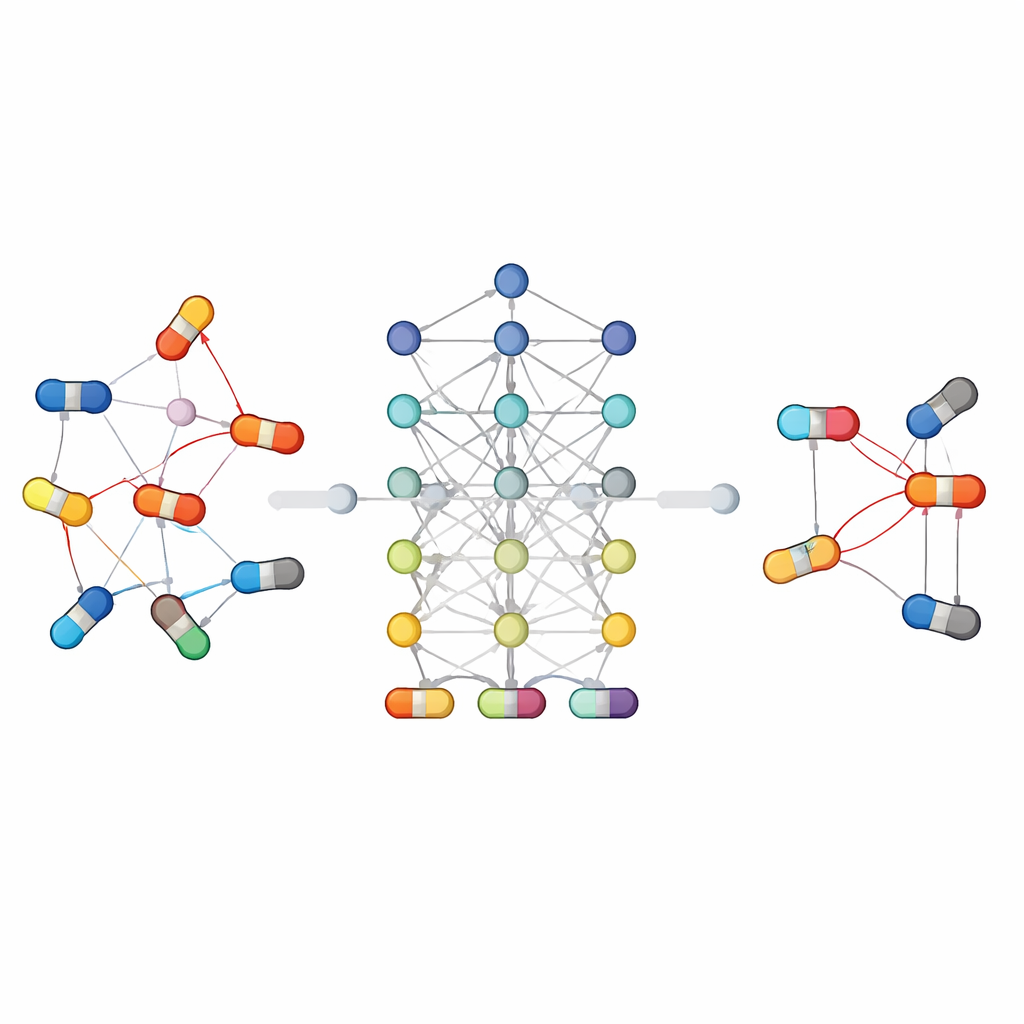
Verknüpfung von Computer-Vorhersagen mit realen Patientinnen und Patienten
Über die Methoden hinaus betont der Artikel, wie diese Werkzeuge die Versorgung in der Praxis unterstützen können. Die Autorinnen und Autoren diskutieren, wie auf kuratierten Datenbanken und klinischen Aufzeichnungen trainierte Modelle Klinikpersonal am Patientenbett vor gefährlichen Kombinationen warnen, bei der Gestaltung sichererer Mehrfachtherapien in Onkologie, Kardiologie und Infektiologie helfen und priorisieren können, welche vorhergesagten Wechselwirkungen eine Labortestung verdienen. Sie skizzieren klassische klinische Beispiele – etwa Antibiotika, die die Konzentration cholesterinsenkender Medikamente verändern, Schmerzmittel, die sich gegenseitig blockieren, oder Fruchtsäfte, die unerwartet Arzneimittelspiegel erhöhen –, um die vielen Pfade zu zeigen, über die Wechselwirkungen entstehen. Maschinelle Lernsysteme, welche diese Muster erfassen, können damit als Frühwarnsysteme dienen, besonders bei älteren Menschen, die viele Medikamente einnehmen.
Herausforderungen auf dem Weg zu vertrauenswürdiger KI für Arzneimittel
Trotz beeindruckender Genauigkeit auf Testdatensätzen betonen die Autorinnen und Autoren, dass aktuelle Modelle noch wichtige Hürden überwinden müssen, bevor sie in Kliniken breit Vertrauen genießen. Viele sind „Black Boxes“, die wenig Einblick geben, warum ein bestimmtes Paar als riskant eingestuft wird, was es Ärztinnen und Ärzten erschwert, die Empfehlung zu beurteilen oder zu erklären. Modelle können stolpern, wenn Daten verrauscht oder unausgewogen sind – etwa wenn schädliche Wechselwirkungen im Vergleich zu sicheren Paaren selten sind. Die Integration von Informationen aus Chemie, Genetik, elektronischen Gesundheitsakten und veröffentlichter Literatur ist technisch anspruchsvoll, und regulatorische Rahmenbedingungen verlangen starke Evidenz, bevor solche Werkzeuge das Verschreiben beeinflussen können. Zukünftige Arbeiten, so die Autorinnen und Autoren, müssen sich auf besser interpretierbare Modelle, einen robusteren Umgang mit verzerrten und unvollständigen Daten sowie auf Systeme konzentrieren, die kontinuierlich aus neuer klinischer Erfahrung lernen können, dabei aber Datenschutz- und Sicherheitsregeln respektieren.
Was das für die alltägliche Behandlung bedeutet
Kurz gesagt zeigt diese Übersicht, dass künstliche Intelligenz zu einem starken Verbündeten wird, um Kombinationen von Arzneimitteln sicherer zu machen. Indem sie Berge digitaler Daten durchforstet, die weit über das hinausgehen, was irgendeine menschliche Expertin oder jeder menschliche Experte bewältigen könnte, können Modelle des maschinellen Lernens gefährliche Paare hervorheben, sicherere Alternativen vorschlagen und personalisiertere Verschreibungen unterstützen. Diese Werkzeuge werden klinisches Urteilsvermögen und sorgfältige Labortests nicht ersetzen, können aber dazu beitragen, dass die wachsende Komplexität moderner Therapien nicht auf Kosten der Patientensicherheit geht.
Zitation: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Schlüsselwörter: Arzneimittelwechselwirkungen, Maschinelles Lernen in der Medizin, Graphneuronale Netze, Klinische Pharmakologie, Sicherheit künstlicher Intelligenz