Clear Sky Science · de
Bewertung großer Sprachmodelle zur Generierung diagnostischer Schlussfolgerungen aus Befunden von Gehirn‑MRT‑Berichten: ein multizentrischer Benchmark und Leser*innen‑Studie
Warum intelligentere MRT‑Berichte für Patient*innen wichtig sind
Bei einer Gehirnuntersuchung muss ein Radiologe tausende Graustufen zu einer klaren Aussage darüber verdichten, was fehlt — oder dass alles normal aussieht. Diese abschließende „Impression“ steuert entscheidende Maßnahmen bei Schlaganfall, Hirntumoren, Infektionen und mehr. Das Lesen von Gehirn‑MRTs ist jedoch komplex und zeitaufwendig, und überlastete Ärztinnen und Ärzte können Fehler machen, besonders in hektischen Kliniken. Diese Studie untersucht, ob fortgeschrittene KI‑Sprachmodelle Radiologinnen und Radiologen verlässlich dabei unterstützen können, schriftliche Befunde schnell, konsistent und präzise in diagnostische Impressionen zu überführen.
Rohbeschreibungen der Bilder in klare Antworten verwandeln
Gehirn‑MRTs erzeugen eine Reihe von Bildern, die Radiologinnen und Radiologen in einem „Befund“-Abschnitt beschreiben, etwa wo sich eine Läsion befindet, wie hell sie erscheint und ob Schwellungen vorliegen. Die eigentliche Herausforderung besteht dann darin, all diese Details zu einer diagnostischen Impression wie „akuter Infarkt“ oder „Hirnabszess“ zusammenzuführen. Die Forschenden sammelten 4293 MRT‑Berichte aus drei Krankenhäusern in China, die 16 diagnostische Kategorien abdecken und damit mehr als 95 % der alltäglichen Hirnerkrankungen umfassen. Anschließend testeten sie zehn verschiedene große Sprachmodelle — fortgeschrittene textbasierte KI‑Systeme — darauf, wie gut jedes die schriftlichen Befunde in die korrekten Diagnosen übersetzen kann.
Große, gut trainierte KI‑Modelle lagen vorn
Das Team verglich Modelle mit etwa 8 Milliarden bis 671 Milliarden internen Parametern, was man grob mit dem Unterschied zwischen dem Wissen einer Medizinstudentin und dem eines erfahrenen Expertenteams vergleichen kann. Das größte Modell, DeepSeek‑R1, erzielte durchgängig die beste Leistung, wenn es sowohl strukturierte Versionen der Befunde als auch wichtige klinische Informationen wie Alter, Symptome oder Unfallvorgeschichte erhielt. Unter diesen Bedingungen identifizierte DeepSeek‑R1 das Vorhandensein oder Fehlen spezifischer Hirnerkrankungen mit hoher Sensitivität und Spezifität und erreichte eine Patienten‑Ebene‑Genauigkeit von über 87 %. Kleinere Modelle, insbesondere solche unter 10 Milliarden Parametern, hatten große Schwierigkeiten und lagen oft nur bei etwa 30 % korrekt gelöster Fälle — deutlich unter dem, was in der klinischen Praxis akzeptabel wäre.
Warum Struktur und Kontext die KI besser machen
Die Forschenden fütterten die Modelle nicht einfach mit Freitext. Sie verwendeten zusätzlich ein anderes KI‑System, um die Berichte in klare, standardisierte Elemente zu überführen: etwa Lage der Läsion, Anzahl und ihr Erscheinungsbild in den unterschiedlichen MRT‑Sequenzen. Diese strukturierte Darstellung kombiniert mit kurzen klinischen Notizen machte einen deutlichen Unterschied. Für DeepSeek‑R1 führte die Umstellung von rohem Freitext auf strukturierte Befunde plus klinischen Kontext zu Verbesserungen bei Sensitivität, Gesamtgenauigkeit und zusammenfassenden Leistungskennzahlen. Einfach gesagt: Die KI arbeitete deutlich besser, wenn sie sauberere, besser organisierte Informationen und etwas Hintergrund zum Patienten bekam — ähnlich wie menschliche Radiologinnen und Radiologen, die am besten arbeiten, wenn Berichte ordentlich sind und die klinische Fragestellung klar ist.
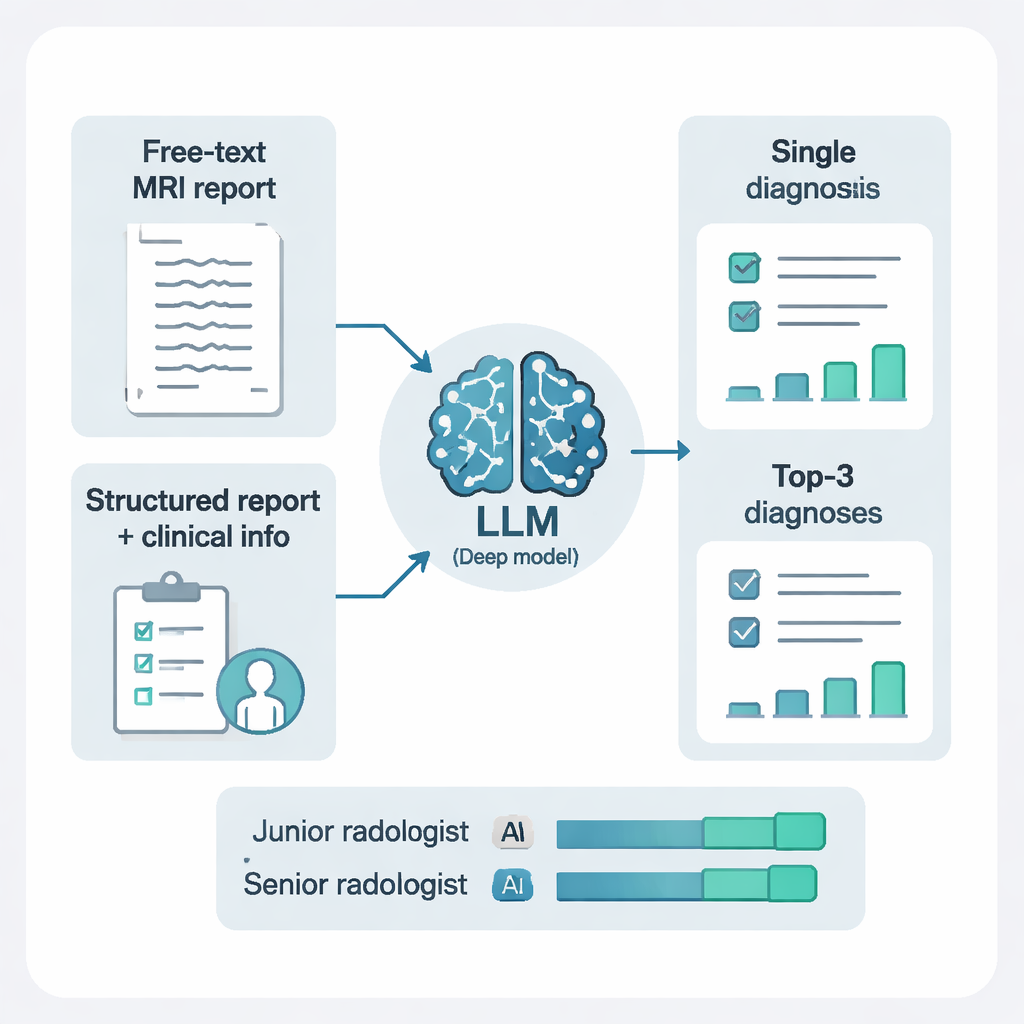
Von einer einzelnen Vermutung zu einer priorisierten Kurzliste
Im klinischen Alltag nennen Radiologinnen und Radiologen bei schwierigen Fällen oft mehr als eine mögliche Diagnose. Die Studie prüfte zwei Prompt‑Stile: die KI um eine einzige Diagnose bitten oder um die drei wichtigsten Möglichkeiten mit kurzer Begründung. Die Option mit drei priorisierten Diagnosen verbesserte die Leistung erheblich. Mit diesem Ansatz der „differentialdiagnostischen“ Liste tauchte die richtige Antwort bei mehr als 97 % der Patient*innen irgendwo unter den drei Top‑Vorschlägen auf. Das war besonders hilfreich bei komplexen Fällen wie Tumoren, Blutungen oder entzündlichen Erkrankungen, bei denen eine einzelne erzwungene Vermutung irreführend sein kann, während eine kurze, begründete Liste weitere Abklärung und Therapie besser lenkt.
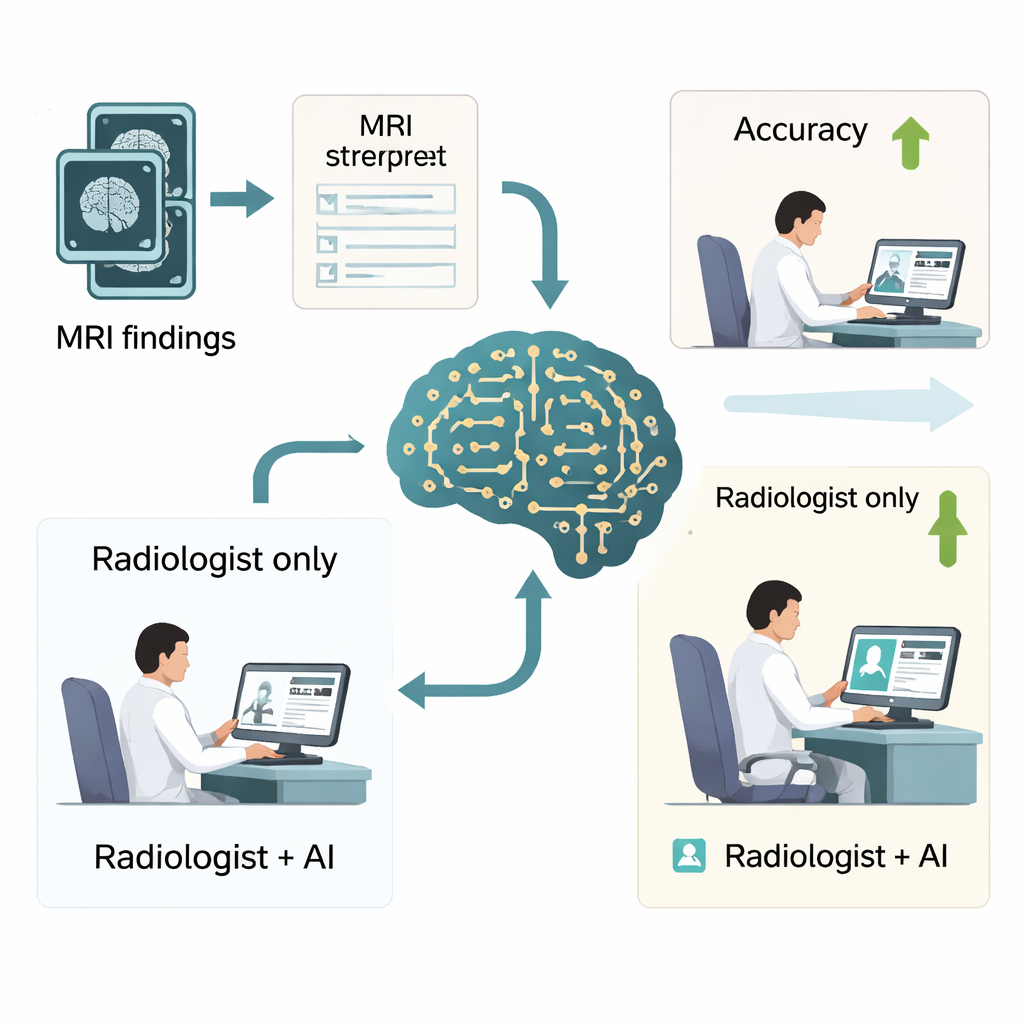
Konkreter Nutzen für vielbeschäftigte Radiolog*innen
Um zu prüfen, ob diese Verbesserungen im Alltag relevant sind, führten die Autorinnen und Autoren eine Leser*innen‑Studie mit sechs Radiologinnen und Radiologen — drei Junioren und drei Seniorinnen/Senioren — durch, die 500 Gehirn‑MRT‑Berichte mit und ohne Hilfe von DeepSeek‑R1 auswerteten. Mit KI‑Unterstützung stieg die Gesamtgenauigkeit von etwa drei Vierteln der Fälle auf über 90 %, und eine zentrale Qualitätskennzahl aus Präzision und Rückruf verbesserte sich ebenfalls deutlich. Auch die Lesezeit sank, von etwa einer Minute pro Fall auf unter einer Minute, was sich pro Radiologe bzw. Radiologin auf Dutzende eingesparter Stunden pro Jahr summieren könnte. Den größten Nutzen hatten Junior‑Radiolog*innen, deren Leistungen sich denen erfahrener Expert*innen annäherten. Die Studie betont jedoch auch, dass Ärztinnen und Ärzte wachsam bleiben müssen und KI nicht blind vertrauen sollten, insbesondere bei sehr subtilen Befunden wie bestimmten Formen von Hirnblutungen.
Was das für künftige Hirnuntersuchungs‑Berichte bedeutet
Für Patient*innen lautet die wichtigste Schlussfolgerung: Leistungsfähige, sprachbasierte KI‑Systeme können Radiologinnen und Radiologen bereits jetzt dabei unterstützen, komplexe MRT‑Beschreibungen in klarere, präzisere diagnostische Impressionen zu überführen — vor allem, wenn sie gut strukturierte Informationen und wesentliche klinische Details erhalten. Diese Werkzeuge ersetzen nicht die menschliche Expertise, sondern können als eine zweite, sorgfältige Prüfung fungieren, begründete Vorschläge liefern und Zeit sparen. Werden sie breiter validiert und sicher in Krankenhaussysteme integriert, könnten solche KI‑Unterstützungen MRT‑Berichte schneller, verlässlicher und konsistenter machen — und so die Versorgung von Menschen mit Schlaganfall, Tumoren, Infektionen und vielen anderen Hirnerkrankungen verbessern.
Zitation: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Schlüsselwörter: Gehirn‑MRT‑Diagnose, Radiologie künstliche Intelligenz, große Sprachmodelle, klinische Entscheidungsunterstützung, DeepSeek‑R1