Clear Sky Science · de
Große Sprachmodelle verbessern die Übertragbarkeit von Vorhersagen aus elektronischen Gesundheitsakten zwischen Ländern und Kodiersystemen
Warum klügeres Teilen von medizinischen Daten wichtig ist
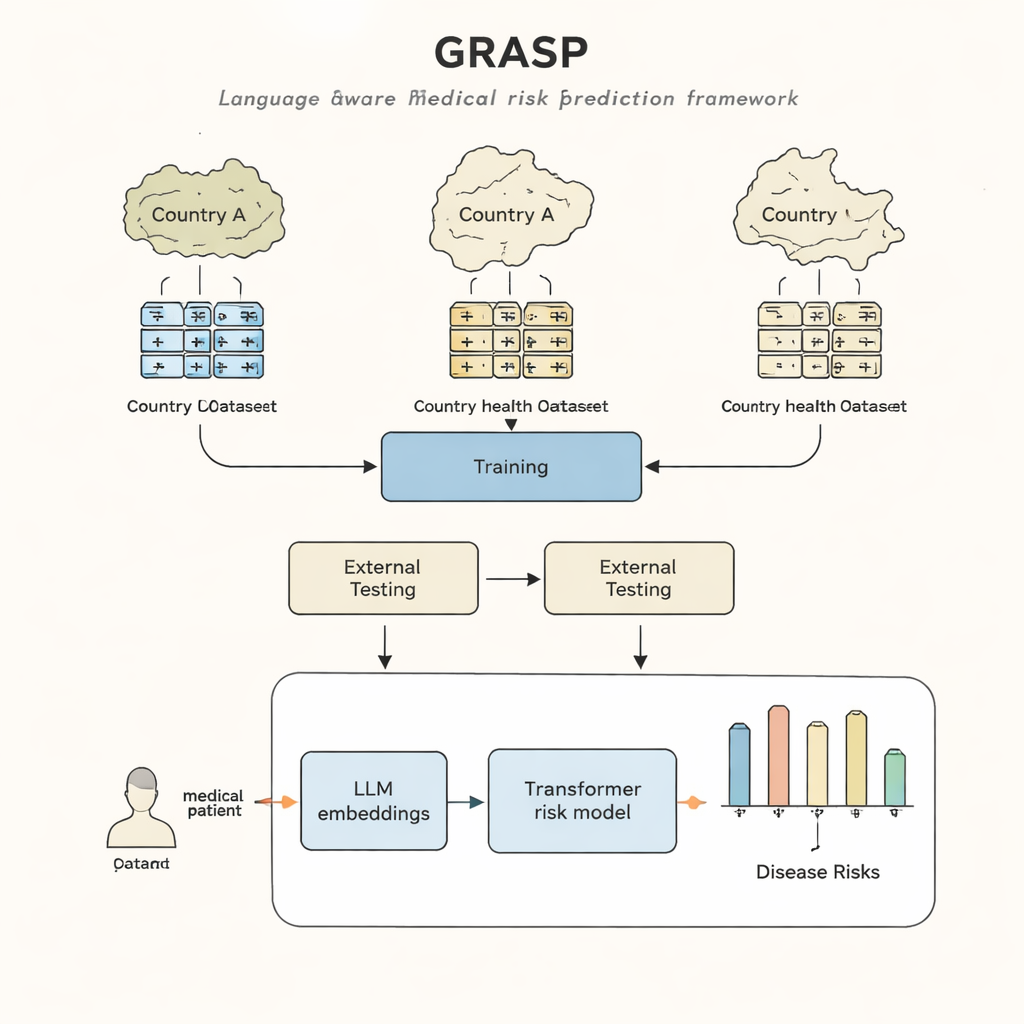
Krankenhäuser und Kliniken weltweit sitzen auf einem Datenschatz: elektronische Gesundheitsakten, die Diagnosen, Behandlungen und Ergebnisse von Menschen über viele Jahre festhalten. Theoretisch könnten diese Informationen Ärzten helfen, frühzeitig Personen mit hohem Risiko für schwere Erkrankungen zu identifizieren, lange bevor Symptome offensichtlich werden. In der Praxis haben heutige Computermodelle jedoch Schwierigkeiten, von einem Land oder einem Krankenhausnetzwerk ins andere "zu reisen", weil an jedem Ort Gesundheitsdaten anders dokumentiert werden. Diese Studie stellt einen neuen Ansatz vor, genannt GRASP, der Fortschritte in der künstlichen Intelligenz nutzt, um diese Lücken zu überbrücken, sodass ein in einem Gesundheitssystem trainiertes Modell auch in anderen zuverlässig arbeiten kann.
Unterschiedliche Krankenhäuser, unterschiedliche "Sprachen"
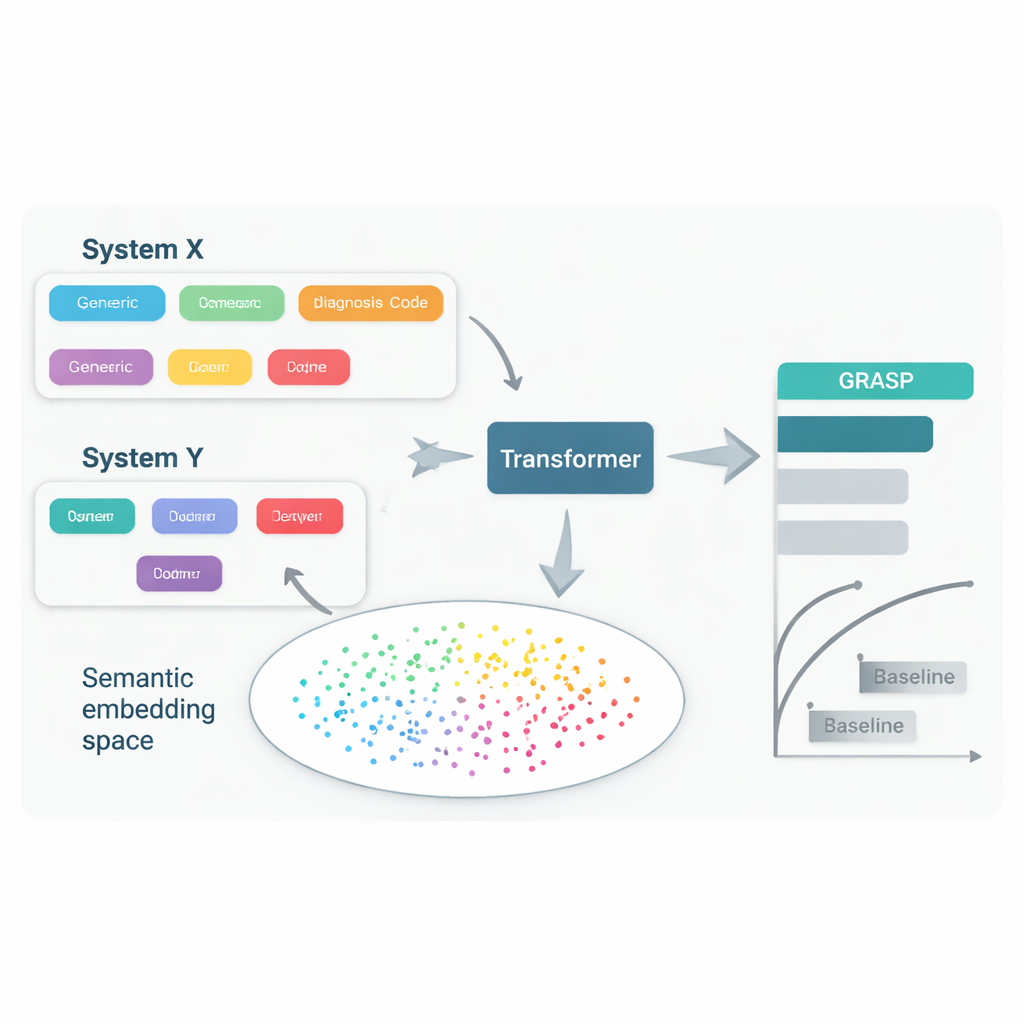
Selbst wenn Ärzte dieselbe Krankheit behandeln, verwenden sie häufig unterschiedliche Kodiersysteme und lokale Konventionen zur Dokumentation in der Patientenakte. Ein Krankenhaus könnte "hoher Blutzucker" unter einem Code ablegen, ein anderes verwendet einen anderen Code für "Hyperglykämie" und ein drittes nutzt ein völlig anderes System. Versuche, alle an einen einzigen gemeinsamen Standard zu binden – etwa große internationale Kodierschemata – sind nützlich, aber langsam, teuer und lassen weiterhin wichtige Unterschiede bestehen. Infolgedessen kann ein Modell, das Krankheiten aus Datensätzen eines Landes vorhersagt, an Genauigkeit verlieren, wenn es anderswo angewendet wird, was den Kreis der Nutznießer dieser Werkzeuge einschränkt.
Die Bedeutung lesen lassen, nicht nur den Code
Der GRASP-Ansatz beginnt mit einer einfachen Idee: Anstatt jeden medizinischen Code als bedeutungslose Kennnummer zu behandeln, lässt man ein großes Sprachmodell die menschenlesbare Beschreibung dahinter lesen, etwa "akute obere Atemwegsinfektion", und diese Bedeutung in eine numerische "Einbettung" (Embedding) umwandeln. Solche Einbettungen bringen verwandte Konzepte in einen gemeinsamen Raum dicht zusammen, selbst wenn sie aus unterschiedlichen Kodiersystemen oder Ländern stammen. GRASP berechnet solche Einbettungen im Voraus für Millionen standardisierter medizinischer Begriffe und speichert sie in einer Nachschlagetabelle. Die Krankengeschichte eines Patienten wird dann als Reihe dieser aussagekräftigen Vektoren dargestellt, die in ein Transformer-Netzwerk – eine Form von neuronalen Netzwerken, die gut mit Sammlungen vielfältiger Eingaben umgehen können – eingespeist werden, um das Risiko für 21 wichtige Erkrankungen sowie das Gesamtsterberisiko zu schätzen.
Tests über Länder- und Aktengrenzen hinweg
Die Forschenden trainierten GRASP mit Daten von fast 400.000 Teilnehmenden des UK Biobank und testeten es dann ohne erneutes Training in zwei sehr unterschiedlichen Umgebungen: dem FinnGen-Projekt in Finnland und einem großen Krankenhausnetzwerk in New York City. GRASP erreichte mindestens die Leistung starker Alternativen oder übertraf sie, darunter eine populäre Methode namens XGBoost und einen ähnlichen Transformer, der nicht auf sprachbasierte Einbettungen zurückgriff. In Finnland zeigte GRASP besonders gute Ergebnisse und deutliche Verbesserungen bei Krankheiten wie Asthma, chronischer Nierenerkrankung und Herzinsuffizienz. Auffällig ist, dass GRASP selbst dann bessere Vorhersagen lieferte als nur demografische Daten, wenn die amerikanischen Krankenhausdaten in einem anderen Kodierschema verblieben statt in einen gemeinsamen Standard konvertiert zu werden, weil es Codes allein über das Verständnis ihrer Beschreibungen in Einklang bringen konnte.
Mehr erreichen mit weniger Daten
Ein weiterer Vorteil von GRASP ist die Effizienz. Da das Sprachmodell bereits gelernt hat, dass viele medizinische Konzepte miteinander verwandt sind, muss das Vorhersagenetzwerk diese Zusammenhänge nicht von Grund auf neu entdecken. Als die Autorinnen und Autoren GRASP mit deutlich kleineren Teilmengen der UK-Daten trainierten – bis hinunter zu nur 10.000 Personen – übertraf es weiterhin konkurrierende Modelle, die mit denselben begrenzten Stichproben trainiert wurden, sowohl im Vereinigten Königreich als auch bei der Übertragung ins Ausland. Die Risikowerte von GRASP stimmten außerdem stärker mit dem vererbten genetischen Risiko für mehrere Krankheiten überein, was darauf hindeutet, dass es tiefere Aspekte der Krankheitsanfälligkeit erfasst und nicht nur Muster in einem einzelnen Datensatz auswendig lernt.
Was das für die zukünftige Versorgung bedeutet
Für Nicht-Spezialisten ist die Kernbotschaft: GRASP zeigt, wie moderne sprachbasierte KI unterschiedlichen Gesundheitssystemen helfen kann, "die gleiche Sprache zu sprechen", ohne sie in ein starres, einheitliches Kodierschema zu zwingen. Indem es die Bedeutung medizinischer Begriffe liest, kann GRASP Krankheitsrisiken vorhersagen, die über Länder und Aktenformate hinweg besser generalisieren, und das mit weniger Patientenbeispielen. Während die Methode vor dem Einsatz in der Routineversorgung noch sorgfältig getestet, neu kalibriert und auf Fairness geprüft werden muss, weist sie in Richtung einer Zukunft, in der leistungsfähige Risikowerkzeuge, die an einem Ort entwickelt wurden, sicher und effizient mit Krankenhäusern und Kliniken weltweit geteilt werden können.
Zitation: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Schlüsselwörter: elektronische Gesundheitsakten, Krankheitsrisikovorhersage, große Sprachmodelle, Medizindatenaustausch, KI im Gesundheitswesen