Clear Sky Science · de
Vergleich dezentraler Machine‑Learning‑ und KI‑Klinikmodelle mit lokalen und zentralen Alternativen: eine systematische Übersichtsarbeit
Warum es wichtig ist, medizinische Erkenntnisse zu teilen, ohne Daten weiterzugeben
Die moderne Medizin stützt sich zunehmend auf künstliche Intelligenz, um Krankheiten früher zu erkennen, die passende Therapie zu wählen und vorherzusagen, wer das höchste Risiko trägt. Die leistungsfähigsten KI‑Werkzeuge benötigen jedoch große Mengen an Patientendaten, und Krankenhäuser können ihre Aufzeichnungen nicht einfach zusammenlegen, weil strenge Datenschutzgesetze und ethische Bedenken dem entgegenstehen. Dieser Artikel fasst mehr als ein Jahrzehnt Forschung zu „dezentralem“ Lernen zusammen – Verfahren, mit denen Krankenhäuser gemeinsam KI trainieren können, ohne jemals rohe Patientendaten auszutauschen – und stellt eine praktische Frage: Wie gut schneiden diese datenschutzwahrenden Methoden im Vergleich zu traditionellen Ansätzen tatsächlich ab?
Neue Wege, von Patientinnen und Patienten zu lernen und gleichzeitig die Privatsphäre zu schützen
Beim klassischen zentralisierten Lernen kopieren Krankenhäuser alle Daten in eine große Datenbank und trainieren dort ein einzelnes Modell. Beim lokalen Lernen erstellt jede Einrichtung ihr eigenes Modell auf ihren eigenen Daten, ohne Zusammenarbeit. Dezentrales Lernen bietet einen Mittelweg. Beim Federated Learning trainiert etwa jedes Krankenhaus lokal ein Modell; nur die Modelleinstellungen (die „Knöpfe“ eines neuronalen Netzes) werden zur Kombination in ein gemeinsames Modell gesendet; Patientendaten verlassen nie den Standort. Swarm Learning verzichtet auf einen zentralen Koordinator und erlaubt Einrichtungen, Modellupdates direkt auszutauschen. Andere dezentrale Ansätze kombinieren Vorhersagen mehrerer lokaler Modelle oder teilen das Modell über Standorte auf. Diese Methoden wurden bei Problemen von Krebsdetektion und COVID‑19‑Diagnostik bis hin zu Herzkrankheiten, Diabetes, Hirnerkrankungen und psychiatrischen Störungen erprobt.
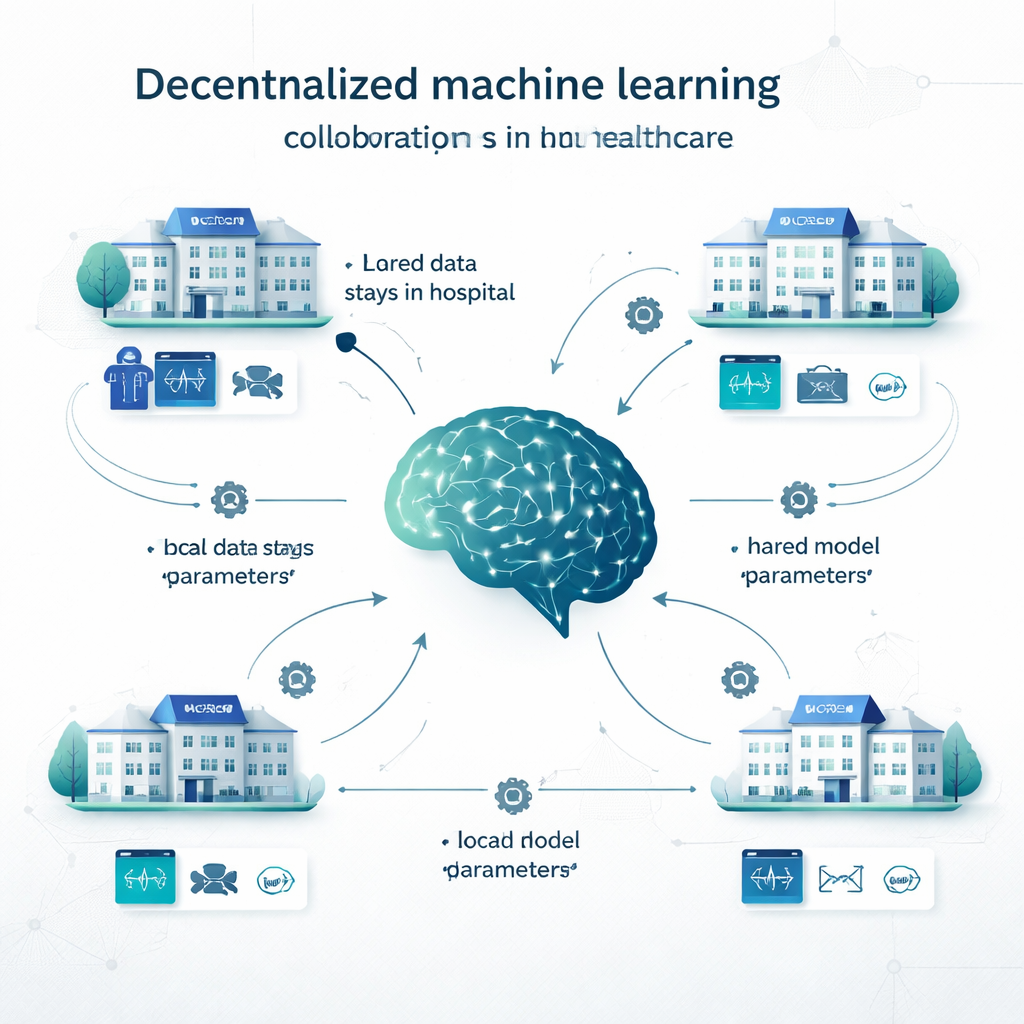
Was die Forschenden untersuchten
Die Autorinnen und Autoren durchsuchten systematisch 11 große Datenbanken und sichteten 165.010 Studien, die zwischen 2012 und März 2024 veröffentlicht wurden. Nach Entfernen von Duplikaten und von Studien, die keine realen klinischen Entscheidungen betrafen, blieben 160 Artikel übrig. Zusammen berichteten diese Arbeiten über 710 dezentrale Modelle und 8.149 direkte Leistungsvergleiche gegenüber zentralen oder lokalen Modellen. Die meisten Studien konzentrierten sich auf Diagnoseaufgaben, aber es gab auch viele zur Bildsegmentierung (z. B. Tumorabgrenzung), zur Vorhersage zukünftiger Ergebnisse wie Überleben oder Komplikationen sowie zu kombinierten Aufgaben. Die verwendeten Datentypen umfassten beinahe jede wichtige Quelle in der Medizin: elektronische Gesundheitsakten, CT‑ und MRT‑Scans, Röntgenaufnahmen, digitale Pathologie‑Bilder, Herz‑ und Hirnsignale und sogar genetische Daten.
Wie sich datenschutzwahrende Modelle gegenüber zentralisierter KI schlagen
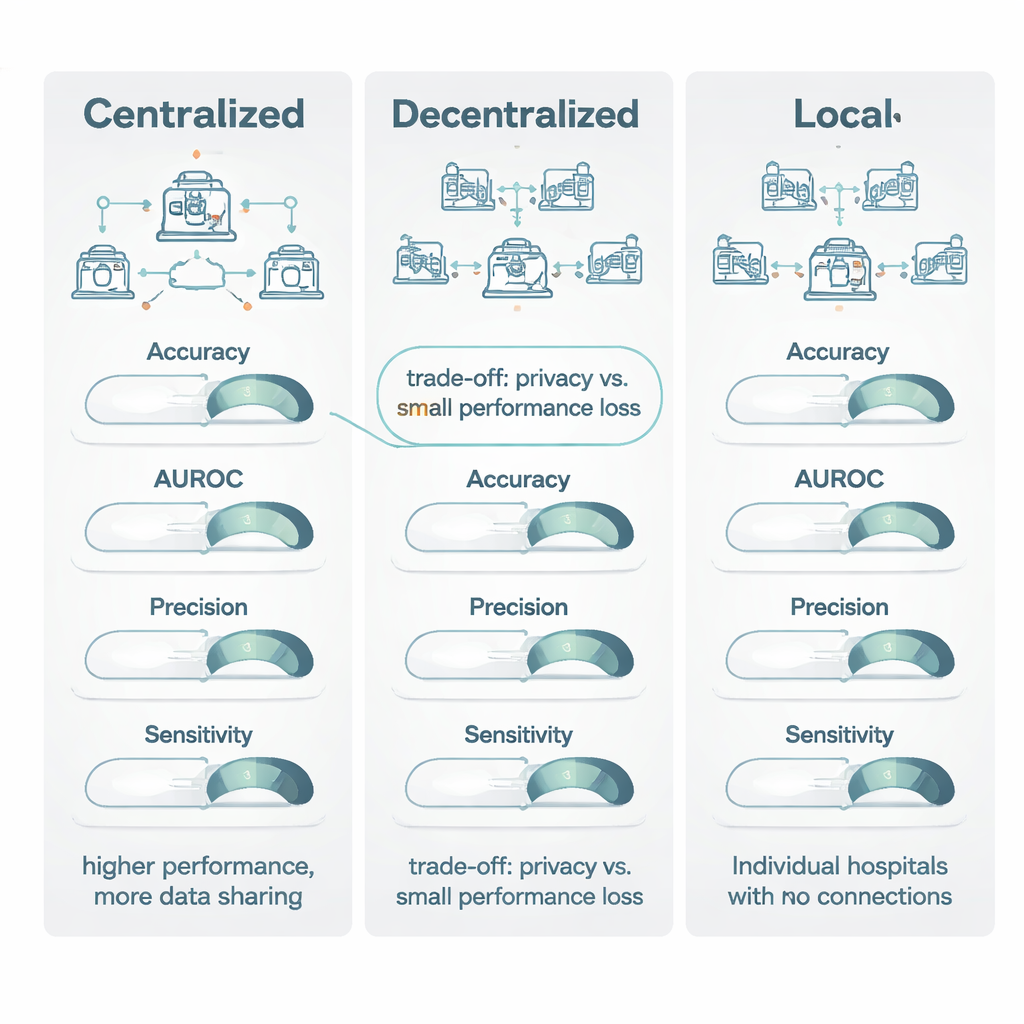
Wenn dezentrale Modelle mit zentralen Modellen verglichen wurden, die auf gepoolten Daten trainiert waren, lag das zentralisierte Lernen meist leicht vorn. Besonders deutlich war der Vorsprung bei „Schwellenwert‑basierten“ Maßen wie Genauigkeit und einem gängigen Bildgebungsmaß, dem Dice‑Koeffizienten: Hier gewann das zentrale Lernen in etwa drei Vierteln der Fälle und in einem Ausmaß, das als moderater bis großer Vorteil einzustufen ist. Bei Rangordnungsmaßen – etwa der Fläche unter der ROC‑Kurve (AUROC), die beurteilt, wie gut ein Modell Patientinnen und Patienten von niedrigerem zu höherem Risiko einstuft – lagen dezentrale und zentrale Modelle deutlich näher beieinander, mit nur einem kleinen Vorteil für das zentrale Training. Wichtig ist: Wenn beide Modelle eine vom Autorenteam als „klinisch brauchbar“ definierte Leistung erreichten (ein Wert von mindestens 0,80), war der typische Zugewinn des zentralen Modells gering: oft weniger als 1–1,5 Prozentpunkte. In vielen Fällen entsprach das eher „hervorragend versus akzeptabel“ als „gebrauchstauglich versus unbrauchbar“.
Warum dezentrales Lernen dem Alleingang überlegen ist
Das stärkste Signal in der Übersicht zeigte sich beim Vergleich dezentraler Modelle mit rein lokalen Modellen. Über alle wichtigen Kennzahlen hinweg – Genauigkeit, AUROC, F1‑Score, Sensitivität, Spezifität und insbesondere Präzision – schnitten dezentrale Methoden fast immer besser ab, häufig deutlich. In direkten Vergleichen übertrafen dezentrale Modelle lokale Modelle in mehr als 80 % der Fälle für Schlüsselmaße wie Genauigkeit, Präzision und AUROC. In vielen Fällen erreichten lokale Modelle nicht die 0,80‑Schwelle für klinische Nützlichkeit, während das jeweilige dezentrale Modell sie problemlos übertraf und die Sensitivität um bis zu 27 Prozentpunkte verbesserte. Die Autorinnen und Autoren führen dies auf die größere „Erfahrung“ multi‑standortiger Modelle zurück: Indem sie Muster aus vielen Krankenhäusern „sehen“, werden sie weniger durch standortspezifische Eigenheiten von Scannern oder Dokumentation getäuscht und empfindlicher für Krankheitsmerkmale, die wirklich generalisierbar sind.
Abwägung von Leistung, Datenschutz und praktischer Einsetzbarkeit
Die Übersichtsarbeit kommt zu dem Schluss, dass zentralisiertes Lernen weiterhin der Goldstandard ist, wenn Datenschutzbestimmungen und organisatorische Abläufe das Zusammenführen von Daten erlauben und wenn jeder Bruchteil eines Prozentpunkts in der Leistung zählt – etwa bei sehr seltenen Erkrankungen. Dezentrales Lernen stellt jedoch eine leistungsfähige und klinisch vertretbare Alternative dar für Situationen, in denen das Teilen von Daten durch Gesetze wie die DSGVO und den EU‑KI‑Verordnung oder durch institutionelle Richtlinien eingeschränkt ist. Im Vergleich zu vollständig lokalen Modellen bieten dezentrale Ansätze große Vorteile in Hinsicht auf Genauigkeit und Zuverlässigkeit, während die Daten innerhalb der Krankenhausmauern verbleiben. Die Autorinnen und Autoren plädieren dafür, dass künftige Arbeiten Datenschutzmaßnahmen und Rechenkosten klarer berichten, damit Gesundheitssysteme informierte Entscheidungen darüber treffen können, wann geringfügige Leistungseinbußen die erheblichen Vorteile bei Privatsphäre und Zusammenarbeit wert sind.
Zitation: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Schlüsselwörter: federated learning, Healthcare‑KI, Datenschutz bei medizinischen Daten, dezentralisiertes Machine Learning, klinische Prognosemodelle