Clear Sky Science · de
Entwicklung eines Deep‑Learning‑Modells zur Erkennung von primärem Offenwinkelglaukom bei Personen afrikanischer Abstammung
Warum das für die alltägliche Augengesundheit wichtig ist
Glaukom zählt zu den weltweit häufigsten Ursachen irreversibler Erblindung und raubt das Sehvermögen oft stillschweigend, bevor Betroffene Symptome bemerken. Die vorliegende Studie untersucht, wie künstliche Intelligenz dazu beitragen kann, eine verbreitete Form des Glaukoms früher zu erkennen — insbesondere in Gemeinschaften afrikanischer Abstammung, die ein höheres Risiko und schlechteren Zugang zu fachärztlicher Augenversorgung haben. Indem ein Computer das Lesen von Augenfotografien erlernt, wollen die Forschenden zuverlässiges Glaukom‑Screening in Hausarztpraxen, Gemeindekliniken und ressourcenarmen Einrichtungen weltweit bringen.
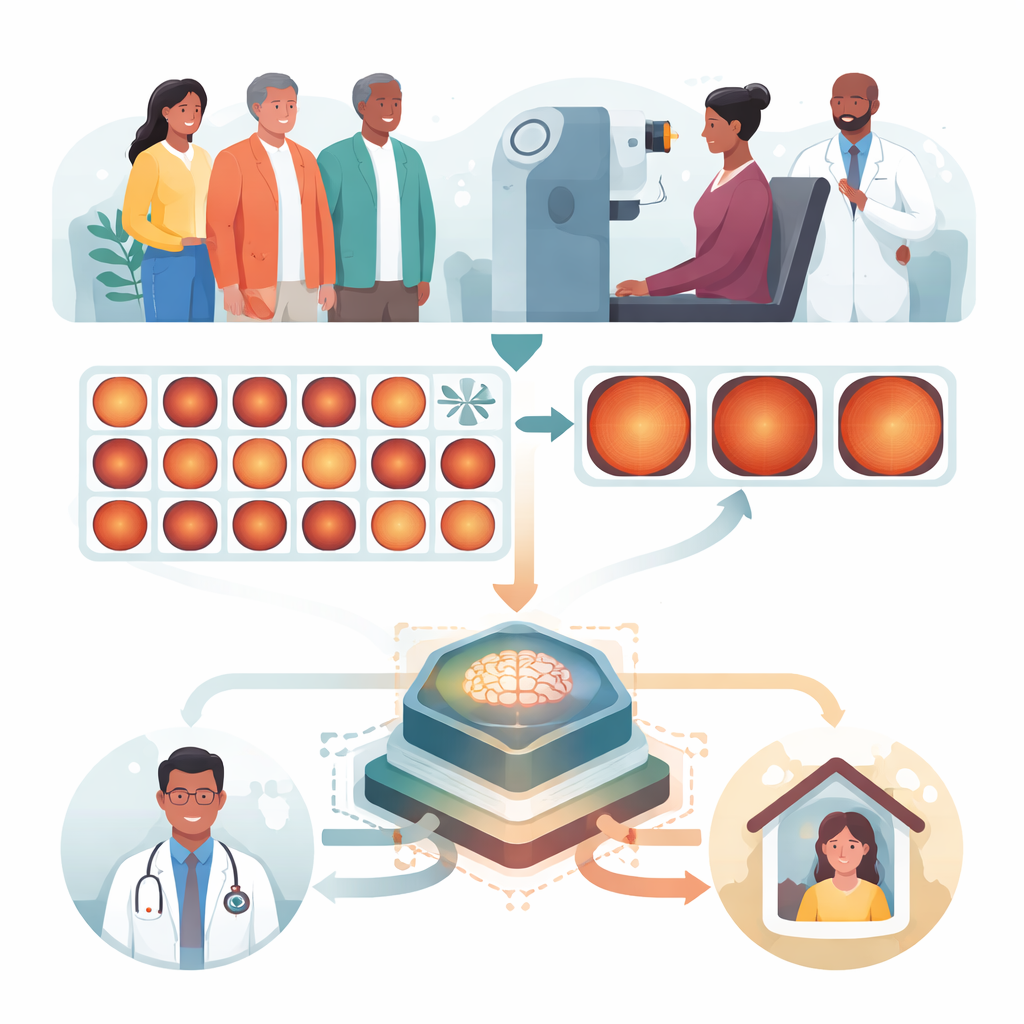
Die stille Bedrohung fürs Sehen
Das primäre Offenwinkelglaukom schädigt langsam den Sehnerv, das Kabel, das visuelle Informationen vom Auge zum Gehirn leitet. In frühen Stadien fühlen sich Betroffene meist wohl und sehen gut, während das Seiten‑ oder Randsehvermögen bereits schrumpft. Weil die Krankheit leise fortschreitet und Augenuntersuchungen zeitaufwendig und in vielen Regionen knapp sind, bleiben viele Patientinnen und Patienten bis zur irreversiblen Sehverschlechterung undiagnostiziert. Diese Belastung ist besonders groß bei Menschen afrikanischer Abstammung: Sie entwickeln häufiger ein Glaukom und erleiden öfter Erblindung, waren jedoch historisch in medizinischer Forschung und hochwertigen Bilddatensätzen unterrepräsentiert.
Computern das Lesen von Augenbildern beibringen
Das Team entwickelte ein automatisiertes Screening‑System, das Farbaufnahmen des Augenhintergrunds — sogenannte Fundus‑Bilder — analysiert. Solche Bilder sind vergleichsweise günstig und einfach zu erstellen, selbst außerhalb einer Facharztpraxis. Aus mehr als 64.000 Bildern, die in der Primary Open‑Angle African American Glaucoma Genetics (POAAGG)‑Studie gesammelt wurden, trainierten die Forschenden Deep‑Learning‑Modelle, um glaukomkranke von nicht‑erkrankten Augen zu unterscheiden. Sie verglichen zwei moderne Ansätze: ein konvolutionales „ResNet“‑Modell und einen „Vision Transformer“, der das Bild in Patches untersucht und zeigen kann, worauf er seine Aufmerksamkeit richtet — häufig den Cup‑und‑Disc‑Bereich des Sehnervs, in dem sich glaukombedingte Veränderungen zeigen.
Zuerst die klarsten Bilder auswählen
Beim realen Screening werden oft mehrere Bilder pro Besuch aufgenommen, um Probleme wie Blinzeln oder Unschärfe zu vermeiden. Statt alle Aufnahmen dem Modell zuzuführen, prüften die Forschenden, ob die gezielte Auswahl nur der informativsten Bilder die Genauigkeit steigern könnte. Sie testeten zwei automatische Auswahlstrategien. Eine nutzte ein Segmentierungsmodell, um den Sehnerv zu umreißen und Bilder mit bestimmten Größenmerkmalen zu wählen. Die andere — ein binärer Klassifikator — lernte, die Expertinnen und Experten eines Lesezentrums zu imitieren und „gute“ von schlechten Bildern zu trennen. Die Auswahl von nur sechs hochwertigen Bildern pro Besuch mittels des binären Klassifikators erreichte die Leistung menschlicher Gutachter und übertraf deutlich sowohl die Verwendung aller Bilder als auch die segmentierungsbasierte Methode.
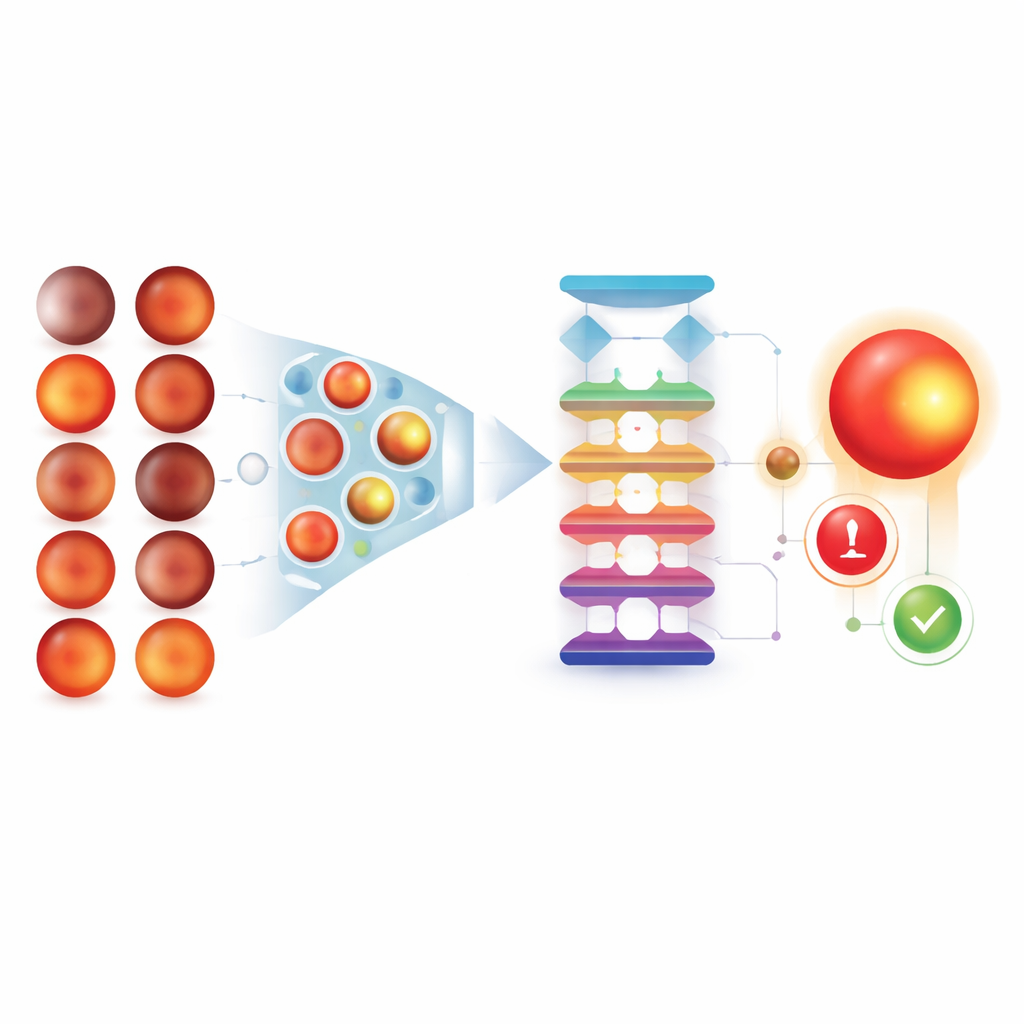
Viele Hinweise zu einer einzigen Entscheidung vereinen
Nach der Auswahl der besten Bilder eines Besuchs analysierte das System jedes einzelne mit dem Vision Transformer und gab eine Wahrscheinlichkeit aus, dass ein Glaukom vorliegt. Die Forschenden untersuchten dann, wie mehrere Wahrscheinlichkeiten am besten zu einer einzigen Screening‑Entscheidung zusammengefasst werden. Der einfache Mittelwert über die ausgewählten Bilder lieferte die zuverlässigsten Ergebnisse, etwas besser als das Verlassen auf nur den extremsten Wert. Insgesamt erreichte diese Pipeline — Bildauswahl durch den binären Klassifikator, gefolgt von Einzelbild‑Vorhersagen und Mittelung — eine hohe Fähigkeit, Glaukomfälle von Nicht‑Glaukomfällen zu trennen. Beim Test an einem separaten Datensatz chinesischer Patientinnen und Patienten arbeitete das Modell ebenfalls gut; weitere Experimente zeigten, dass ein größeres Trainingsset entscheidend für diese Übertragbarkeit zwischen Gruppen war.
Was das für Patientinnen und Patienten bedeuten könnte
Die Studie zeigt, dass eine sorgfältig entworfene KI‑Pipeline, trainiert an einer großen Sammlung von Augenbildern von Personen afrikanischer Abstammung, Menschen mit möglichem Glaukom zuverlässig anhand einfacher Fotografien identifizieren kann. Zwar erreicht das System noch nicht die sehr strengen Schwellenwerte, die einige Organisationen für vollständige Diagnosetools empfehlen, es eignet sich jedoch gut als Vorscreening‑Verfahren in Regionen mit wenigen Augenspezialisten. Mit weiterer Validierung an vielfältigeren Populationen und Kameras sowie möglicher Integration mit anderen Augenuntersuchungen könnte eine solche Technologie eines Tages in Hausarztpraxen, Gemeindeaktionen oder ländlichen Gesundheitszentren eingesetzt werden. Das Ziel ist klar: Glaukom früher entdecken, Risikopersonen an Fachärzte überweisen und vermeidbare Erblindungen verhindern — insbesondere in den am stärksten betroffenen Gemeinschaften.
Zitation: Li, S., Salowe, R., Lee, R. et al. Development of deep learning model to screen for primary open-angle glaucoma in African ancestry individuals. npj Digit. Med. 9, 214 (2026). https://doi.org/10.1038/s41746-025-02318-2
Schlüsselwörter: Glaukom‑Screening, Künstliche Intelligenz, Retinales Imaging, Gesundheit afrikanischer Abstammung, Deep‑Learning‑Medizin