Clear Sky Science · de
Unsicherheitsmodellierung in multimodaler Sprachanalyse über das Psychosespektrum
Auf verborgene Hinweise im Alltagsgespräch hören
Psychose wird oft als plötzlich und dramatisch wahrgenommen – Stimmen, Visionen und ein Bruch mit der Realität. Doch lange vor einer Krise können sich subtile Veränderungen darin zeigen, wie Menschen sprechen: Tonfall, Wortwahl oder sogar der Rhythmus ihrer Sätze. Diese Studie untersucht, ob Computer diese schwachen Signale in der Sprache erkennen können und, entscheidend, wie zuversichtlich sie in ihren Einschätzungen sind. Damit weist die Arbeit auf mögliche künftige Werkzeuge hin, die Klinikern helfen könnten, psychische Gesundheit objektiver zu verfolgen und die Betreuung über das gesamte Spektrum von geringem Risiko bis hin zur manifesten Erkrankung zu personalisieren.
Vom ungezwungenen Gespräch bis zum klinischen Interview
Die Forschenden zeichneten Sprache von 114 deutschsprachigen Freiwilligen auf, die das Psychosespektrum abdeckten: Personen mit frühen psychotischen Störungen und Personen ohne Diagnosen, aber mit niedrigen oder hohen Ausprägungen psychoseähnlicher Merkmale (sogenannte Schizotypie). Jede Person absolvierte vier Arten von Sprechaufgaben, von strukturierten klinischen Interviews bis zu frei erzählten autobiografischen Geschichten, bildbasiertem Geschichtenerzählen und Alltagsgesprächen. Diese verschiedenen Situationen sind wichtig, weil ein eng geführtes Interview bestimmte Symptome wie affektive Verflachung hervorheben kann, während offene Erzählungen abschweifende Gedanken oder ungewöhnliche Wahrnehmungen zeigen können. Durch die Probenahme über Kontexte hinweg konnte das Team beurteilen, wie zuverlässig Sprache Symptome in realitätsnahen Situationen anzeigt.
Sowohl wie wir sprechen als auch was wir sagen hören
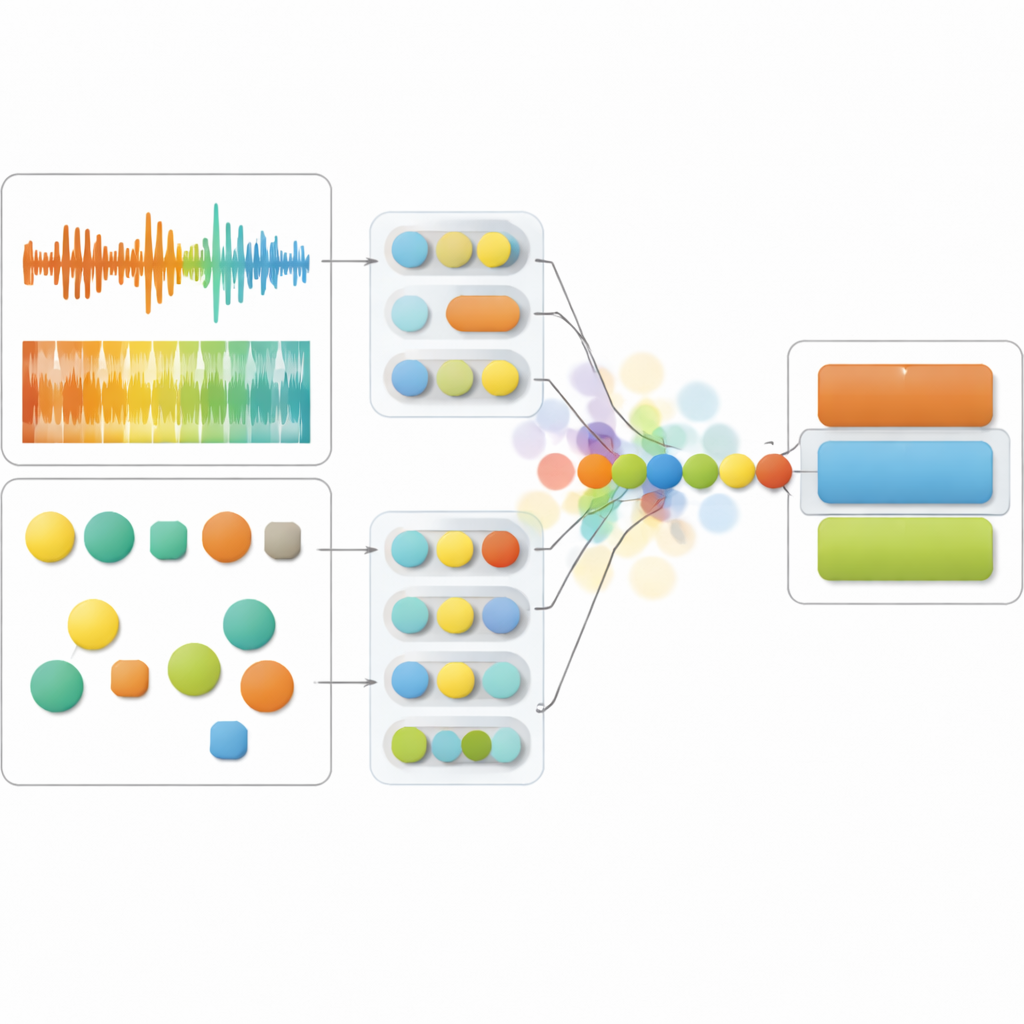
Das System der Studie hört gleichzeitig auf zwei Seiten der Sprache. Auf der klanglichen Seite erfasst es Merkmale wie Tonhöhenänderungen, Lautstärke und die feine Struktur der Stimme, die zusammen Ausdruck, Anspannung und Sprachfluß abbilden. Auf der sprachlichen Seite analysiert es die Wörter selbst – wie emotional sie sind, ob sie Wahrnehmungen oder soziale Verbindungen betonen und wie kohärent sie wirken. Fortgeschrittene neuronale Netze, ursprünglich auf großen Audio- und Textsammlungen trainiert, verwandeln diese Rohsignale in kompakte numerische Fingerabdrücke. Das Kernmodell verschmilzt diese Fingerabdrücke zeitlich, sodass es Moment für Moment beurteilen kann, welcher Kanal – Klang oder Sprache – den verlässlicheren Hinweis auf den psychischen Zustand einer Person liefert.
Das Modell darin schulen, Unsicherheit einzugestehen
Was diese Arbeit auszeichnet, ist, dass das Modell nicht nur eine Vorhersage ausgibt, sondern auch seine eigene Unsicherheit schätzt. Anstatt die Audio- und Textströme als fest anzusehen, stellt es sie als Wahrscheinlichkeitswolken dar, die sich ausdehnen können, wenn die Daten verrauscht oder ungewöhnlich sind. Ist die Sprachaufnahme verzerrt oder nuschelt die Person, gewichtet das System den Klang herunter und stützt sich stärker auf die Worte. Ist die Transkription unzuverlässig oder die Rede stark fragmentiert, verhält es sich umgekehrt. Diese unsicherheitsbewusste Fusion, genannt Temporal Context Fusion, erzielte starke Leistungen: Sie unterschied Gruppen mit niedriger Schizotypie, hoher Schizotypie und früher Psychose mit einem F1‑Score von 83 % und zeigte gut kalibrierte Zuversicht, das heißt die angegebene Sicherheit entsprach weitgehend der tatsächlichen Trefferquote.
Sprachmuster, die unterschiedliche Symptommuster widerspiegeln
Durch das Erkunden der internen Funktionsweise des Modells identifizierten die Forschenden, welche Aspekte der Sprache am beständigsten verschiedene Symptomausprägungen nachzeichneten. Personen mit intensiveren positiven Symptomen – wie ungewöhnlichen Erfahrungen oder wahnhaften Gedanken – zeigten tendenziell höhere und variablere Tonhöhen, schnelle Verschiebungen im Stimmfrequenzspektrum und stärkere Lautstärkeschwankungen, besonders bei offenen Erzählungen. Ihre Sprache enthielt zudem viele Wahrnehmungswörter (im Zusammenhang mit Sehen, Hören oder Empfinden) und emotional geladene Begriffe. Dagegen sprachen Personen mit stärker ausgeprägten negativen Symptomen – etwa sozialem Rückzug und emotionaler Abstumpfung – monotoner, mit eingeschränkter Tonhöhe und weniger flexibler Artikulation und verwendeten weniger Wörter für positive Emotionen und soziale Beziehungen. Desorganisierte Merkmale, sowohl bei Patienten als auch bei High‑Schizotypie‑Freiwilligen, zeigten sich als unstete Lautstärke, Zögern und fragmentierte Sprache, gefüllt mit Wörtern zu Risiken und kognitiven Prozessen, was auf mentale Anstrengung ohne klare Struktur hindeutet.
Warum das für die künftige Versorgung psychischer Gesundheit wichtig ist
In der Summe zeigen die Befunde, dass Sprache messbare Spuren psychosebezogener Merkmale trägt, selbst bei Personen, die nicht klinisch krank sind, und dass diese Spuren je nach Sprechsituation variieren. Das unsicherheitsbewusste Modell konnte Klang und Sprache nutzen, um positive, negative und desorganisierte Merkmale entlang eines Kontinuums nachzuverfolgen, und gleichzeitig offen anzeigen, wenn die Belege wackelig waren. Für Laien lautet die zentrale Idee, dass genaues Zuhören – verstärkt durch eine KI, die ihre eigenen Grenzen kennt – Klinikern letztlich helfen könnte, psychische Gesundheit objektiver zu überwachen, Unsicherheit zu verringern und bedeutsame Veränderungen früher zu erkennen. Statt menschliches Urteilsvermögen zu ersetzen, könnten solche Werkzeuge als ein zweites Paar Ohren dienen und Muster in Alltagsgesprächen hervorheben, die einer genaueren Betrachtung bedürfen.
Zitation: Rohanian, M., Hüppi, R., Nooralahzadeh, F. et al. Uncertainty modeling in multimodal speech analysis across the psychosis spectrum. npj Digit. Med. 9, 218 (2026). https://doi.org/10.1038/s41746-025-02309-3
Schlüsselwörter: Psychose, Sprachanalyse, maschinelles Lernen, Beurteilung psychischer Gesundheit, multimodale KI