Clear Sky Science · de
IMFLKD: ein Anreizmechanismus für dezentralisiertes föderiertes Lernen basierend auf Knowledge Distillation
Warum Teilen sicher und fair sein kann
Moderne künstliche Intelligenz lebt von Daten, doch die meisten unserer Daten liegen auf persönlichen Smartphones, Krankenhausservern oder Unternehmens-Clouds, die nicht einfach kopiert und weitergegeben werden können. Föderiertes Lernen bietet einen Weg, viele Geräte ein gemeinsames Modell trainieren zu lassen, ohne ihre Rohdaten offenzulegen, aber heutige Systeme haben weiterhin Probleme mit Datenschutzlecks, zentralen Ausfallpunkten und unfairen Belohnungen für diejenigen, die am meisten beitragen. Dieses Paper stellt einen neuen Rahmen vor, IMFLKD, der drei wirkungsvolle Ideen kombiniert — Blockchain, Knowledge Distillation und Reputationsbewertungen — um kollektives Lernen langfristig privater, robuster und gerechter zu machen.
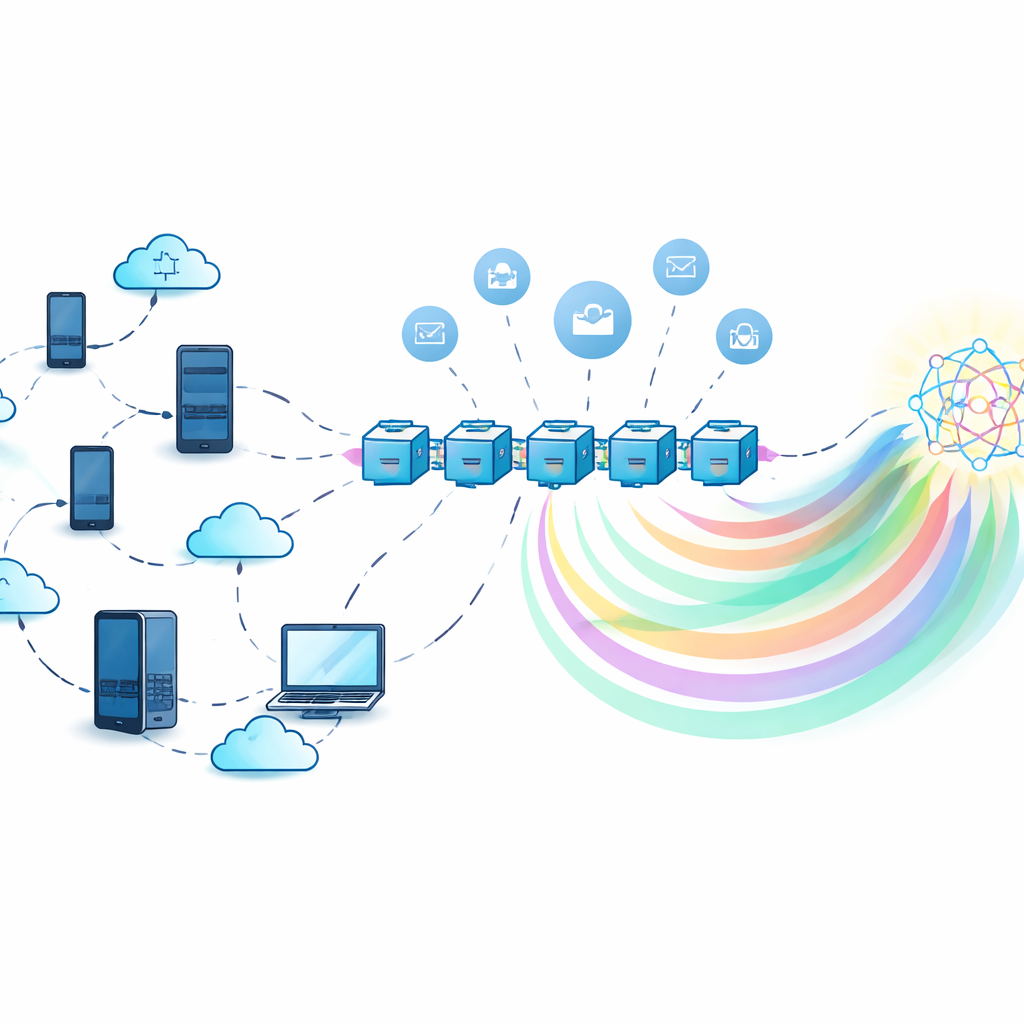
Gemeinsam trainieren, ohne Geheimnisse zu teilen
Beim klassischen föderierten Lernen sammelt ein zentraler Server Modellupdates vieler Teilnehmer und kombiniert sie. Das verhindert zwar das Versenden von Rohdaten, macht den Server aber selbst zu einem attraktiven Ziel: Bei Ausfall stockt das System, und ein unzuverlässiger Server kann Informationen aus Modellupdates missbrauchen oder preisgeben. Die Autoren nutzen stattdessen ein dezentrales Blockchain-Ledger zur Koordination des Trainings. Jeder Teilnehmer trainiert ein lokales Modell auf seinen eigenen Daten und interagiert dann mit Smart Contracts auf der Blockchain, die Beiträge protokollieren, Informationen aggregieren und Belohnungen verteilen — alles ohne Abhängigkeit von einer einzelnen zentralen Instanz.
Wissen teilen, nicht schwere Modelle
Um Kommunikationskosten zu senken und den Datenschutz weiter zu verbessern, setzt das Framework auf Knowledge Distillation. Anstatt vollständige Modellparameter zu verschicken, sendet jeder Teilnehmer nur „weiche Labels“ — die vorhergesagten Wahrscheinlichkeiten des Modells für eine Menge gemeinsamer Eingaben — die deutlich leichter sind und weniger über die Daten Einzelner verraten. Da oft kein echtes gemeinsames Datenset existiert, verwendet das System ein generatives Modell, einen bedingten variationalen Autoencoder, um ein synthetisches „pseudo-öffentliches“ Datenset zu erstellen, das ungefähr die Gesamtdistribution der Labels widerspiegelt, ohne originale Datensätze preiszugeben. Teilnehmer trainieren an ihren eigenen Daten, machen Vorhersagen auf diesem synthetischen Datensatz und verfeinern dann ihre Modelle mit einem aggregierten Signal, das aus dem kombinierten Wissen aller abgeleitet wird.
Ermessen, wer wirklich hilft
Eine zentrale Herausforderung in jedem kollaborativen System ist die Frage, wer Anerkennung verdient. IMFLKD begegnet dem mit einem zweistufigen Beitragsbewertungsverfahren basierend auf Label-Aggregation. Zuerst untersucht ein leichtgewichtiger Bayes-Algorithmus die Vorhersagen aller Teilnehmer und schätzt sowohl das wahrscheinlichste wahre Label für jede Probe als auch eine Qualitätsbewertung für jedes Modell, wobei diese Bewertungen mit eintreffenden Aufgaben fortlaufend aktualisiert werden. Dieser Ansatz arbeitet online, ohne vergangene Daten zu speichern, und geht mit lauten oder böswilligen Mitwirkenden um, indem Modelle, die häufig von der entstehenden Konsensmeinung abweichen, heruntergewichtet werden. Experimente zeigen, dass diese Label-Aggregation die Genauigkeit um etwa zehn Prozent gegenüber einfachem Mehrheitsvoting verbessert, während sie gleichzeitig schnell genug für großskalige, ressourcenbegrenzte Umgebungen bleibt.
Qualität in Belohnungen und Reputation umwandeln
Sobald die Beitragsqualität bekannt ist, verwendet IMFLKD ein Anreizschema namens gewichtetes Peer Truth Serum, um diese in Belohnungen zu überführen. Teilnehmer werden gegen einen qualitätsgewichteten Peer-Konsens verglichen: Wer mit qualitativ hochwertigen Peers übereinstimmt, erhält mehr, während Abweichler oder häufige Dissensierer bestraft werden. Das macht ehrliches Berichten zur langfristig profitabelsten Strategie, selbst bei Kollusion. Darüber hinaus baut das System einen mehrdimensionalen Reputationswert für jeden Teilnehmer auf, der Datenqualität, Aktivitätsniveau und Verhaltensstabilität kombiniert und älteres Verhalten mit einem Zeitverfallfaktor abschwächt. Reputation fließt dann in spätere Runden zurück, indem sie beeinflusst, wie viel Gewicht die Vorhersagen eines Teilnehmers haben und ob er für zukünftige Aufgaben ausgewählt wird.
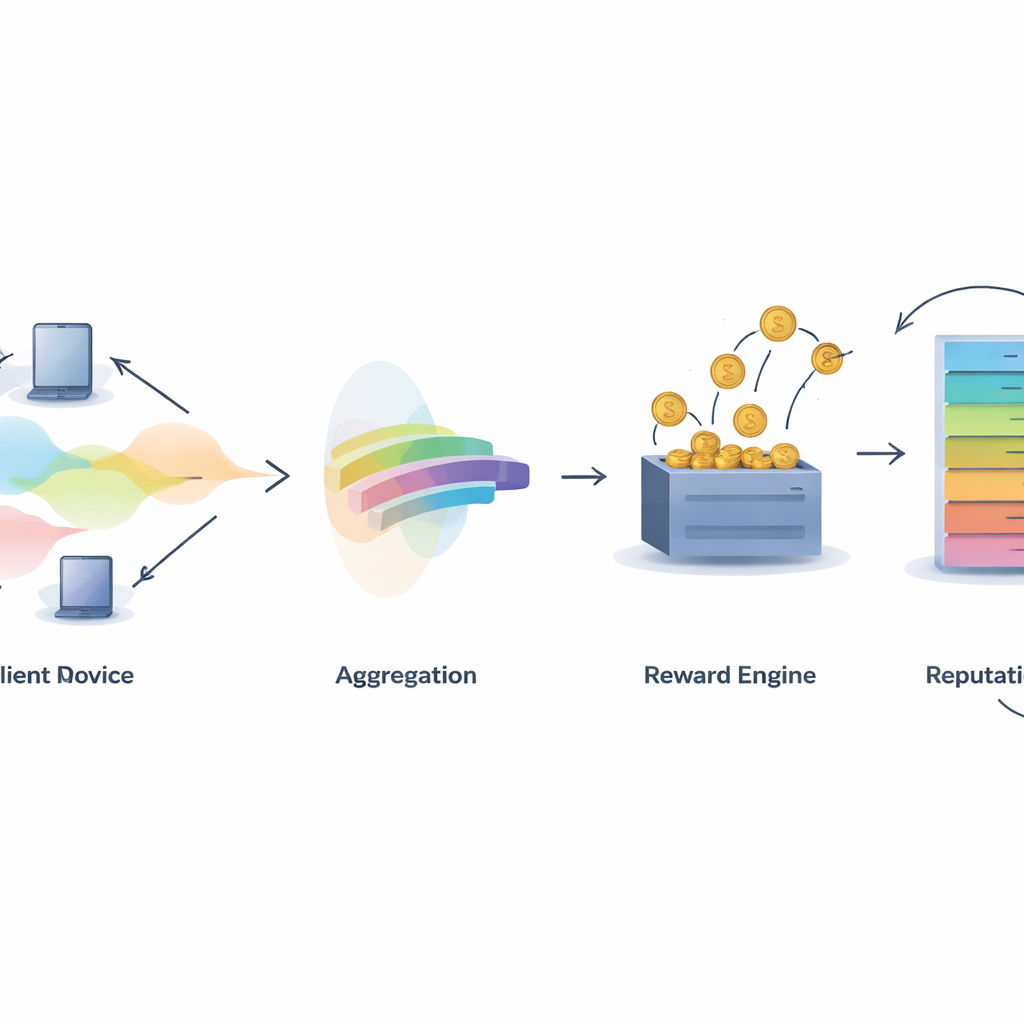
Vertrauen in kollektive Intelligenz aufbauen
Insgesamt zeigt das IMFLKD-Framework, dass es möglich ist, Lernen über viele unabhängige Geräte hinweg so zu koordinieren, dass es effizient, datenschutzbewusst und widerstandsfähig gegen Trittbrettfahrer und Angreifer ist. Durch die Kombination von synthetischer Datengenerierung, rigoroser Beitragsbewertung, spieltheoretischen Anreizen und dynamischem Reputations-Tracking auf einer Blockchain ermutigt das System Teilnehmer, über viele Trainingsrunden hinweg ehrlich und konsistent zu handeln. Für Laien lautet die Kernaussage: Wir können die kollektive Kraft verteilter Daten — etwa medizinischer Aufzeichnungen, Sensordaten oder persönlicher Geräte — nutzen, ohne alles einer einzigen Firma oder einem Server zu überlassen, und gleichzeitig sicherstellen, dass diejenigen, die die nützlichsten Informationen liefern, am meisten davon profitieren.
Zitation: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Schlüsselwörter: federiertes Lernen, Blockchain, Knowledge Distillation, Anreizmechanismen, Reputationssysteme