Clear Sky Science · de
PlantCLR: kontrastives selbstüberwachtes Pretraining für generalisierbare Pflanzenerkennung von Krankheiten
Warum klügeres Erkennen von Pflanzenkrankheiten wichtig ist
Pflanzenkrankheiten rauben still und heimlich Nahrungsmittel von den Tischen der Welt, verringern Erträge und schmälern die Einkommen von Landwirtinnen und Landwirten. In vielen Regionen stehen nur wenige ausgebildete Expertinnen und Experten zur Verfügung, um Probleme im Feld zu identifizieren, und ihre Hilfe kann langsam oder gar nicht erreichbar sein. Diese Studie stellt PlantCLR vor, ein Computersystem, das lernt, Krankheiten aus Fotos von Blättern mit deutlich weniger menschlich bereitgestellten Labels als üblich zu erkennen. Indem es automatisierte Diagnosen genauer, zuverlässiger und leichter auf einfacher Hardware einsetzbar macht, weist die Arbeit auf Smartphone- oder kostengünstige Kamerawerkzeuge hin, die Landwirtinnen und Landwirten helfen könnten, Probleme frühzeitig zu finden und ihre Ernten zu schützen.
Von Blattfotos zu Frühwarnungen
Heute werden viele Pflanzenkrankheiten noch auf traditionelle Weise diagnostiziert: Eine Person betrachtet ein Blatt und entscheidet, ob Flecken, Vergilbung oder Kräuseln Anzeichen einer Infektion sind. Dieses Urteil kann von Expertin zu Experte variieren und wird leicht durch Schatten, unruhige Hintergründe oder unterschiedliche Wachstumsstadien verfälscht. Auf Deep Learning basierende Computer-Vision-Systeme haben begonnen zu helfen, verlangen aber in der Regel viele Tausende sorgfältig gelabelter Fotos. In der Landwirtschaft sind solche gelabelten Bilder rar und teuer zu sammeln, während große Mengen unlabeled Aufnahmen von Mobiltelefonen und Feldkameras oft ungenutzt bleiben. PlantCLR ist darauf ausgelegt, diese unlabeled Daten zu nutzen und zu lernen, wie kranke und gesunde Blätter tendenziell aussehen, bevor es jemals ein Label sieht.
Ein Modell beibringen, durch Vergleichen zu lernen
PlantCLR baut auf einem neueren Ansatz namens kontrastives selbstüberwachtes Lernen auf, bei dem sich ein Modell durch den Vergleich von Bildern statt durch Labels selbst etwas beibringt. Zuerst nimmt das System ein unlabeled Blattbild und erzeugt zwei leicht unterschiedliche Versionen durch zufällige Ausschnitte, Spiegelungen, Farbverschiebungen oder Unschärfe. Diese beiden Versionen sollten eindeutig dasselbe Blatt repräsentieren, sodass das Modell darauf trainiert wird, sie als passendes Paar zu behandeln und ihnen ähnliche interne Repräsentationen zuzuweisen, während es die Repräsentationen verschiedener Blätter im selben Trainingsbatch auseinanderdrückt. Diese Pretraining-Phase nutzt ein kompaktes, aber modernes Bildverarbeitungs-Backbone namens ConvNeXt-Tiny, kombiniert mit einem kleinen zusätzlichen Modul, das nur während dieses lernens-durch-Vergleichen-Schritts verwendet wird. 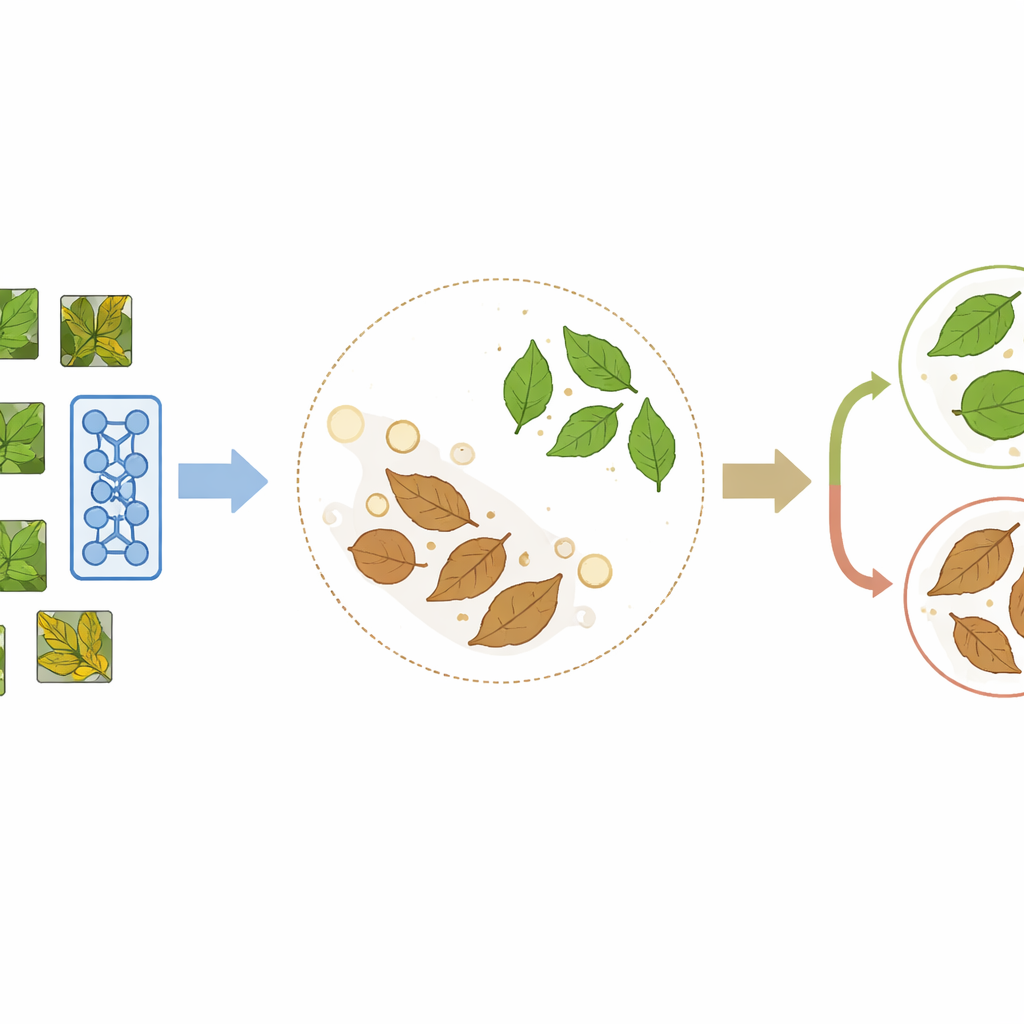
Das System auf die Probe stellen
Um zu prüfen, wie gut diese Strategie in der Praxis funktioniert, griffen die Autorinnen und Autoren auf zwei bekannte Blattdatensätze zurück, die sehr unterschiedliche reale Bedingungen nachahmen. Der PlantVillage-Datensatz enthält mehr als 54.000 Bilder von Blättern, die unter ordentlichen, kontrollierten Bedingungen fotografiert wurden, meist mit sauberem Hintergrund und klaren Symptomen über 38 Krankheits- und Kulturpflanzenklassen. Im Gegensatz dazu enthält der Cassava Leaf Disease-Datensatz etwa 21.000 Bilder von Maniokblättern, die direkt im Feld aufgenommen wurden, mit unruhigen Hintergründen, ungleichmäßiger Beleuchtung und Blättern, die sich überlagern oder in viele Richtungen verdrehen, verteilt auf fünf Klassen, darunter mehrere schwere Virus- und Bakterieninfektionen. Die Studie nutzt PlantVillage hauptsächlich als reichen Vorrat an unlabeled Bildern für das Pretraining und bewertet dann die Leistung sowohl auf diesem Datensatz als auch, noch wichtiger, auf den schwierigeren Feldaufnahmen der Maniokbilder.
Robuste Leistung unter wechselnden Bedingungen
PlantCLR erreichte 99,10 % Genauigkeit auf dem PlantVillage-Testset und 96,83 % Genauigkeit auf dem Cassava-Testset, mit ähnlich hohen F1-Werten, die zeigen, dass das Modell auch bei selteneren Krankheiten gut abschneidet. Diese Werte übertreffen eine Reihe bekannter Deep-Netzwerke, darunter DenseNet, ResNet, VGG und ein Vision-Transformer-Modell, die alle rein überwacht unter sorgfältig angeglichenen Bedingungen trainiert wurden. 
Warum dieser Ansatz ein Fortschritt ist
Für Nichtfachleute ist die Kernbotschaft: PlantCLR zeigt, wie eine Maschine zu einer fähigen Pflanzenärztin werden kann, indem sie zuerst aus großen Sammlungen unlabeled Bilder lernt und dann ihre Fähigkeiten mit einer kleineren, gelabelten Menge verfeinert. Diese Strategie erreicht nicht nur sehr hohe Genauigkeit, sondern hält auch gut stand, wenn die Kamera vom Labor ins Feld wechselt, wo die Bedingungen weitaus unordentlicher sind. Da das zugrunde liegende Modell relativ leichtgewichtig ist, könnte es schließlich auf erschwinglicher Hardware eingesetzt werden und damit fortgeschrittene Krankheitsdetektion für Landwirtinnen und Landwirte sowie Berater weltweit zugänglicher machen. Kurz gesagt: Die Studie demonstriert einen praktischen Weg zu skalierbaren, robusten und label-effizienten Werkzeugen zur Überwachung der Pflanzengesundheit, die dazu beitragen könnten, die Nahrungsmittelversorgung zu sichern.
Zitation: Shah, S.S.A., Saeed, F., Raza, M.U. et al. PlantCLR: contrastive self-supervised pretraining for generalizable plant disease detection. Sci Rep 16, 10550 (2026). https://doi.org/10.1038/s41598-026-45684-x
Schlüsselwörter: Erkennung von Pflanzenkrankheiten, selbstüberwachtes Lernen, kontrastives Lernen, landwirtschaftliche KI, Überwachung der Pflanzen Gesundheit