Clear Sky Science · de
Hybrides evolutionär‑gradientenbasiertes Training verbessert Langfrist‑Zeitreihenprognosen
Warum bessere Langfrist‑Prognosen wichtig sind
Von Strombedarf und Autobahnverkehr bis zu Wechselkursen und lokalem Wetter — unser Alltag wird von Systemen geprägt, die sich im Laufe der Zeit verändern. Muster Tage oder Wochen im Voraus zuverlässig vorherzusagen, kann Energie sparen, Staus verringern und Unternehmen widerstandsfähiger machen. Je weiter wir jedoch in die Zukunft blicken, desto schwieriger fällt es den heutigen KI‑Werkzeugen, mit sich verschiebenden Bedingungen, verrauschten Messwerten und begrenzten Rechenbudgets zurechtzukommen. Dieses Paper stellt eine neue Trainingsmethode für Prognosemodelle vor, damit sie auch dann genau und stabil bleiben, wenn die Welt sich nicht ruhig verhält.
Von einem Modell zu vielen lernen
Die meisten modernen Zeitreihen‑Prognosemodelle basieren auf einem einzelnen tiefen neuronalen Netz, das mit Gradientenabstieg trainiert wird — die Standardmethode, die Modellparameter schrittweise zur Fehlerreduzierung anpasst. Das funktioniert gut, wenn sich die Daten konsistent verhalten, kann aber versagen, wenn sich die Bedingungen verschieben, Messungen verrauscht sind oder die Trainingszeit knapp ist. Statt ein neues Netzdesign zu erfinden, schlagen die Autoren Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR) vor, ein Trainingsframework, das um bestehende Architekturen gelegt werden kann. Die Kernidee ist, eine kleine "Population" von Modellen zu unterhalten, die zwar dieselbe Struktur teilen, aber von unterschiedlichen Zufallsschnitten starten. Während des Trainings erkunden diese Modelle verschiedene Wege, die Daten zu modellieren, und das derzeit am besten performende Modell wird genutzt, um Verbesserungen in den anderen zu steuern.
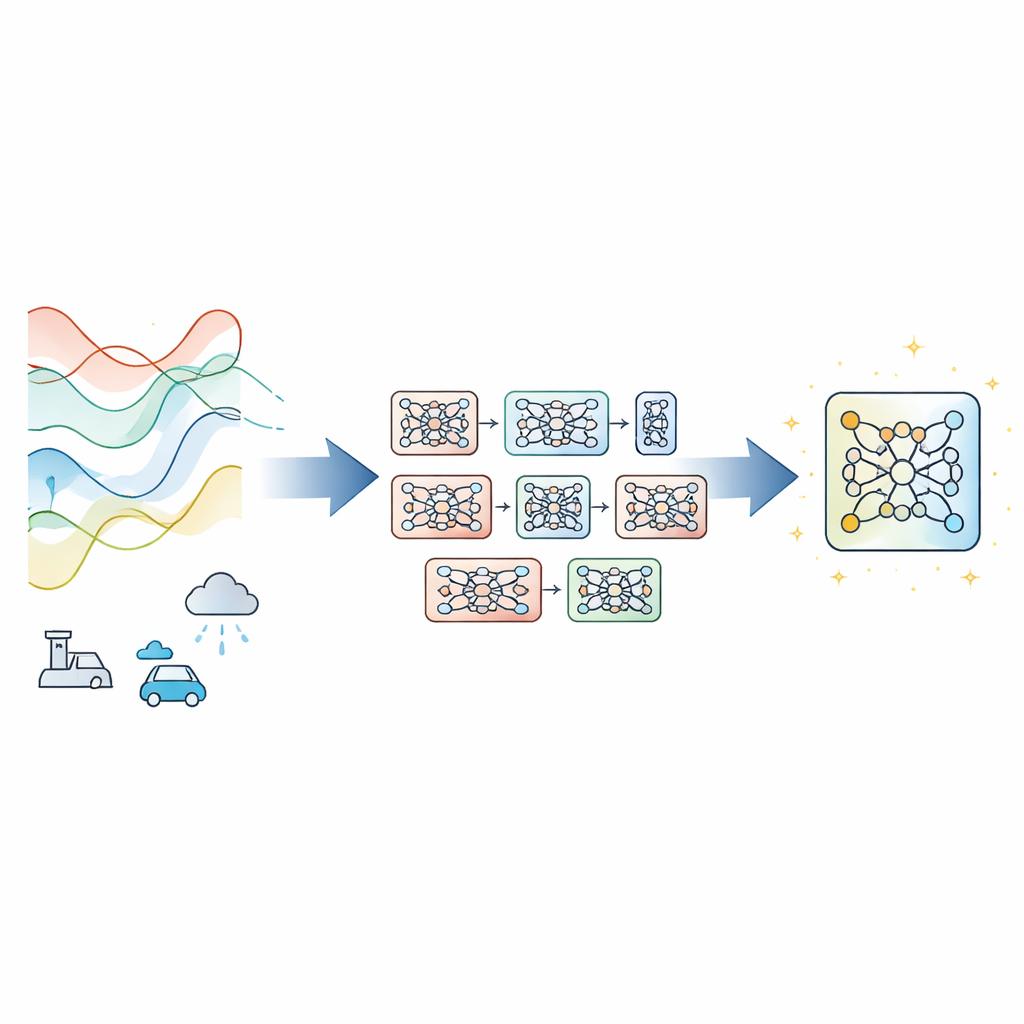
Gute Teile übernehmen und gleichzeitig nützliche Vielfalt bewahren
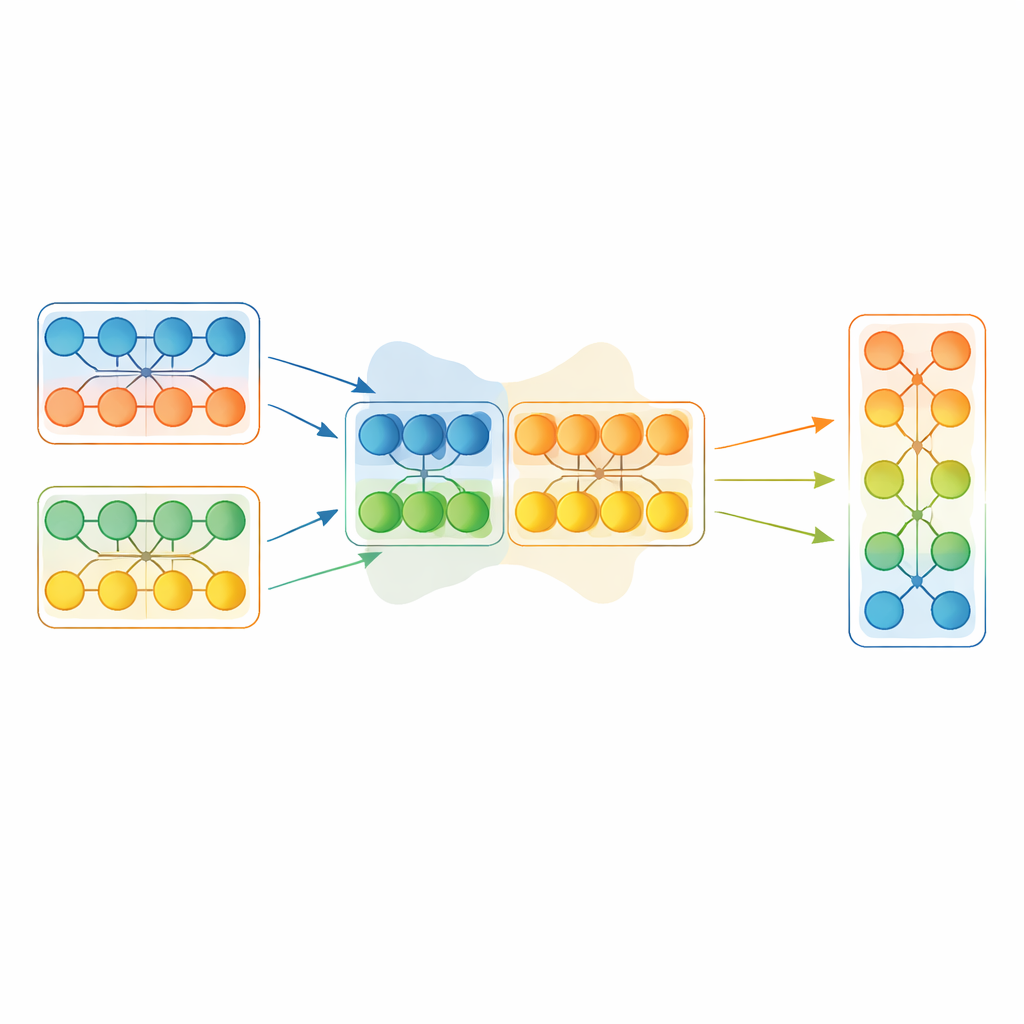
Anstatt ein gesamtes Sieger‑Modell eins zu eins zu kopieren, arbeitet EGMF‑GR auf Modulebene — wiederkehrende Bausteine innerhalb eines Netzes, etwa Schichtstapel. Für jedes Modell in der Population ordnet das Framework die entsprechenden Module dem aktuellen Bestmodell zu und vergleicht deren interne Signale, während sie denselben Eingabebatch verarbeiten. Es verwendet mehrere einfache Differenzmaße, die sowohl die Form der Aktivitätsmuster als auch deren Größe erfassen. Diese modul‑weisen Abweichungen werden dann zusammengefasst; nur Module, deren Verhalten gegenüber ihren Konkurrenten als deutliche Ausreißer erscheint, kommen für ein Update in Frage. In diesem Fall wird das zurückliegende Modul durch eine gewichtete Mischung seiner Parameter mit dem entsprechenden Modul des Bestmodells in Richtung dieses Vorbildes gedrängt, ergänzt um ein kleines zufälliges Rauschen, um die Diversität zu erhalten.
Gradienten lassen die großen Schritte nachziehen
Das Zusammenführen von Teilen aus verschiedenen Netzen kann abrupte Änderungen einführen. Um das Training nicht zu destabilisieren, durchläuft jedes fusionierte Modell anschließend eine kurze, konventionelle Gradientenabstiegsphase auf den Trainingsdaten. Dieser Verfeinerungsschritt erlaubt dem Netz, sich glatt an seine neue interne Konfiguration anzupassen und gleichzeitig die Vorteile des übernommenen Wissens zu bewahren. Das Gesamtverfahren wechselt ab: Auswahl des aktuellen Bestmodells basierend auf einem zurückgehaltenen Datenschnitt, selektive Fusion von Modulen dieses Leaders in den Rest der Population und kurzes Feinabstimmen aller Modelle mit Gradienten. Entscheidend ist auch die Synchronisation interner Buchführungszustände, wie etwa laufender Mittelwerte bestimmter Schichten, die in einfacheren Modellzusammenführungs‑Schemata oft ignoriert werden, sich aber stark auf die Stabilität auswirken können.
Die Vorteile an vielen realen Signalen nachweisen
Zur Evaluierung wendeten die Autoren EGMF‑GR auf mehrere gängige Prognoserückgrate an, darunter Transformer‑ähnliche Modelle und ein jüngeres, auf Faltungen beruhendes Design, ohne deren Kernstrukturen zu verändern. Sie testeten die Leistung auf acht öffentlichen Benchmarks aus den Bereichen Energieverbrauch, Verkehrsfluss, Wechselkurse und Wetter sowie über mehrere Prognosehorizonte von einigen Stunden bis zu mehreren Tagen. Bei einem strikt vergleichbaren Budget an teuren Backward‑Pass‑Updates reduzierte das hybride Training konstant die Vorhersagefehler und glättete das Trainingsverhalten für die meisten Modell‑Datensatz‑Kombinationen, besonders in hochdimensionalen oder verrauschten Szenarien. Das Team verglich seinen Ansatz außerdem mit üblichen Einzelmodell‑Tricks wie exponentiellen gleitenden Durchschnitten und stochastischem Gewichtsmittel und fand, dass die populationsbasierte Modulfusion zusätzliche Vorteile gegenüber einfachem Gewichtssmoothing bietet.
Zuverlässig bleiben, wenn die Bedingungen schlecht werden
Reale Systeme verhalten sich selten wie saubere Lehrbuchbeispiele, weshalb die Autoren die Robustheit auch unter härteren Szenarien testeten: künstlich korrumpierte Eingaben, fehlende Datenabschnitte und Perioden mit abrupt geänderten Dynamiken. EGMF‑GR half deutlich, wenn Eingaben verrauscht oder teilweise fehlend waren, was nahelegt, dass das Übernehmen stabiler Modulverhalten vom aktuellen Bestmodell lokale Störungen ausgleichen kann. Bei plötzlichen Regimewechseln war der Vorteil kleiner, was andeutet, dass zu starke Angleichung manchmal die Anpassung an neue Muster verlangsamen kann. Das spricht für künftige Verfeinerungen, bei denen die Stärke der Fusion zurückgefahren wird, sobald die Umgebung sehr volatil wird.
Was das für alltägliche Prognosewerkzeuge bedeutet
Kurz gesagt zeigt die Studie, dass das Training vieler zusammenarbeitender Versionen desselben Prognosemodells und das Teilen nur der Teile, die wirklich als besser herausstechen, Langfrist‑Vorhersagen genauer und stabiler machen kann, ohne die Modelle selbst neu zu entwerfen. EGMF‑GR funktioniert wie ein diszipliniertes Teamsport‑Prinzip: Mitglieder übernehmen gelegentlich die stärksten Züge der anderen und üben dann kurz eigenständig, um sich an das aktuelle Spiel anzupassen. Für Praktiker bietet dies eine Plug‑in‑Trainingsstrategie, die bestehende Prognosesysteme in Bereichen wie Finanzen, Energie, Verkehr und Klima stärken kann, insbesondere wenn Daten unordentlich sind und das Rechenbudget knapp ist.
Zitation: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Schlüsselwörter: Zeitreihenprognose, evolutionäres Training, neuronale Netze, Modellfusion, Verteilungsverschiebung