Clear Sky Science · de
Multi-Ebenen-Vision-Transformer zur Klassifizierung von Blutungen mittels axialer und sagittaler MRT-Daten
Warum diese Forschung für Patientinnen, Patienten und Ärztinnen und Ärzte wichtig ist
Bei Verdacht auf Schlaganfall oder Hirnblutung zählt jede Minute. Bildgebende Untersuchungen können gefährliche Blutungen zeigen, doch das schnelle und präzise Lesen dieser Aufnahmen ist anspruchsvoll, besonders bei Magnetresonanztomographie (MRT), die viele Bildtypen aus verschiedenen Blickwinkeln liefert. Diese Studie stellt eine neue Methode der künstlichen Intelligenz (KI) vor, die Multi‑Winkel‑MRTs eher so interpretiert wie ein erfahrener Radiologe, mit dem Ziel, Hirnblutungen unter realen Krankenhausbedingungen zuverlässiger zu erkennen.
Die Herausforderung, Hirnblutungen in der MRT zu finden
Intrakranielle Blutungen — Blutungen innerhalb des Schädels — sind ein lebensbedrohlicher Notfall, der eine schnelle Diagnosestellung erfordert. Jahrzehntelang war die Computertomographie (CT) das Standardverfahren bei Verdacht auf Hirnblutung, da sie schnell ist und relativ einfach zu beurteilen. Die MRT kann CT bei der Detektion von Blutungen mindestens ebenbürtig oder überlegen sein und bietet zudem bessere Informationen zum Alter der Blutung sowie zu anderen Befunden wie durchblutungsarme Hirnareale. Allerdings dauert eine MRT länger, ist in manchen Zentren weniger verfügbar und ihre Bilder sind komplexer zu interpretieren. Diese Komplexität macht MRT zu einem attraktiven Anwendungsfeld für KI‑Tools, die Radiologinnen und Radiologen beim Screening vieler Aufnahmen unterstützen, verdächtige Fälle markieren und das Risiko verringern können, dass eine subtile, aber kritische Blutung übersehen wird.
Warum mehrere Blickrichtungen und Sequenzen für Computer schwierig sind
In der Routine werden Hirn‑MRTs oft mit relativ dicken Schichten aufgenommen, um die Untersuchung kurz zu halten; dadurch sind die Bilder in manchen Richtungen deutlich schärfer als in anderen. Radiologinnen und Radiologen betrachten das Gehirn in mehreren Ebenen — axial (von oben), sagittal (Seitenansicht) und manchmal koronal (Frontalansicht) — weil manche Blutungen aus bestimmten Blickwinkeln besser sichtbar sind. Zudem gibt es verschiedene Bildkontraste oder Sequenzen wie FLAIR, Diffusion und Suszeptibilität, die jeweils unterschiedliche Gewebeeigenschaften hervorheben. Die meisten aktuellen KI‑Systeme erwarten jedoch, dass alle Bilder in einer einheitlichen Standardorientierung und Auflösung vorliegen. Um das zu erreichen, müssen Krankenhäuser die Daten digital drehen und skalieren, was feine Details verwischen und kleine Blutungen verbergen kann. Reale klinische Datensätze bringen eine weitere Komplikation: Nicht bei allen Patientinnen und Patienten werden dieselben Sequenzen aufgenommen, sodass Modelle mit fehlenden Informationen umgehen müssen.
Ein neuer Multi‑Ebenen‑KI‑Ansatz, der mehr vom Bild erhält
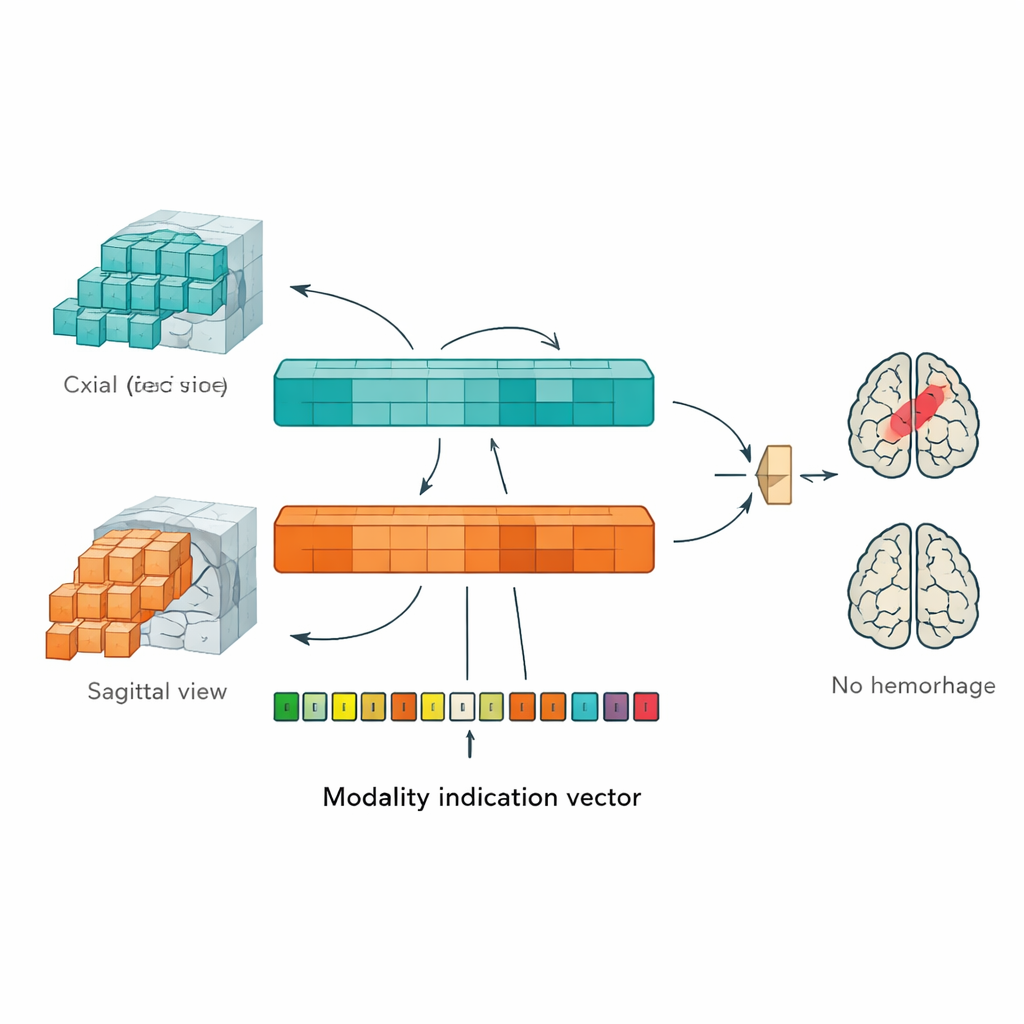
Um diese Probleme anzugehen, entwickelten die Autorinnen und Autoren einen „Multi‑Plane Vision Transformer“ (MP‑ViT), eine Form von KI, die ursprünglich für das Verständnis natürlicher Bilder konzipiert wurde. Anstatt alle MRT‑Daten in eine Blickrichtung zu pressen, verfügt MP‑ViT über zwei dedizierte Verarbeitungszweige: einen für axiale und einen für sagittale Bilder. Jeder Zweig unterteilt das dreidimensionale Gehirn in kleine Blöcke, wandelt diese in Tokens um, die der Transformer verarbeiten kann, und lernt dann Muster, die auf das Vorhandensein einer Blutung hinweisen könnten. Entscheidenderweise laufen diese Zweige nicht einfach parallel und isoliert. Das Modell nutzt einen Cross‑Attention‑Mechanismus, der den beiden Zweigen den Informationsaustausch ermöglicht und so imitiert, wie ein Radiologe Ansichten aus verschiedenen Blickwinkeln mental kombiniert, um ein klareres Gesamtbild des Gehirns zu erhalten.
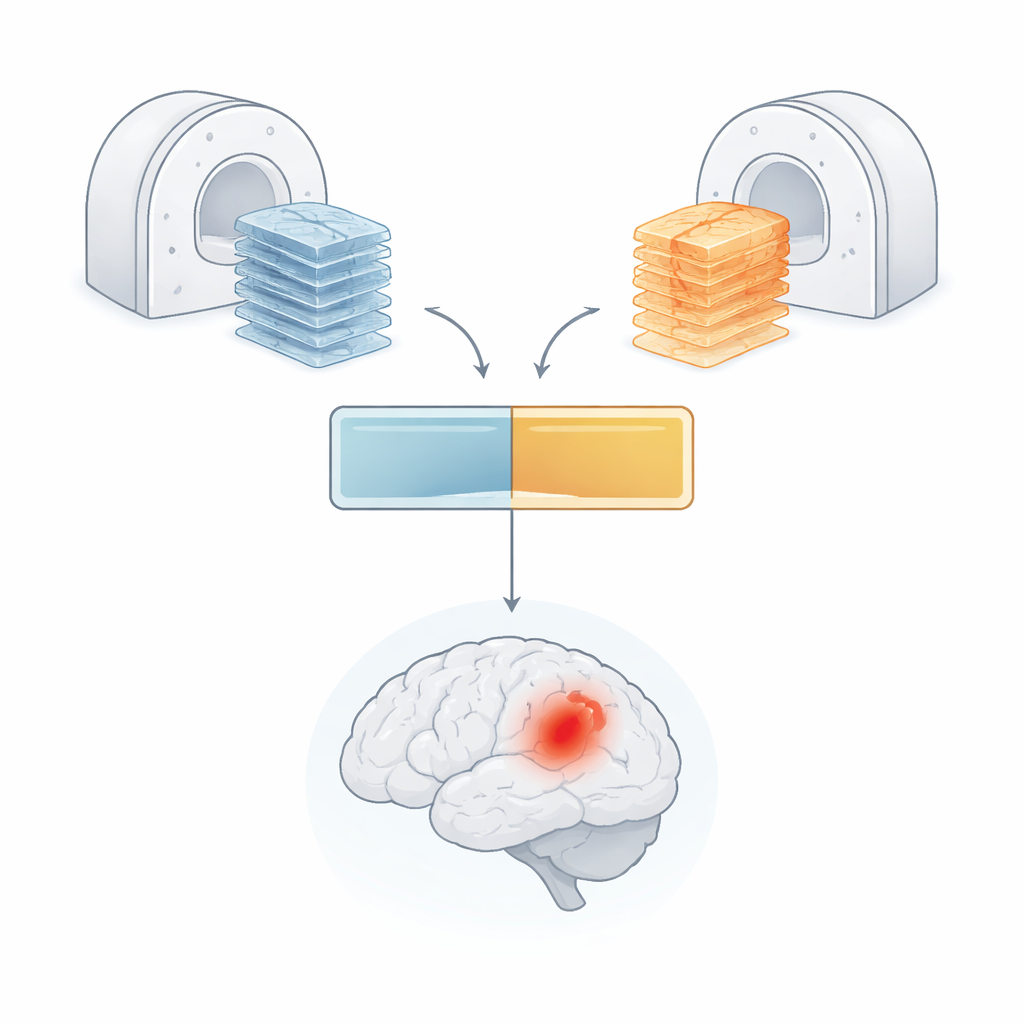
Umgang mit fehlenden Sequenzen durch ein Hinweis‑Signal
In realen klinischen Abläufen liegen nicht bei allen Patientinnen und Patienten dieselben MRT‑Sequenzen vor; manche fehlen beispielsweise empfindlichkeitssteigernde Sequenzen für Blutungen. Um die KI gegenüber solchen Lücken robust zu machen, fügten die Autorinnen und Autoren einen „Modalitäts‑Indikationsvektor“ hinzu — einen einfachen Code, der dem Modell signalisiert, welche Bildtypen vorhanden bzw. fehlen. Dieser Vektor wird in interne Signale überführt, die über einen zusätzlichen Cross‑Attention‑Schritt mit den gelernten Merkmalen des Modells interagieren. Effektiv wird das Netz so geleitet, seine Erwartungen anzupassen, wenn bestimmte Informationsarten nicht verfügbar sind, anstatt verwirrt oder übermäßig sicher zu sein. Dieses Design macht MP‑ViT besser geeignet für die unordentlichen, inkonsistenten Daten des klinischen Alltags.
Wie gut die neue Methode abschneidet
Die Forschenden trainierten und testeten MP‑ViT an einem großen, realen Datensatz mit über 12.000 MRT‑Studien von drei großen Geräteherstellern, die von erfahrenen Radiologinnen und Radiologen als akut oder subakut intrakraniell blutend bzw. nicht blutend gelabelt wurden. Auf einem unabhängigen Testset erzielte MP‑ViT eine Fläche unter der Kurve (AUC) von 0,854 — ein Maß dafür, wie gut zwischen Blutungs‑ und Nicht‑Blutungsfällen über alle Entscheidungsschwellen hinweg unterschieden wird. Dieser Wert lag deutlich über dem eines Standard‑Vision‑Transformers, der nur aus einer Ebene arbeitete, sowie über mehreren bekannten Convolutional‑Network‑Architekturen wie ResNet und DenseNet. Statistische Tests bestätigten, dass diese Verbesserungen kaum zufällig sind. Eine interne Analyse zeigte zudem, dass das Hinzunehmen des Modalitäts‑Indikationsvektors die Leistung um mehr als einen Prozentpunkt steigerte, was den Nutzen der expliziten Information darüber, welche Sequenzen vorhanden sind, unterstreicht.
Was das für die zukünftige Versorgung bedeuten könnte
Für Nicht‑Fachleute lautet die Kernaussage: Diese Studie zeigt einen intelligenteren Weg für KI, MRT‑Aufnahmen zu lesen — sie betrachtet das Gehirn aus mehreren Blickwinkeln, erhält mehr ursprüngliche Details und passt sich an, wenn bestimmte Bildtypen fehlen. Obwohl die Arbeit an einem einzelnen internen Datensatz evaluiert wurde und sich auf die Klassifikation statt auf die präzise Markierung von Blutungen konzentrierte, zeigt sie, dass sorgfältig entworfene Transformer besser zur unordentlichen Realität klinischer Bildgebung passen können. Bei breiterer Validierung und verantwortungsvoller Integration in Klinikabläufe könnten Verfahren wie MP‑ViT Radiologinnen und Radiologen helfen, Hirnblutungen sowohl in Notfallsituationen bei Schlaganfall als auch in routinemäßigen ambulanten Untersuchungen zuverlässiger zu erkennen — potenziell mit schnellerer Behandlung und sichereren Ergebnissen für Patientinnen und Patienten.
Zitation: Das, B.K., Zhao, G., Mailhe, B. et al. Multi-plane vision transformer for hemorrhage classification using axial and sagittal MRI data. Sci Rep 16, 9333 (2026). https://doi.org/10.1038/s41598-026-44524-2
Schlüsselwörter: Hirnblutung, MRT, KI in der medizinischen Bildgebung, Vision Transformer, Schlaganfall-Diagnostik