Clear Sky Science · de
Kontext-Engineering neu denken mit einer auf Aufmerksamkeit basierenden Architektur
Warum klügere Softwarehelfer wichtig sind
Jeder Klick in einer Business-Anwendung — Anmeldung, Hochladen einer Datei, Ausführen eines Berichts — hinterlässt eine Spur. Könnte Software zuverlässig Ihren nächsten Schritt vorhersagen, könnte sie Daten vorladen, Abkürzungen vorschlagen und nahezu sofort reagieren. Dieses Papier untersucht eine neue Methode, Computern diese Handlungsspuren so gut beizubringen, dass digitale Assistenten antizipieren können, was Sie als Nächstes tun werden, welches Ziel Sie verfolgen und wann Sie kurz davor sind, sich abzumelden.
Von einfachen Ketten zu komplexen Mustern
Viele bestehende Systeme, die den nächsten Schritt eines Nutzers erraten, beruhen auf Markow-Ketten, einem klassischen mathematischen Werkzeug, das nur die unmittelbar letzte Aktion betrachtet, um die nächste vorherzusagen. Zwar schnell und praktisch, versagt dieser „Ein-Schritt-Erinnerung“-Ansatz in realen Arbeitsumgebungen, in denen Aufgaben wie der Aufbau einer Machine-Learning-Pipeline oder die Vorbereitung eines Dashboards sich über viele Schritte und verschiedene Werkzeuge erstrecken. Die Autorinnen und Autoren argumentieren, dass solche einfachen Modelle langfristige Strukturen übersehen, jeweils nur ein Vorhersageziel behandeln können und schwer vergleichbar sind, weil sie meist auf privaten Logs und undurchsichtigen Datenbereinigungsentscheidungen beruhen.
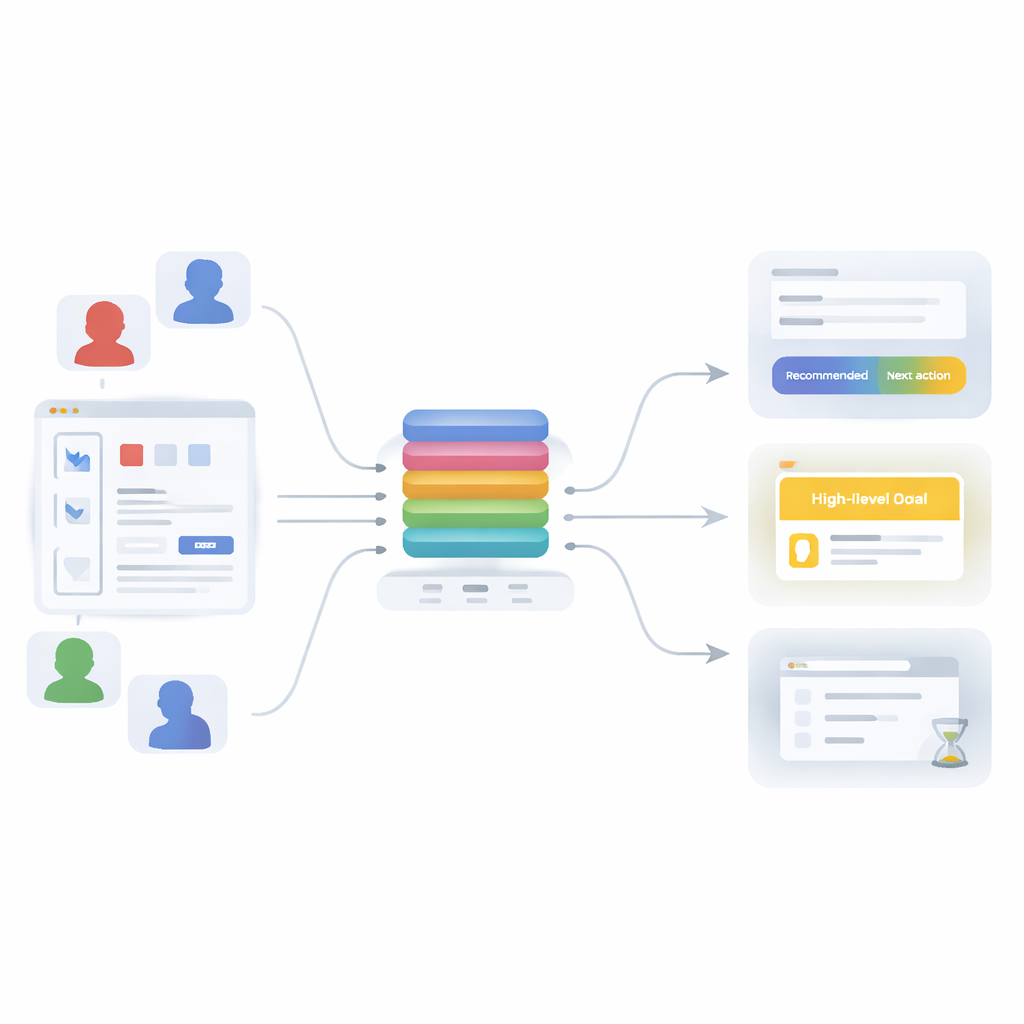
Ein neues Multi-Task-Learning-Konzept
Um diese Grenzen zu überwinden, führt das Papier ein auf Aufmerksamkeit basierendes Transformer-Modell ein — die gleiche Technikfamilie, die modernen Sprachwerkzeugen zugrunde liegt — neu gedacht für Nutzerverhalten. Anstatt nur eine Sache zu lernen, wird das Modell darauf trainiert, drei verwandte Aufgaben gleichzeitig zu lösen: die nächste Aktion vorherzusagen (welche API ein Nutzer aufruft), das übergeordnete Ziel der Sitzung zu erschließen (etwa eine Machine-Learning-Workflow auszuführen, Daten zu analysieren, Nutzer zu verwalten oder schnelle Visualisierungen zu erstellen) und zu entscheiden, ob der aktuelle Schritt wahrscheinlich der letzte in der Sitzung ist. Alle drei Aufgaben teilen ein gemeinsames „Rückgrat“, das eine kurze Historie jüngerer Aktionen in eine einzige, reiche Repräsentation des laufenden Kontexts verwandelt, die anschließend in drei kleine Vorhersagemodule eingespeist wird.
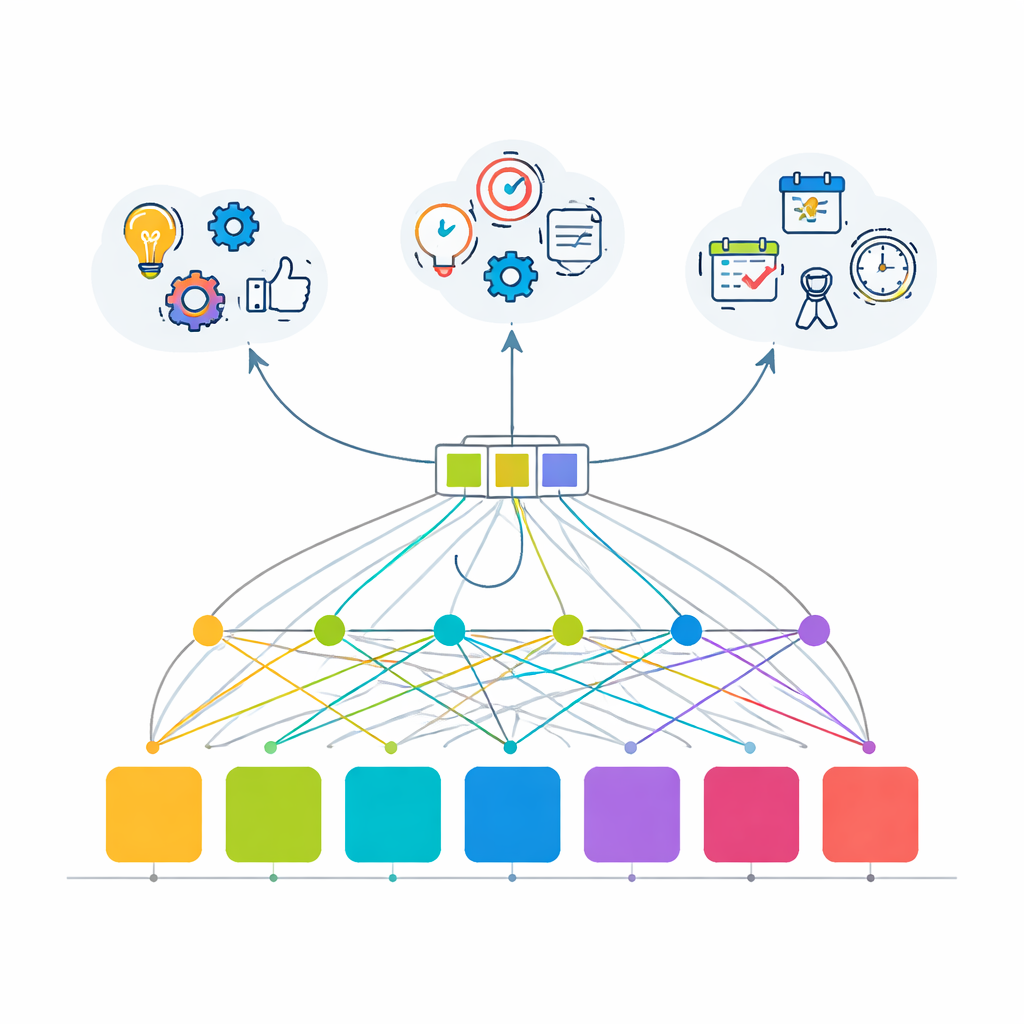
Aufbau eines realistischen Testfelds in Silico
Da echte Unternehmens-Activity-Logs oft sensibel und schwer zu teilen sind, bauen die Autorinnen und Autoren eine anspruchsvolle simulierte Umgebung, die nachahmt, wie Datenfachleute eine große interne Plattform nutzen. Sie definieren 100 unterschiedliche APIs, gruppiert in 10 Funktionsbereiche, darunter Authentifizierung, Dateneingabe, Verarbeitung, Modelltraining, Visualisierung, Export und Administration. Vier Nutzer-Personas — Data Scientists, Business Analysts, Entwickler und Power-User — folgen charakteristischen, aber nicht perfekten Workflows, mit Wahrscheinlichkeiten, die sowohl routinemäßiges Verhalten als auch gelegentliche Umwege abbilden. Der resultierende Datensatz enthält 2.000 Nutzersitzungen und 20.000 API-Aufrufe, wobei Sitzungsziele wie „Machine-Learning-Pipeline“ und „schnelle Visualisierung“ erkennbare Pfade produzieren, etwa Einloggen, Laden von Daten, Verarbeitung, Erstellen eines Diagramms und Export des Ergebnisses.
Wie gut das Modell antizipiert
Trainiert in dieser strukturierten, aber vielfältigen Umgebung zeigt das Transformer-Modell, dass auf Aufmerksamkeit basierendes Lernen versteckte Regelmäßigkeiten im Nutzerverhalten deutlich besser erfassen kann als ältere Methoden. Für die Hauptaufgabe — den nächsten API-Aufruf unter 100 Möglichkeiten zu erraten — liegt die exakte Trefferquote bei fast 80 %, und die korrekte Wahl befindet sich in mehr als 99,9 % der Fälle unter den fünf besten Vorschlägen, ein mehr als vierfacher Zuwachs gegenüber einer einfachen Markow-Kette. Gleichzeitig identifiziert es das übergeordnete Sitzungsziel in etwa 82 % der Fälle korrekt und erkennt nahezu perfekt, wenn eine Sitzung kurz vor dem Ende steht. Die Autorinnen und Autoren heben außerdem hervor, dass das Modell relativ kompakt und effizient ist, was den Echtzeiteinsatz für Live-Assistenten, die ohne spürbare Verzögerung reagieren müssen, praktikabel macht.
Werkzeuge zur Wiederverwendung und Erweiterung
Um ihren Ansatz über ein einmaliges Experiment hinaus nutzbar zu machen, veröffentlichen die Autorinnen und Autoren ein Open-Source-Softwarepaket namens context-engineer sowie den vollständigen simulierten Datensatz. Mit diesen Ressourcen können andere Forschende und Praktiker die berichteten Ergebnisse reproduzieren, alternative Modelle an einem gemeinsamen Benchmark testen oder eigene interne Logs einbinden, indem sie Aktionen und Sitzungslabels in ein einfaches numerisches Format überführen. Diese Offenheit adressiert ein zentrales Hindernis im Feld, in dem viele frühere Systeme nicht fair verglichen oder wiederverwendet werden konnten, weil ihre Daten und ihr Code nicht verfügbar waren.
Was das für Alltagsnutzer bedeutet
Für Nicht-Fachleute lautet die Kernbotschaft: Das Papier liefert ein praktikables Rezept, damit sich digitale Werkzeuge „einen Schritt voraus“ anfühlen. Indem es gemeinsam lernt, was Menschen zu tun versuchen, worauf sie wahrscheinlich als Nächstes klicken und wann sie gerade abschließen, verwandelt das vorgeschlagene transformerbasierte System Nutzerhistorien in eine Form von Kontextbewusstsein. In echten Anwendungen könnte das bedeuten: Chatbots, die den nächsten Bericht bereitmachen, bevor Sie danach fragen; Analyseplattformen, die sinnvolle Folgeaktionen vorschlagen; und Unternehmens-Dashboards, die Wartezeiten unauffällig verkürzen. Obwohl die aktuelle Studie auf simulierten Daten basiert und noch an echten Logs getestet werden muss, legt sie eine klare, reproduzierbare Grundlage für den Aufbau klügerer, vorausschauender Softwarehelfer auf vielen digitalen Plattformen.
Zitation: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Schlüsselwörter: Vorhersage des Nutzerverhaltens, sequentielle Empfehlung, auf Aufmerksamkeit basierender Transformer, proaktive digitale Assistenten, Kontext-Engineering