Clear Sky Science · de
Bekämpfung des Datenungleichgewichts bei der maschinellen Modellierung seltener und schwerwiegender Ausfallereignisse
Warum bessere Sturmvorhersagen für Sie wichtig sind
Wenn ein schwerer Sturm die Stromversorgung unterbricht, trifft uns das auf sehr persönliche Weise: kein Licht, keine Heizung, verdorbene Lebensmittel und unterbrochene Kommunikation. Versorgungsunternehmen versuchen, diese Ausfälle im Voraus vorherzusagen, um Reparaturteams zu planen und Menschen zu schützen. Die schwersten Stürme sind jedoch selten, sodass überraschend wenig Daten über sie vorliegen. Diese Studie zeigt, wie eine neue Form künstlicher Intelligenz realistische, seltene Stürme „erfinden“ kann, Lücken in unseren Aufzeichnungen schließt und Ausfallvorhersagen genau dort verbessert, wo es am wichtigsten ist.
Die Herausforderung, aus seltenen Katastrophen zu lernen
Die meisten Stromausfälle werden durch Wetterereignisse verursacht, insbesondere Hurrikane, Nor’easter, Schnee‑ und Eisstürme sowie schwere Gewitter. Diese Ereignisse werden mit der Erwärmung des Klimas intensiver und belasten alternde Stromnetze zusätzlich. Die verheerendsten Stürme sind jedoch definitionsgemäß selten. Traditionelle statistische Werkzeuge und Machine‑Learning‑Modelle lernen in der Regel am besten aus den zahlreichen milden und mäßigen Stürmen und tun sich mit den wenigen wirklich extremen Fällen schwer. Dieses Ungleichgewicht in den Daten führt zu Unterschätzungen der Schäden gerade dann, wenn Versorger am dringendsten verlässliche Einschätzungen benötigen.
Computern das Erzeugen neuer Stürme beibringen
Um dieses Ungleichgewicht zu überwinden, entwickeln die Autoren ein System, das synthetische Stürme erzeugt — also computergenerierte Ereignisse, die wie reale Stürme aussehen und sich so verhalten, aber keine Kopien einzelner vergangener Ereignisse sind. Sie konzentrieren sich auf Connecticut und stellen jeden Sturm als Gitter aus 815 Zellen dar, wobei jede Zelle 19 Informationsarten enthält, darunter Wind, Regen, Druck, Turbulenz, Vegetation und Leitungsführung. Zunächst gruppieren sie 294 historische Stürme in 12 Cluster, basierend darauf, wie viele und an welchen Stellen „Problemstellen“ — Schadensorte, die Reparaturteams anfahren müssen — auftraten. Die seltenen, hochwirksamen Stürme landen in vier kleinen Clustern, die verstärkt werden müssen.
Wie das neue KI‑Modell realistische Extreme erzeugt
Der Kern des Frameworks kombiniert zwei moderne KI‑Werkzeuge. Ein variationaler Autoencoder komprimiert jede mehrschichtige Sturmkartierung in eine nieder‑dimensionale „latente“ Repräsentation, die dennoch wichtige Muster bewahrt, etwa stärkere Winde an der Küste. In diesem komprimierten Raum lernt ein Diffusionsmodell, aus Rauschen zu beginnen und es schrittweise zu einem realistischen Sturm zu verfeinern, konditioniert auf das gewünschte Ausfall‑Schweregrad‑Cluster. Das System sichtet die erzeugten Stürme anschließend mit einer Reihe von Metriken, die ihre Statistik mit realen Ereignissen vergleichen — geprüft werden nicht nur einzelne Merkmale wie Windstärke, sondern auch, wie Merkmale zusammen auftreten, erfasst durch Korrelationsmuster. Nur synthetische Stürme, die das physikalische und statistische Verhalten realer Stürme in einem gegebenen Cluster eng nachbilden, werden behalten.
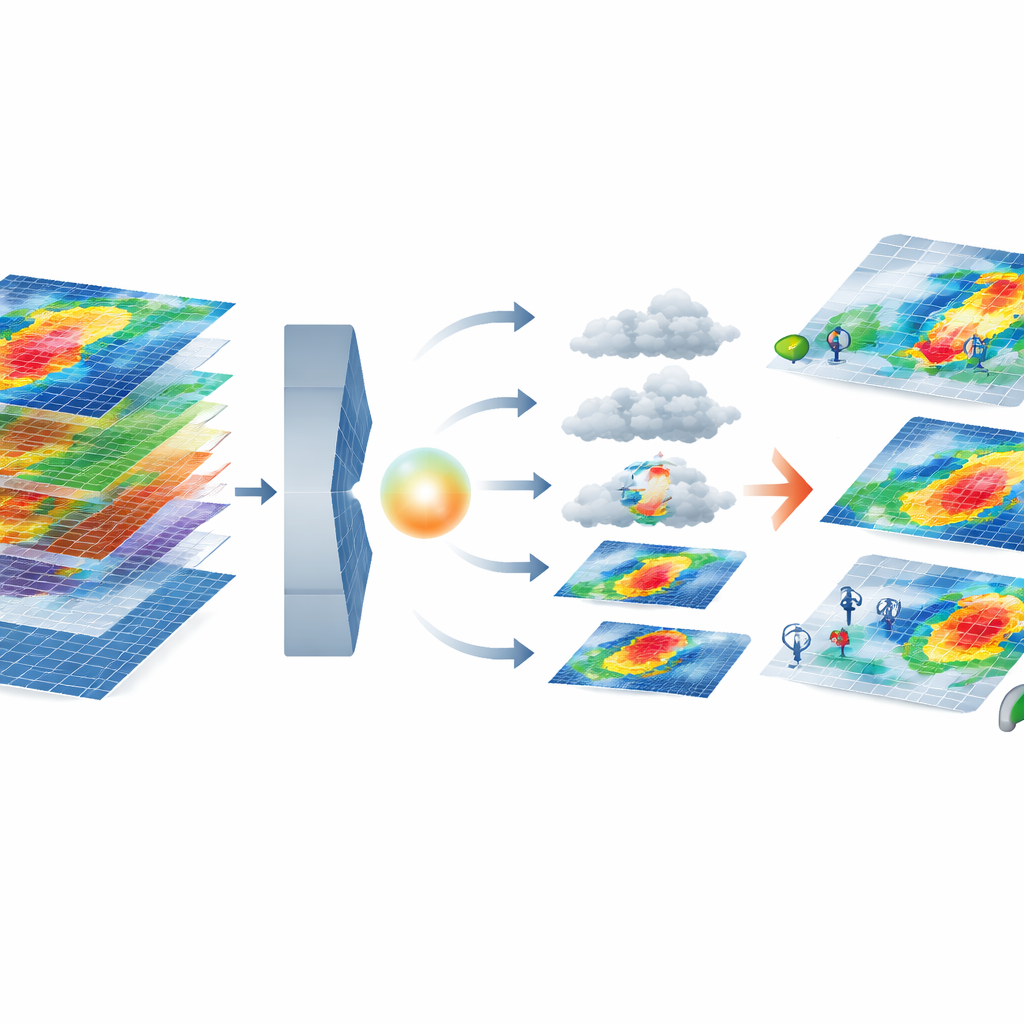
Synthetische Stürme auf dem Prüfstand
Die Autoren stellen dann die entscheidende Frage: Helfen diese synthetischen Stürme tatsächlich bei der Ausfallprognose? Sie trainieren ein bestehendes Ausfallvorhersagemodell zweimal — zuerst nur mit realen Stürmen und dann mit denselben Daten, angereichert durch sorgfältig gefilterte synthetische Ereignisse für die seltenen, hochwirksamen Cluster. Die Leistung bewerten sie mit einem strengen Leave‑One‑Storm‑Out‑Test, der das Forecasting neuer, ungesehener Ereignisse nachahmt. Mit synthetischer Anreicherung sinkt der strukturelle Fehler deutlich und die Gesamtanpassung verbessert sich. Für die seltenen, am stärksten störenden Stürme fällt der zentrale Root Mean Squared Error um etwa 45 %, und zusammenfassende Kompetenzmaße wie die Nash–Sutcliffe‑Effizienz steigen von schlechter‑als‑Basis‑Werten auf klar nützliche Leistungsniveaus. Ein Vergleich mit einer „zufälligen“ Erweiterung, die synthetische Stürme ohne Qualitätsprüfung hinzufügt, zeigt deutlich geringere oder sogar negative Gewinne und unterstreicht damit die Bedeutung rigoroser Filterung.
Was das für künftige Stürme bedeutet
Kurz gesagt zeigt diese Studie, dass es die Vorhersage von Ausfällen verlässlicher macht, wenn KI physikalisch konsistente Extremstürme erzeugen darf — und man zugleich wählerisch bleibt, welchen der erfundenen Stürme man vertraut. Durch die Anreicherung spärlicher Daten zu seltenen, aber verheerenden Wetterereignissen hilft der Ansatz Versorgern, besser abzuschätzen, wie viele Schadensstellen sie erwarten müssen und wo diese liegen. Obwohl die Methode für einen Bundesstaat und eine Gefahrenart demonstriert wurde, lässt sie sich auf Waldbrände, Überschwemmungen und andere Naturgefahren übertragen und bietet einen neuen Weg, die Infrastrukturplanung in einer Welt zunehmender Klimaextreme zu stärken.
Zitation: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Schlüsselwörter: synthetische Sturm‑Daten, Stromausfall‑Vorhersage, Diffusionsmodelle, extremes Wetter, Datenungleichgewicht