Clear Sky Science · de
Früherkennung chronischer Nierenerkrankungen basierend auf einem SURD-verbesserten Machine-Learning-Modell
Warum es wichtig ist, Nierenprobleme früh zu erkennen
Chronische Nierenerkrankungen entwickeln sich oft schleichend und bleiben bis zu weit fortgeschrittenen Schäden weitgehend symptomfrei. Einfache Blut- und Urintests können jedoch Jahre zuvor Auffälligkeiten zeigen, wenn Behandlungen das Fortschreiten verlangsamen oder schwerwiegenden Funktionsverlust verhindern können. Diese Studie untersucht einen neuen Weg, routinemäßige Testergebnisse mithilfe fortschrittlicher, aber interpretierbarer Computermodelle zu durchsuchen, damit Personen mit hohem Risiko früher erkannt werden und Ärztinnen und Ärzte die Gründe nachvollziehen können.
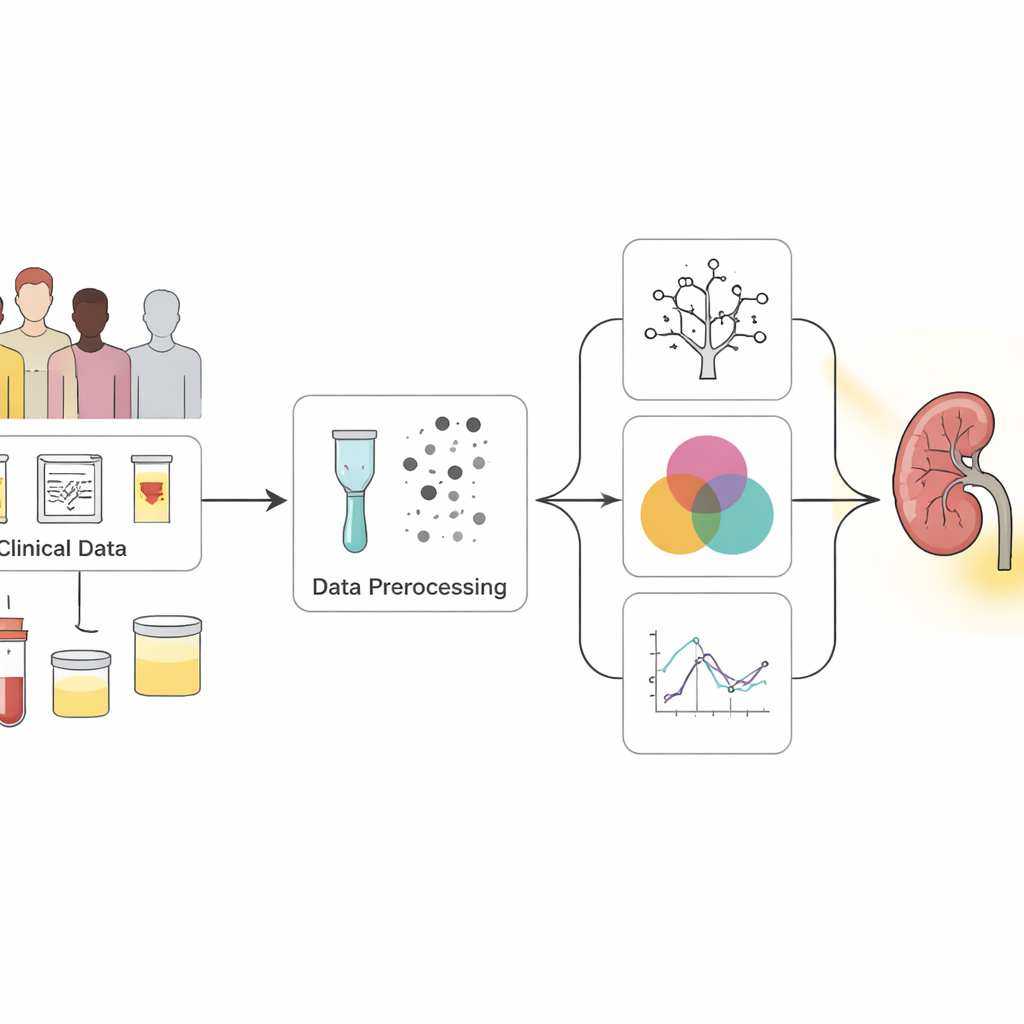
Aus unübersichtlichen Check-up-Daten klare Signale machen
Die Forscher begannen mit einem verbreiteten öffentlichen Datensatz von 400 Personen, von denen die meisten bereits mit chronischer Nierenerkrankung diagnostiziert waren. Jede Person hatte 25 Messwerte, von Blutdruck und Blutbild bis zu Urinbefunden und Vorgeschichte wie Diabetes und Bluthochdruck. Viele Einträge waren unvollständig, daher nutzte das Team sorgfältige statistische Verfahren, um fehlende Werte zu ergänzen, anstatt Patientendaten einfach zu verwerfen. Außerdem wurden die Daten ausgeglichen, sodass gesunde und erkrankte Fälle gleichmäßiger vertreten waren, was den Modellen half, beide Gruppen fair zu lernen.
Über einfache Korrelationen hinausblicken
Die meisten medizinischen Vorhersagewerkzeuge behandeln jede Messgröße separat: Sie prüfen, wie stark ein einzelner Wert, etwa der Blutzucker, mit der Erkrankung verknüpft ist. Im Körper wirken Risikofaktoren jedoch selten isoliert. Manche Tests liefern nahezu dieselben Informationen, andere werden erst in Kombination aussagekräftig. Um das abzubilden, verwendeten die Autorinnen und Autoren einen Rahmen namens SURD, der den Beitrag jeder Merkmalvariable in drei Teile zerlegt: gemeinsam mit anderen Tests geteilte Information, eindeutige Information und Information, die nur bei Zusammenwirken mehrerer Merkmale erscheint. So konnten sie Laborwerte und klinische Befunde in „einzigartige“, „redundante“ und „synergetische“ Gruppen einteilen, bevor sie sie den Vorhersagemodellen zuführten.
Viele Modelle trainieren und die zuverlässigsten auswählen
Mit diesen SURD-basierten Merkmalsgruppen trainierte das Team zehn verschiedene Machine-Learning-Modelle, von einfachen Entscheidungsbäumen bis zu komplexeren Ansätzen wie Random Forests und neuronalen Netzen. Sie verglichen die Leistung, wenn Modelle alle verfügbaren Merkmale nutzten, gegenüber nur einer kombinierten Menge aus einzigartigen und synergetischen Merkmalen. Bei fast allen Modelltypen erreichte dieser gestraffte, SURD-geführte Merkmalsatz gleichwertige oder bessere Ergebnisse als die gesamte Sammlung von 25 Variablen und verbesserte oft das Gleichgewicht zwischen korrekter Erkennung erkrankter Patienten und der Vermeidung von Fehlalarmen. Insbesondere baumbasierte Modelle wie Random Forests und Boosted Trees erzielten auf dem ursprünglichen Datensatz nahezu perfekte Werte.
Die Methode an realen Klinikdaten testen
Exzellente Ergebnisse bei einem kleinen Benchmark-Datensatz können irreführend sein, wenn ein Modell bei vielfältigeren Patienten versagt. Um dem vorzubeugen, validierten die Autorinnen und Autoren ihren Ansatz mit einer deutlich größeren Krankenhausdatenbank von über 27.000 Intensivpatienten. Hier unterschied das auf SURD-selektierten Merkmalen aufgebaute Random-Forest-Modell weiterhin Patienten mit und ohne Nierenerkrankung mit äußerst hoher Genauigkeit. Seine Leistung übertraf deutlich die eines einfachen Entscheidungsbaums, was darauf hindeutet, dass die Methode über einen sorgfältig kuratierten Forschungsdatensatz hinaus auf unordentlicheren Real‑World-Daten generalisierbar ist.
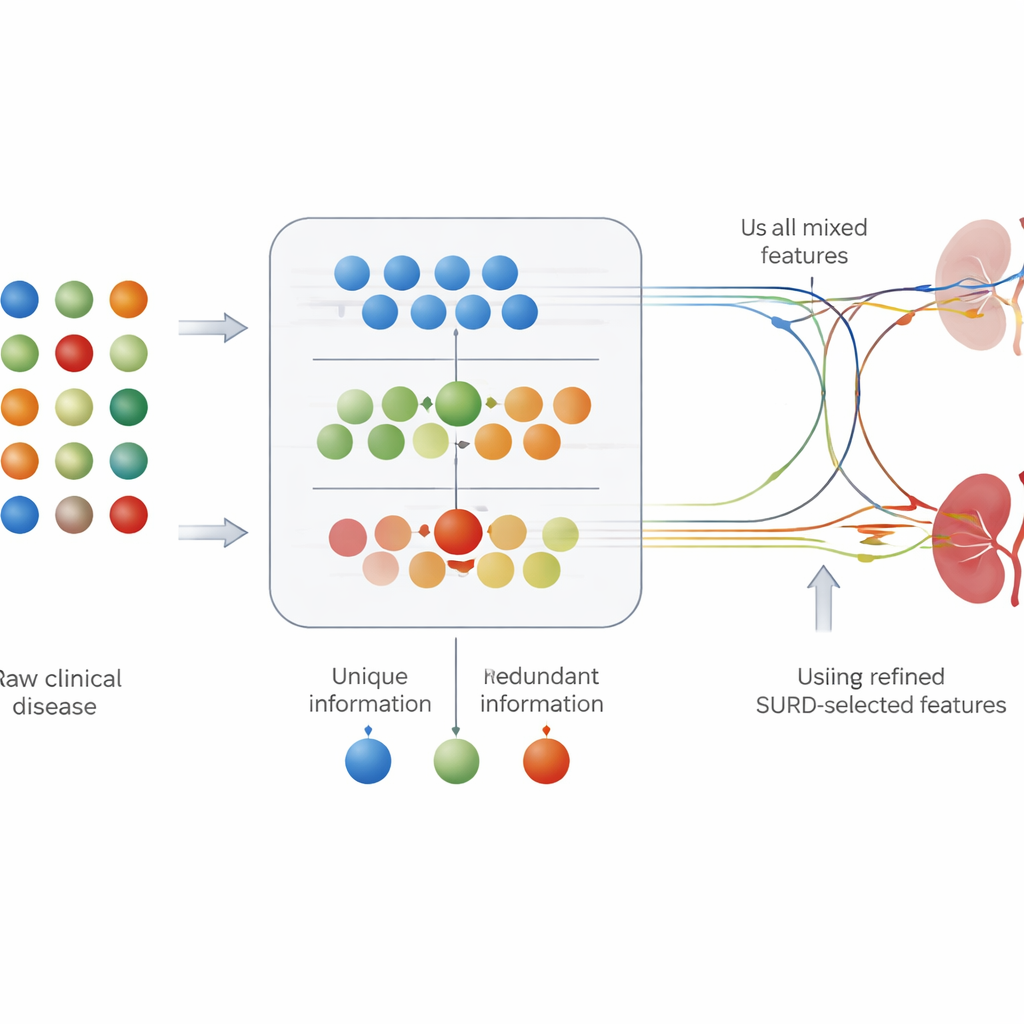
Welche Tests wichtig sind und wie sie wirken
Allein Genauigkeit genügt klinisch nicht; Ärztinnen und Ärzte müssen auch wissen, welche Testergebnisse eine Vorhersage treiben. Die Studie kombinierte SURD mit modernen Erklärungswerkzeugen, die jedem Merkmal einen Beitrag zur Modellentscheidung für einen einzelnen Patienten zuweisen. Diese Analyse hob bekannte Risikomarker hervor, wie Serumkreatinin (ein direkter Indikator der Nierenfunktion), Hämoglobinspiegel, Urinkonzentration sowie das Vorliegen von Diabetes oder Bluthochdruck. Interessanterweise zeigte SURD, dass einige dieser Faktoren überwiegend im Zusammenspiel mit anderen wirken, während Kreatinin als starker, eigenständiger Informationsgeber hervorsticht. Zusammen liefern diese Techniken sowohl einen globalen Überblick darüber, auf welche Tests das Modell vertraut, als auch patientenspezifische Aufschlüsselungen, warum gerade diese Person als hochriskant eingestuft wird.
Was das für die tägliche Versorgung bedeutet
Einfach gesagt zeigt die Studie, dass es möglich ist, einen Risiko-Rechner für Nierenerkrankungen zu entwickeln, der sowohl sehr genau als auch hinreichend transparent ist. Indem überlappende von wirklich einzigartigen Informationen in routinemäßigen Labor- und Anamnesedaten getrennt werden, ermöglichen die SURD-geführten Modelle schärfere Vorhersagen, ohne zu einer mysteriösen Blackbox zu werden. Obwohl weitere Arbeiten in breiteren und vielfältigeren Patientengruppen nötig sind, könnte dieser Ansatz schließlich Ärztinnen und Ärzte dabei unterstützen, Nierenprobleme früher zu erkennen, sich auf die aussagekräftigsten Tests zu konzentrieren und Patientinnen und Patienten in klaren Worten zu erklären, welche Aspekte ihrer Gesundheit ihre Nieren gefährden.
Zitation: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Schlüsselwörter: chronische nierenerkrankung, vorhersage des niererisikos, medizinisches maschinelles lernen, erklärbare KI, elektronische gesundheitsakten