Clear Sky Science · de
Dynamischer Machine-Learning-Ansatz zur Arbeitslastvorhersage in Cloud-Umgebungen
Warum intelligente Verkehrsvorhersage wichtig ist
Jedes Mal, wenn Sie ein Video streamen, einem großen Sportereignis online folgen oder während eines Blitzverkaufs einkaufen, klicken Tausende andere möglicherweise im selben Moment. Im Hintergrund bemühen sich Cloud-Rechenzentren, Websites schnell zu halten, ohne Geld für untätige Maschinen zu verschwenden. Dieser Artikel befasst sich mit einer einfachen Frage von großer praktischer Bedeutung: Wie können Cloud-Systeme plötzliche Wellen an Webtraffic so gut vorhersagen, dass Server genau rechtzeitig ein- und ausgeschaltet werden können, anstatt zu raten und zu viel zu bezahlen?
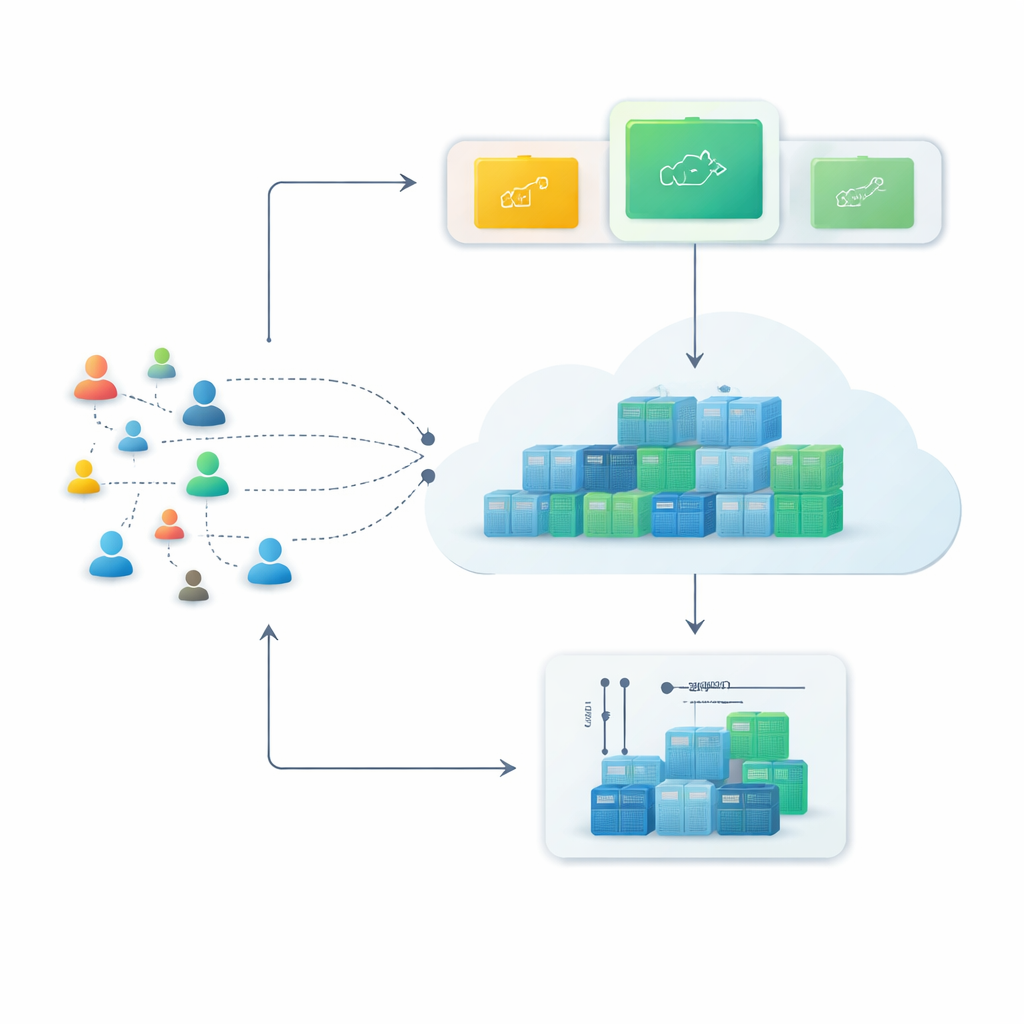
Von starren Servern zu flexiblen Containern
Moderne Cloud-Plattformen setzen zunehmend auf Container, kleine Softwarepakete, die in Sekunden gestartet oder gestoppt werden können. Im Vergleich zu traditionellen virtuellen Maschinen sind Container leichter und dichter packbar, was sie ideal für Dienste macht, die sich während hoher Last schnell vergrößern und danach wieder verkleinern müssen. Doch diese Flexibilität zahlt sich nur aus, wenn das System kommende Probleme erkennen kann — wenn es vorhersagen kann, wie viele Webanfragen in den nächsten Minuten eintreffen und rechtzeitig die richtige Anzahl an Containern bereitstellt.
Warum Einheitslösungen bei Vorhersagen versagen
Frühere Forschung hat viele verschiedene Methoden zur Vorhersage von Webtraffic ausprobiert, von klassischen Statistikverfahren bis zu tiefen neuronalen Netzen. Einige funktionieren gut, wenn die Nachfrage im Tagesverlauf gleichmäßig schwankt; andere sind besser, wenn der Traffic unvorhersehbar springt, etwa bei einem Spiel in der Weltmeisterschaft. Das Problem ist, dass keine einzelne Methode jederzeit die beste ist. Wenn Betreiber ein bevorzugtes Modell wählen und dabei bleiben, kann die Genauigkeit stark einbrechen, sobald sich das Nutzerverhalten ändert — mit der Folge trüber Webseiten oder einer Reihe unterausgelasteter Maschinen, die still Geld und Energie verschwenden.
Eine Lernschleife, die sich ständig anpasst
Um dem entgegenzuwirken, schlagen die Autoren einen Closed-Loop-Ansatz vor, den sie Monitor–Train–Test–Deploy nennen. Die Idee ist, die Vorhersage selbst als lebenden Prozess zu behandeln. Erstens zeichnet das System kontinuierlich eintreffende Webanfragen mit Zeitstempel auf. Als Nächstes trainiert es mehrere verschiedene Prognoseverfahren parallel, die jeweils versuchen, Muster in dieser jüngsten Historie zu lernen. Dann testet es diese Kandidatenmodelle an den aktuellsten Daten und bewertet sie danach, wie stark ihre Schätzungen von der Realität abweichen. Nur das am besten abschneidende Modell übernimmt die Live-Vorhersagen, die steuern, wie viele Container laufen. Mit dem Eintreffen frischer Anfragen wiederholt sich die Schleife: Wenn Vorhersagefehler zwei Zyklen hintereinander über ein toleriertes Maß steigen, trainiert das System automatisch neu und kann die Kontrolle an ein anderes Modell übergeben.
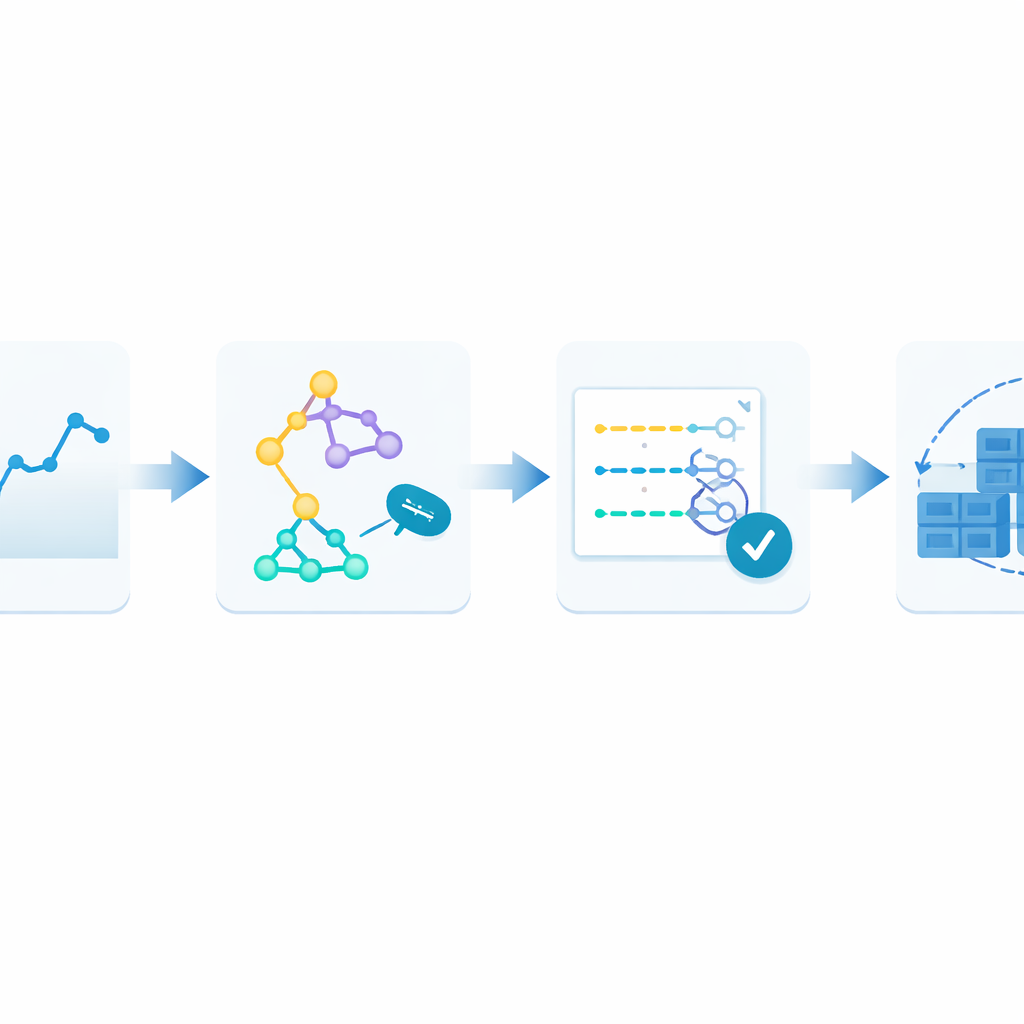
Das Framework im Praxistest
Die Forschenden bewerteten diesen Ansatz anhand synthetischer und realer Webtraffic-Traces. Sie erzeugten mehrere idealisierte Muster — glatte glockenförmige Kurven, gleichmäßig ansteigende Lasten mit unterschiedlichen Geschwindigkeiten und sehr unregelmäßigen Traffic — und nutzten außerdem Aufzeichnungen von den offiziellen WM-Webseiten aus 1998 und 2018, wo das Interesse abrupt anstieg. Für jeden Fall verglichen sie drei bis vier bekannte Vorhersagewerkzeuge, darunter ein statistikbasiertes Verfahren, ein Support-Vector-Modell, ein Entscheidungsbaum-Ensemble und in späteren Experimenten eine verbreitete Form rekurrenter neuronaler Netze. Das zentrale Ergebnis war, dass der „Gewinner“ situationsabhängig wechselte: Einfache statistische Modelle glänzten bei stabiler Nachfrage, während lernbasierte Methoden klar überlegen waren, wenn der Traffic wild und burstartig wurde.
Gewinne bei Genauigkeit und Effizienz
Indem das System kontinuierlich zum jeweils am besten geeigneten Modell wechselte, verringerte das Framework die Vorhersagefehler im Vergleich zum Festhalten an einem einzigen Modell um bis zu etwa 15 Prozent. Ebenso wichtig ist, dass dies geschah, ohne alle Modelle ständig laufen zu lassen. Während des Live-Betriebs ist nur ein Prädiktor aktiv; die anderen werden periodisch neu trainiert und geprüft, wodurch die Rechenlast moderat bleibt. Die Autoren führen außerdem eine schrittweise verschärfte Schwelle für Neutrainings ein, sodass das System weniger tolerant gegenüber wiederholten Fehlern wird und das Risiko langer Phasen schlechter Vorhersagen reduziert.
Was das für alltägliche Cloud-Nutzer bedeutet
Praktisch zeigt die Studie, dass Cloud-Plattformen intelligenter betrieben werden können, indem Vorhersagemodelle gegeneinander antreten und die Auswahl im Laufe der Zeit angepasst wird. Für Nutzer kann das während großer Ereignisse zu reibungsloseren Online-Erlebnissen und bei unverhofftem Andrang zu weniger Verzögerungen führen. Für Anbieter verspricht es einen schlankeren Einsatz von Rechenressourcen, geringere Betriebskosten und weniger verschwendete Energie. Anstatt auf einen einzigen cleveren Algorithmus zu setzen, plädiert diese Arbeit für eine flexible Kontrollschleife, die fortwährend lernt, testet und ihre Nachfrageabschätzung in einer zunehmend unvorhersehbaren digitalen Welt überarbeitet.
Zitation: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Schlüsselwörter: Vorhersage von Cloud-Arbeitslasten, Autoscaling, Container, Machine Learning, Zeitreihen