Clear Sky Science · de
Ein datenschutzschonendes Mehrbenutzer-Suchsystem für multimodale künstliche Intelligenz
Warum es wichtig ist, intelligente Suchen privat zu halten
Viele von uns verlassen sich inzwischen auf cloudbasierte künstliche Intelligenz, um Fotos, Dokumente und sogar medizinische Scans zu durchsuchen. Diese Systeme sind leistungsfähig, weil sie sowohl Bilder als auch Worte verstehen können, doch sie stellen auch eine schwierige Frage: Wie können wir diesen Komfort nutzen, ohne die Bedeutung unserer sensibelsten Daten entfernten Servern preiszugeben? Dieses Papier stellt PMIRS vor, ein neues System, das vielen Nutzern erlaubt, in gemischten Bild‑und‑Text‑Sammlungen zu suchen, während ihre Informationen vor den Cloud‑Rechnern, die diese Suchen ausführen, verborgen bleiben.
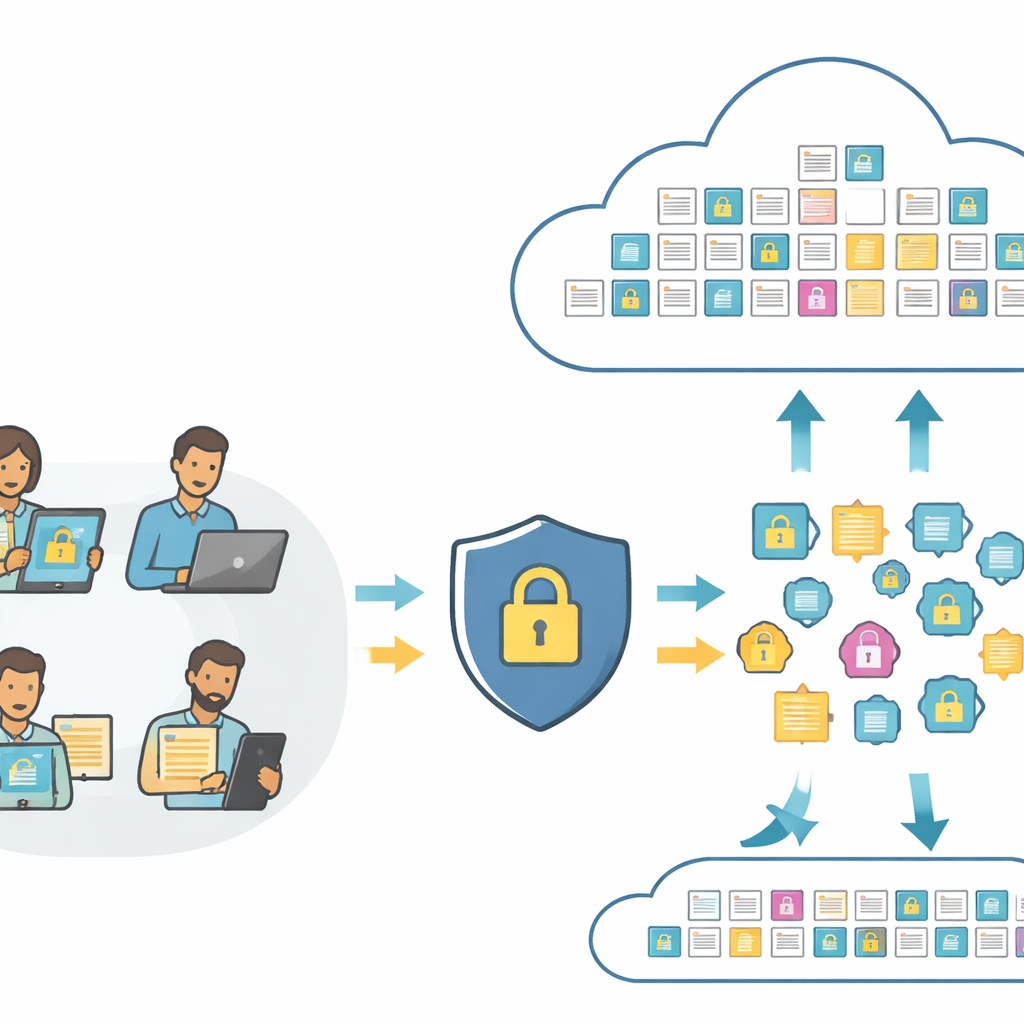
Bilder und Text durchsuchen, ohne ihre Bedeutung preiszugeben
Im Kern moderner Suchwerkzeuge stehen „Embeddings“ — numerische Fingerabdrücke, die den Inhalt eines Fotos oder eines Satzes erfassen, sodass ein Computer sie vergleichen kann. In Standard‑Systemen werden diese Fingerabdrücke direkt in die Cloud gesendet, wo sie analysiert oder sogar missbraucht werden können. PMIRS stellt diese Pipeline um. Nutzer senden zunächst ihre Rohbilder und Texte an eine lokale Schicht, die sie mit einem kompakten Vision‑und‑Language‑Modell in Fingerabdrücke umwandelt. Bevor etwas die Nutzerseite verlässt, werden die Fingerabdrücke kontrolliert verwürfelt und anschließend verschlüsselt. Die Cloud sieht nur diese geschützten Fingerabdrücke und vollständig verschlüsselte Kopien der gespeicherten Daten, kann aber weiterhin Abgleiche durchführen und die besten Treffer zurückliefern.
Von vielen Nutzern lernen, ohne ihre Daten zu bündeln
Zum Trainieren eines guten Bild‑Text‑Modells werden normalerweise große Mengen gelabelter Beispiele an einem Ort gesammelt — ein eindeutiges Datenschutzrisiko. PMIRS setzt stattdessen auf föderiertes Lernen. Bei diesem Setup wird das zugrundeliegende Modell, adaptiert aus der bekannten CLIP‑Architektur, an viele Geräte verteilt. Jedes Gerät trainiert lokal an seinen eigenen privaten Bild‑Text‑Paaren und sendet nur aktualisierte Modellgewichte zurück, die ebenfalls verschlüsselt sind. Ein zentraler Server mittelt diese Updates, um ein gemeinsames Modell zu verbessern, ohne jemals die Rohfotos oder Beschreibungen eines Nutzers zu sehen. Die Autoren verkleinern und feinabstimmen das Modell außerdem durch einen mehrstufigen „Distillation“-Prozess, der unnötige Teile entfernt und dabei die Genauigkeit bewahrt, sodass das System leichtgewichtig genug für den praktischen Einsatz wird.
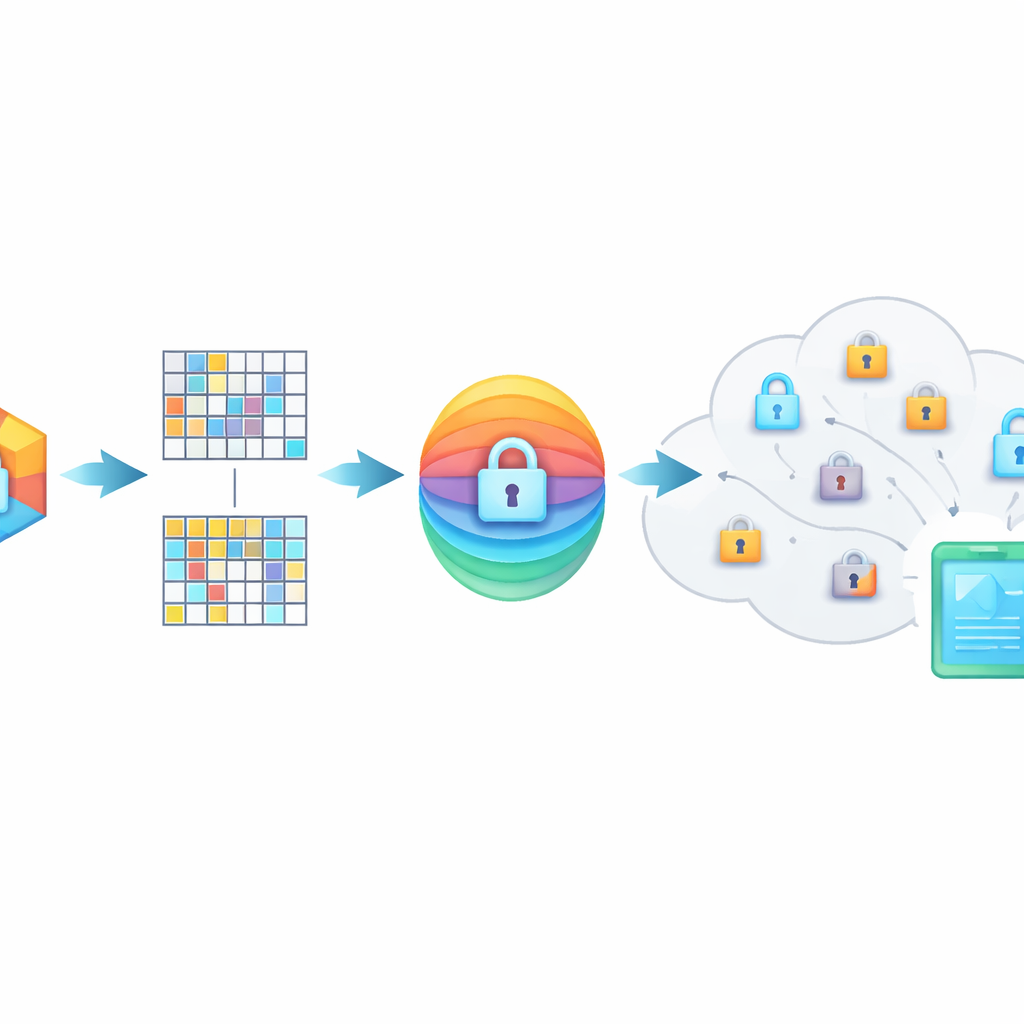
Die Bedeutung in verwürfelten Fingerabdrücken verbergen
PMIRS schützt Anfragen mit einem zweischichtigen Schild. Zuerst wird jeder Fingerabdruck in Blöcke aufgeteilt, und jeder Block wird durch eine geheime Matrix plus ein sorgfältig designtes Rauschmuster transformiert. Dieses Verwürfeln verbirgt die ursprüngliche Struktur der Daten, ist aber so eingerichtet, dass bei zwei verwandten Objekten, die beide transformiert wurden, ihre Ähnlichkeit erhalten bleibt. Zweitens wird das Ergebnis mit dem weit verbreiteten AES‑Verfahren verschlüsselt, wobei Schlüssel nie offen über das Netzwerk geschickt werden. Für Situationen, in denen eine Person in den Daten einer anderen suchen muss — etwa wenn ein Arzt eine Spezialistin konsultiert — verwendet das System ein Diffie‑Hellman‑Schlüsselaustauschprotokoll, damit sie gemeinsame Geheimnisse vereinbaren können, ohne diese gegenüber Lauscherinnen und Lauschern offenzulegen.
Wie gut das System in der Praxis funktioniert
Um zu prüfen, ob diese Schutzmaßnahmen zu hohen Kosten führen, bauten die Forschenden ein Benchmark auf, das Alltagsbilder mit kurzen natürlichsprachlichen Phrasen koppelt — näher daran, wie Menschen Dinge tatsächlich beschreiben, als einzelne Schlagworte. Sie verglichen PMIRS mit einer standardmäßigen CLIP‑basierten Suche über drei Themenbereiche: Naturszenen, hergestellte Objekte und Aktivitäten oder Landschaften. Über viele Repositoriumsgrößen hinweg fand PMIRS beständig ein besseres Gleichgewicht zwischen dem Auffinden aller richtigen Ergebnisse (Recall) und dem Vermeiden falscher Treffer (Precision), was zu einem durchschnittlich etwa 7,7 % höheren F1‑Score — einer kombinierten Genauigkeitsmetrik — gegenüber der Baseline führte. Wichtig ist, dass die Antwortzeiten unter etwa 180 Millisekunden blieben, schnell genug für interaktive Nutzung, und oft trotz der zusätzlichen Schutzschritte leicht schneller als die unsichere Baseline waren.
Was das für Alltagsnutzer bedeutet
Kurz gesagt zeigt PMIRS, dass es möglich ist, Cloud‑Suchwerkzeuge zu bauen, die Bilder und Text gut verstehen, viele Nutzer gleichzeitig bedienen und dabei die Bedeutung der Daten jedes Einzelnen dem Cloud‑Anbieter vorenthalten. Durch die Kombination aus lokalem Training, cleverer Verwürfelung der Fingerabdrücke, starker Verschlüsselung und sicherem Schlüsselaustausch bietet das System eine Ende‑zu‑Ende datenschutzschonende Pipeline statt nur einzelner Schutzmaßnahmen. Obwohl es noch nicht gegen alle denkbaren Angriffe schützt und weitere Verfeinerung sowie Feldtests benötigt, weist die Arbeit auf künftige Dienste hin — etwa Nachschlagen medizinischer Bilder, Kunden‑Support‑Bots oder Unternehmensarchive — in denen Menschen reichhaltige, multimodale KI‑Suche nutzen können, ohne befürchten zu müssen, dass ihre persönlichen Inhalte offengelegt oder missbraucht werden.
Zitation: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Schlüsselwörter: datenschutzschonende KI, multimodale Suche, föderiertes Lernen, verschlüsselte Suche, sichere Cloud-Computing