Clear Sky Science · de
Clustering-cum-regression basiertes Modell und Leistungsanalyse zur Frühvorhersage von Herzerkrankungen
Warum frühes Erkennen von Herzproblemen wichtig ist
Herzerkrankungen entwickeln sich oft über viele Jahre hinweg unbemerkt, und wenn eindeutige Symptome auftreten, ist der Schaden möglicherweise bereits eingetreten. Diese Studie untersucht, wie alltägliche am Körper getragene Sensoren und intelligente Datenanalyse zusammenwirken können, um Warnzeichen früher zu erkennen und Ärzten sowie Patientinnen und Patienten mehr Zeit zum Handeln zu geben. Indem die Forschenden zwei unterschiedliche Blickwinkel auf Gesundheitsdaten kombinieren, wollen sie Vorhersagen genauer machen, ohne die Technologie für den Einsatz in realen Kliniken unnötig zu verkomplizieren.
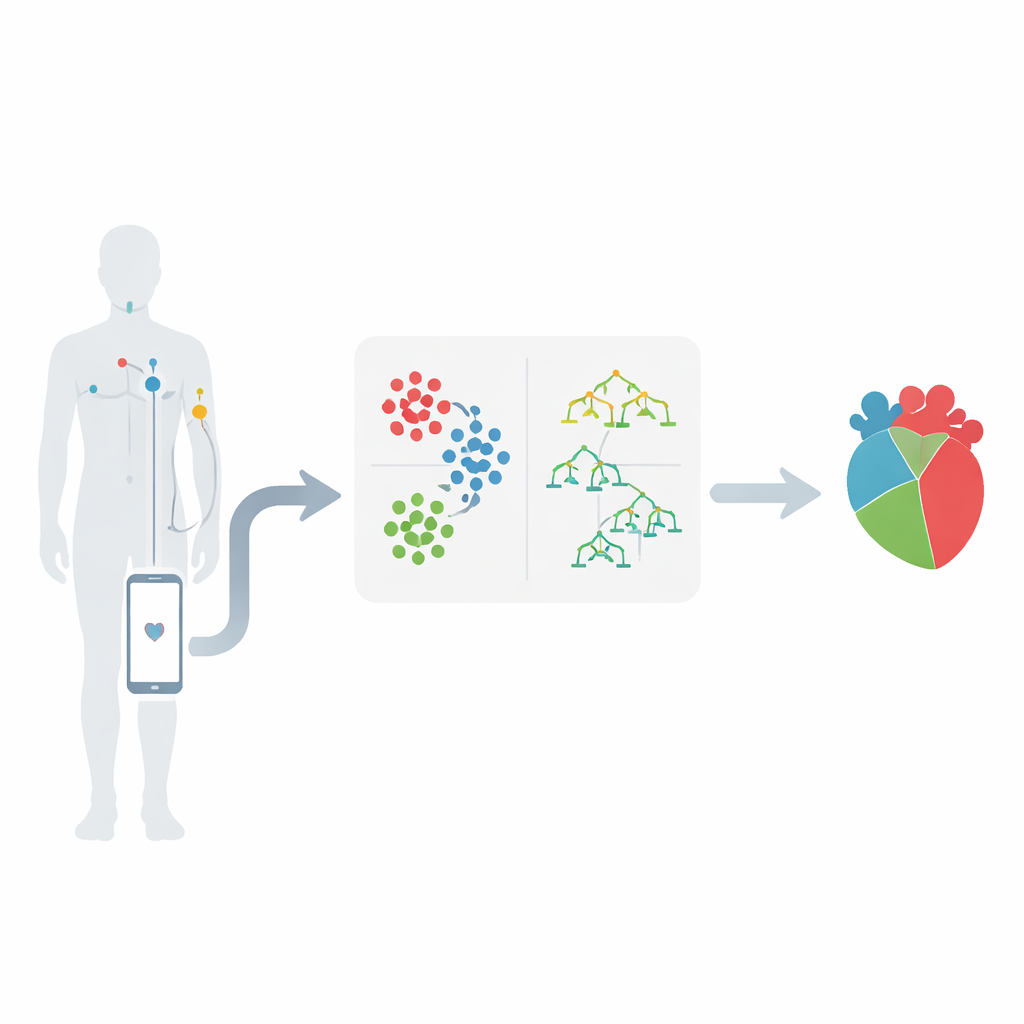
Von Körpersensoren zu intelligenten Warnungen
Die Arbeit spielt im Umfeld drahtloser Body Area Networks, in dem kleine auf der Haut platzierte Sensoren Signale wie Herzfrequenz, Blutdruck und die elektrische Aktivität des Herzens erfassen. Diese Sensoren senden Messwerte an ein Mobilgerät, das sie zur Analyse an ein medizinisches Zentrum weiterleitet. Der zentrale Gedanke ist, dass diese Zahlenströme Muster enthalten können, die lange vor einem akuten Ereignis auf sich entwickelnde Herzprobleme hinweisen. Die Autorinnen und Autoren konzentrieren sich auf einen bekannten Herzkrankheitsdatensatz und wählen 12 wichtige Merkmale aus, darunter Art der Brustschmerzen, Blutdruck, Cholesterin, Blutzucker, belastungsbedingte Brustbeschwerden und Veränderungen im Elektrokardiogramm.
Verborgene Gruppen in Patientendaten finden
Statt alle Patientendaten direkt in eine einzige Vorhersageformel einzuspeisen, gruppiert das Team zuerst ähnliche Patientinnen und Patienten. Sie nutzen eine Methode namens K-means-Clustering, die Personen anhand der Ähnlichkeit ihrer Messwerte in Cluster sortiert, wobei das Alter eine zentrale Rolle spielt. So können sich Patienten beispielsweise natürlich in Gruppen mit sehr hohem Blutdruck, hohem Cholesterin oder bestimmten Mustern in Herztests einordnen. Dieser Gruppierungsschritt hilft, Kombinationen von Messwerten hervorzuheben, die besonders besorgniserregend sind. Er zeigt auch, dass bestimmte Bereiche – etwa Blutdruck über 150, Cholesterin über 300 oder bestimmte Veränderungen in Herzaufzeichnungen – mit einem deutlich erhöhten Risiko verbunden sind.
Maschinen beibringen, Risiko zu bewerten
Nachdem die Daten gruppiert wurden, wenden die Forschenden mehrere Methoden des maschinellen Lernens an, die aus vergangenen Fällen lernen, um vorherzusagen, ob bei einer neuen Patientin beziehungsweise einem neuen Patienten eine relevante Herzerkrankung wahrscheinlich ist. Sie vergleichen verschiedene Ansätze, darunter Entscheidungsbäume, k-nearest neighbors, Support Vector Machines, logistische Regression, Naive Bayes und Random Forests. In ihrem hybriden Aufbau wird jede neue Person zunächst dem nächstgelegenen Cluster zugewiesen; anschließend trifft ein speziell für diesen Patiententyp trainiertes Random-Forest-Modell die endgültige Risikovorhersage. Die Daten werden sorgfältig bereinigt, skaliert und in Trainings- und Testmengen aufgeteilt, und dem Klassenungleichgewicht (mehr gesunde als kranke Patienten) wird begegnet, damit die Modelle nicht zugunsten der Mehrheitsklasse verzerrt werden.
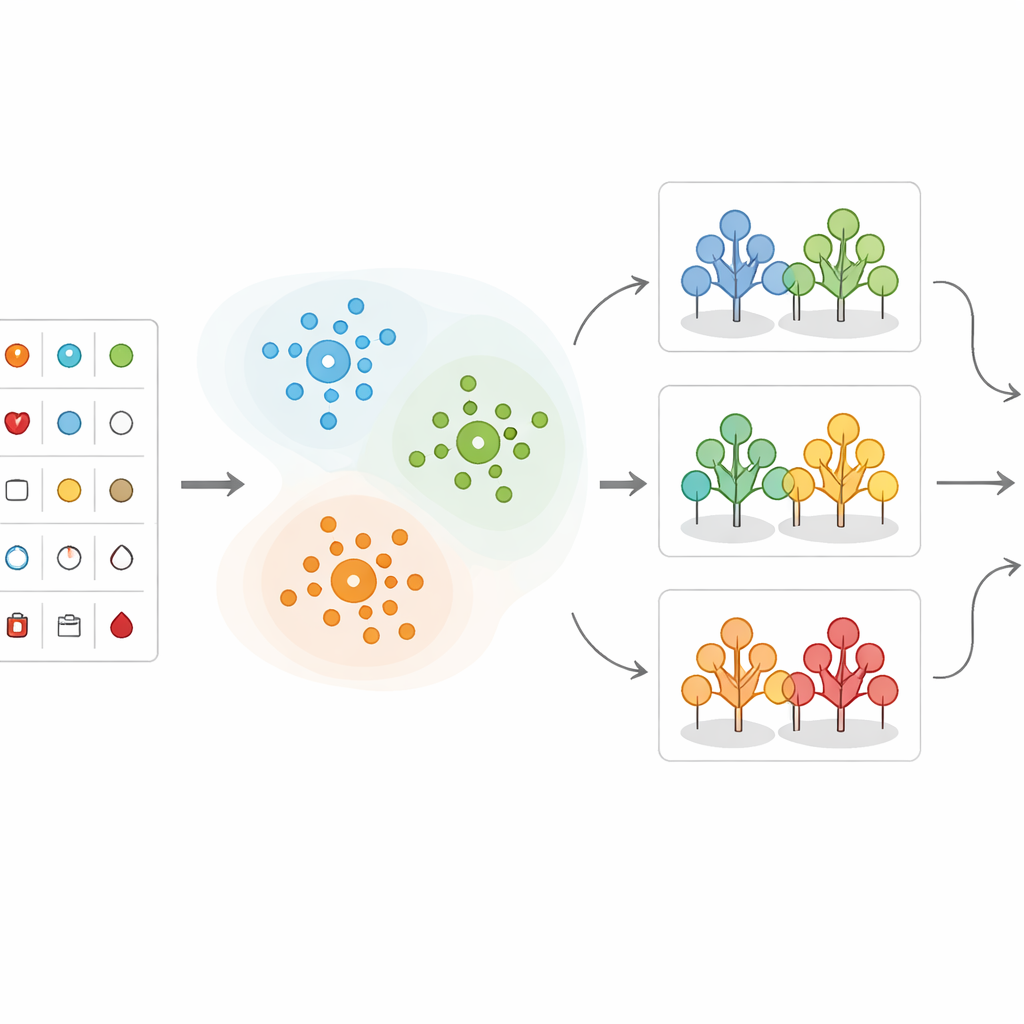
Wie gut das hybride Modell abschneidet
Zur Beurteilung des Erfolgs betrachtet die Studie nicht nur die Gesamtgenauigkeit, sondern auch, wie häufig das Modell Kranke korrekt erkennt (Recall), Gesunde richtig beruhigt (Spezifität) und beide Ziele ausbalanciert (F1-Score und ROC–AUC). Frühere Studien mit ähnlichen Daten erreichten oft rund 85 Prozent Genauigkeit und hatten Schwierigkeiten, diese feineren Kennzahlen zu verbessern. Hier erzielt der kombinierte Clustering‑plus‑Random‑Forest‑Ansatz rund 91 Prozent Genauigkeit, mit starkem Recall und sehr hoher Spezifität. Die Konfidenzintervalle dieses Modells überlappen nicht mit denen der einfacheren Methoden, was darauf hindeutet, dass die Verbesserung wahrscheinlich nicht zufällig ist. Gleichzeitig bleibt die Rechenzeit in einem praktischen Bereich – im Bereich von Millisekunden bis Sekunden – und ist damit für Echtzeit- oder beinahe-echtzeitfähige Überwachungssysteme geeignet.
Was das für Patientinnen, Patienten und Ärztinnen und Ärzte bedeutet
Alltagsnah zeigt die Studie, dass es die Früherkennung von Herzerkrankungen verbessern kann, wenn Computer Patientinnen und Patienten zunächst in sinnvolle Gruppen einordnen und anschließend maßgeschneiderte Vorhersageregeln anwenden. Die Methode ist besonders vielversprechend für kontinuierliche Überwachungsszenarien, in denen Wearables im Hintergrund Daten sammeln. Zwar stammen die Ergebnisse aus einem moderat großen, strukturierten Datensatz und nicht aus vollständigen klinischen Akten, und die Autorinnen und Autoren weisen auf mögliche Verzerrungen hin; die Botschaft ist jedoch klar: Eine intelligentere Nutzung vorhandener Messwerte kann Ärztinnen und Ärzten ein verlässlicheres Frühwarnsystem liefern. Mit weiterer Forschung und größeren, reichhaltigeren Datensätzen könnte diese Art hybrider Analyse dabei helfen, rohe Sensordaten in rechtzeitige, personalisierte Warnungen zu verwandeln, die Herzinfarkte und andere schwere Ereignisse verhindern, bevor sie eintreten.
Zitation: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Schlüsselwörter: Vorhersage von Herzerkrankungen, tragbare Gesundheitssensoren, maschinelles Lernen, Clustering medizinischer Daten, Random-Forest-Modell