Clear Sky Science · de
Exakte Merkmalskollisionen in neuronalen Netzen
Wenn verschiedene Bilder eine intelligente Maschine täuschen
Moderne Systeme der künstlichen Intelligenz können Gesichter erkennen, medizinische Aufnahmen lesen und selbstfahrende Autos steuern. Wir wissen bereits, dass sie durch winzige, gezielt platzierte Änderungen an einem Bild getäuscht werden können. Dieses Paper zeigt etwas noch Überraschenderes: dieselben Netze können gegenüber großen, offensichtlichen Veränderungen blind sein und sehr unterschiedliche Bilder so behandeln, als wären sie identisch. Zu verstehen, wie und warum das passiert, ist entscheidend, wenn wir KI‑Systeme wirklich vertrauen wollen.
Von winzigen Änderungen zu großen Blindstellen
Tiefe neuronale Netze treiben die heutigen Durchbrüche in Bildverarbeitung, Sprache und vielen anderen Bereichen voran. Frühere Forschungsarbeiten zu adversarialen Beispielen zeigten, dass eine kaum sichtbare Änderung an einem Bild ein Netzwerk dazu bringen kann, es mit hoher Sicherheit falsch zu klassifizieren. Neuere Arbeiten deckten das entgegengesetzte Problem auf: Einige Netze reagieren kaum auf große, offensichtliche Veränderungen und liefern trotzdem nahezu identische Vorhersagen. In solchen Fällen kollidieren die intern extrahierten Merkmale zweier sehr unterschiedlicher Bilder — das heißt, das Netzwerk repräsentiert sie nahezu auf die gleiche Weise. Diese Studie geht deutlich weiter und beweist, dass gängige Netze nicht nur ungefähre Kollisionen haben können, sondern exakte Merkmalskollisionen, bei denen zwei verschiedene Eingaben präzise dieselben internen Signale erzeugen.
Wie Kollisionen innerhalb eines Netzes entstehen
Zur Erklärung dieser Kollisionen blicken die Autoren unter die Haube neuronaler Netze und konzentrieren sich auf deren Gewichtsmatrizen, die trainierten Zahlen, die eine Schicht mit der nächsten verbinden. Eine Merkmalskollision tritt auf, wenn zwei verschiedene Eingaben auf einer Schicht dieselbe Ausgabe erzeugen; sobald das passiert, sehen alle nachfolgenden Schichten dasselbe und können die Eingaben nicht mehr unterscheiden. Mathematisch geschieht das, wenn die Differenz zwischen zwei Eingaben im "Nullraum" der Gewichte einer Schicht liegt: Richtungen im Eingaberaum, die die Schicht vollständig ignoriert. Die Autoren zeigen, dass immer dann, wenn eine Gewichtsmatrix einen Null‑Eigenwert hat oder von einem höherdimensionalen in einen niedererdimensionalen Raum abbildet, solche ignorierten Richtungen existieren müssen. Da die meisten realen Architekturen, einschließlich gängiger Modelle für Klassifikation, Segmentierung und Objekterkennung, viele solcher Schichten verwenden, sind Kollisionen keine seltenen Randfälle, sondern eine nahezu unvermeidliche Eigenschaft dieser Netze.
Ein neuer Weg, kollidierende Eingaben zu konstruieren
Aufbauend auf dieser Einsicht führt das Paper ein praktisches Verfahren ein, die sogenannte Nullraum‑Suche. Anstatt sich auf Trial‑and‑Error oder gradientenbasierte Tricks zu verlassen, nutzt diese Methode direkt den Nullraum der ersten Gewichtsmatrix. Ausgehend von einem beliebigen Bild berechnen die Autoren einen Vektor, den die erste Schicht ignoriert, und addieren dann eine skalierte Version dieses Vektors zum Bild. Da diese Richtung für die Schicht unsichtbar ist, bleiben die internen Merkmale des Netzes — und die endgültige Vorhersage — exakt gleich, selbst wenn das Bild für einen menschlichen Betrachter stark verzerrt erscheint. Dieselbe Idee lässt sich auf Faltungsschichten und grundsätzlich auch auf spätere Schichten anwenden. Die Autoren untersuchen viele Standardmodelle und finden, dass die meisten zahlreiche solcher ignorierter Richtungen haben, sodass sich auf diese Weise unzählige kollidierende Bilder für eine breite Palette von Aufgaben erzeugen lassen.
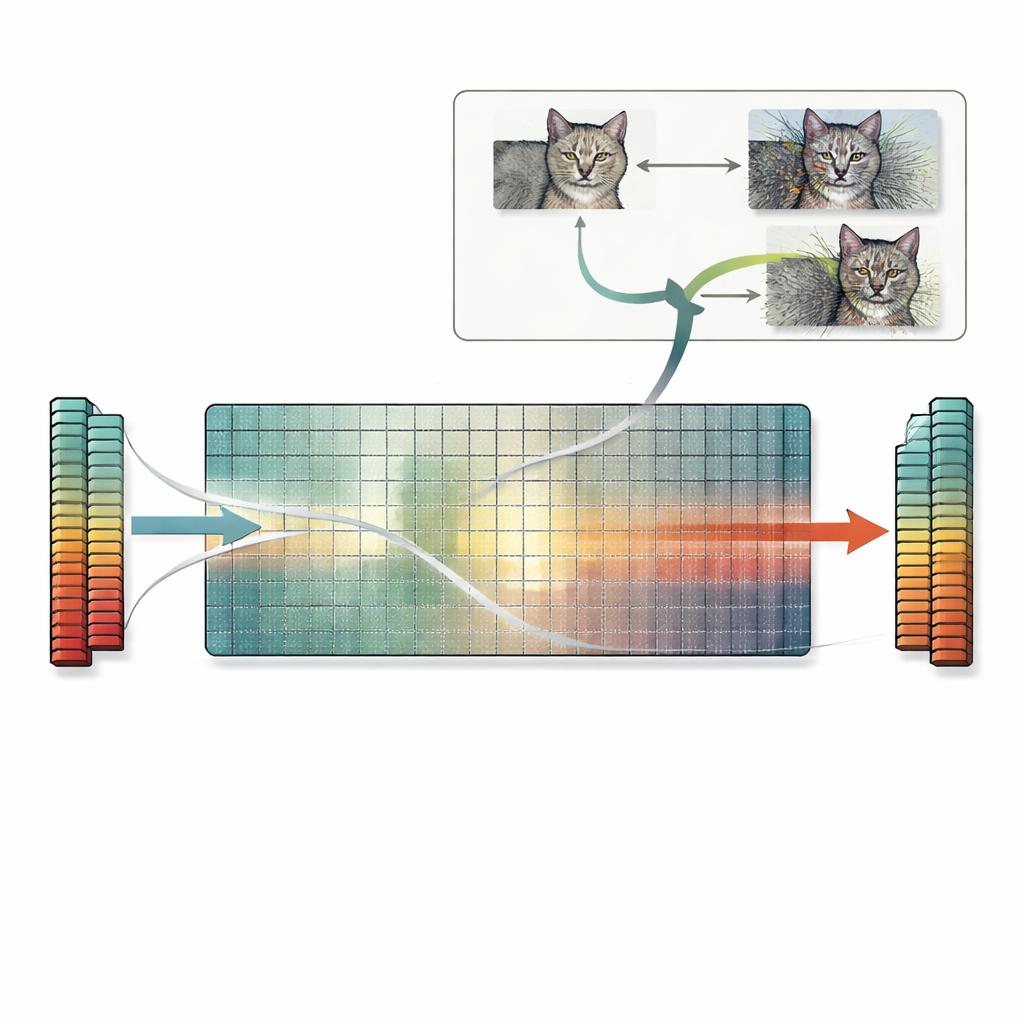
Verborgene Risiken für Ähnlichkeit, Erklärungen und Sicherheit
Diese exakten Merkmalskollisionen haben weitreichende Folgen. Zwei Bilder mit kollidierenden Merkmalen teilen nicht nur dieselbe Vorhersage, sondern oft auch dieselben Erklärungs‑Maps, die von gängigen Interpretierbarkeitswerkzeugen erzeugt werden. Das kann dazu führen, dass ein unkenntlich gemachtes, stark gestörtes Bild genauso gut durch Erklärungen gestützt erscheint wie ein sauberes, und damit das Vertrauen in Erklärmethoden untergraben. Das Problem betrifft auch merkmalsbasierte Ähnlichkeitsmaße, die auf neuronalen Netzen beruhen: Solche Metriken können ein stark korrumpiertes Bild als „identisch“ mit dem Original bewerten, weil die Merkmale exakt übereinstimmen, obwohl einfache pixelbasierte Scores große Unterschiede korrekt anzeigen. Schließlich lässt sich die Nullraum‑Suche mit standardmäßigen adversarialen Angriffen kombinieren und so viele verschiedene adversariale Bilder erzeugen, die alle dieselbe falsche Vorhersage liefern und innerhalb üblicher Perturbationsgrenzen bleiben, was die bestehenden Sicherheitsbedenken vertieft.
Was das für den Bau sichererer KI bedeutet
Kurz gesagt zeigt diese Arbeit, dass heutige neuronale Netze oft Informationen auf vorhersehbare Weise verwerfen und ganze Richtungen im Eingaberaum zurücklassen, die ihre Entscheidungen überhaupt nicht beeinflussen. Angreifer können diese Blindstellen ausnutzen, um bizarre oder adversariale Bilder zu erzeugen, die ein Netzwerk als identisch mit normalen Bildern behandelt. Die Autoren schlagen vor, einfache Zählungen dieser ignorierten Richtungen als Maß dafür zu verwenden, wie anfällig ein Modell sein könnte, und argumentieren, dass schlankere, besser regularisierte Netze mit kleineren Nullräumen robuster sein könnten. Zwar muss noch viel praktisch getestet werden, die zentrale Botschaft ist jedoch klar: Wenn wir verlässliche KI wollen, müssen wir nicht nur darauf achten, worauf Netze reagieren, sondern auch darauf, was sie ignorieren.
Zitation: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Schlüsselwörter: neuronale Netze, adversariale Beispiele, Merkmalskollisionen, Modell‑Robustheit, Nullraum‑Suche