Clear Sky Science · de
Datenschutzfreundliches föderiertes Lernen mit leichtgewichtigen, aufmerksamkeitsverbesserten CNNs zur automatisierten Leukämiedetektion über verteilte medizinische Bildgebung
Warum Wissensaustausch ohne Preisgabe von Geheimnissen wichtig ist
Die moderne Medizin verlässt sich zunehmend auf Computer, die medizinische Bilder lesen — von Röntgenaufnahmen bis zu Mikroskoppräparaten. Das Training solcher Systeme bedeutet jedoch meist, sensible Patientendaten an einem zentralen Ort zu sammeln, was erhebliche Datenschutzprobleme aufwirft. Diese Studie zeigt einen Weg, wie Krankenhäuser ein leistungsfähiges System zur Erkennung von Leukämie in Blutzellen aufbauen können, ohne jemals rohe Patientendaten auszutauschen; so werden Datenschutz und nahezu erstklassige diagnostische Genauigkeit kombiniert.
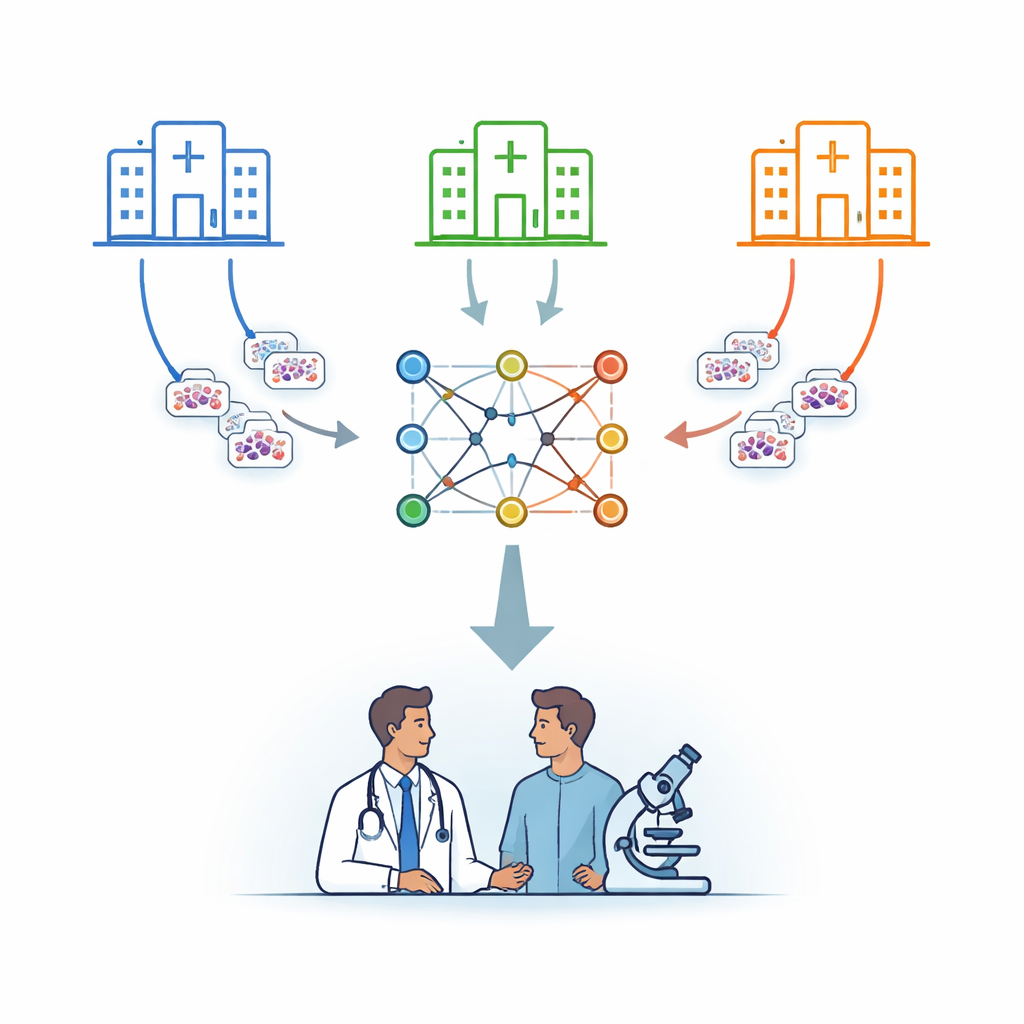
Viele Krankenhäuser, ein gemeinsames Modell
Die Forschenden konzentrieren sich auf Leukämie, eine Krebserkrankung des Bluts, die teilweise durch die mikroskopische Untersuchung von Zellen diagnostiziert wird. Statt Patient:innenbilder an einen zentralen Server zu senden, nutzen sie eine Strategie namens föderiertes Lernen. Dabei behalten mehrere Krankenhäuser ihre Bilder vor Ort und trainieren jeweils eine Kopie desselben Modells lokal. Periodisch werden nur die gelernten Modellparameter an einen sicheren Zentralserver geschickt, der sie mittelt und ein verbessertes kombiniertes Modell zurücksendet. Auf diese Weise wird Wissen gebündelt, während die zugrunde liegenden Bilder die jeweilige Einrichtung nie verlassen.
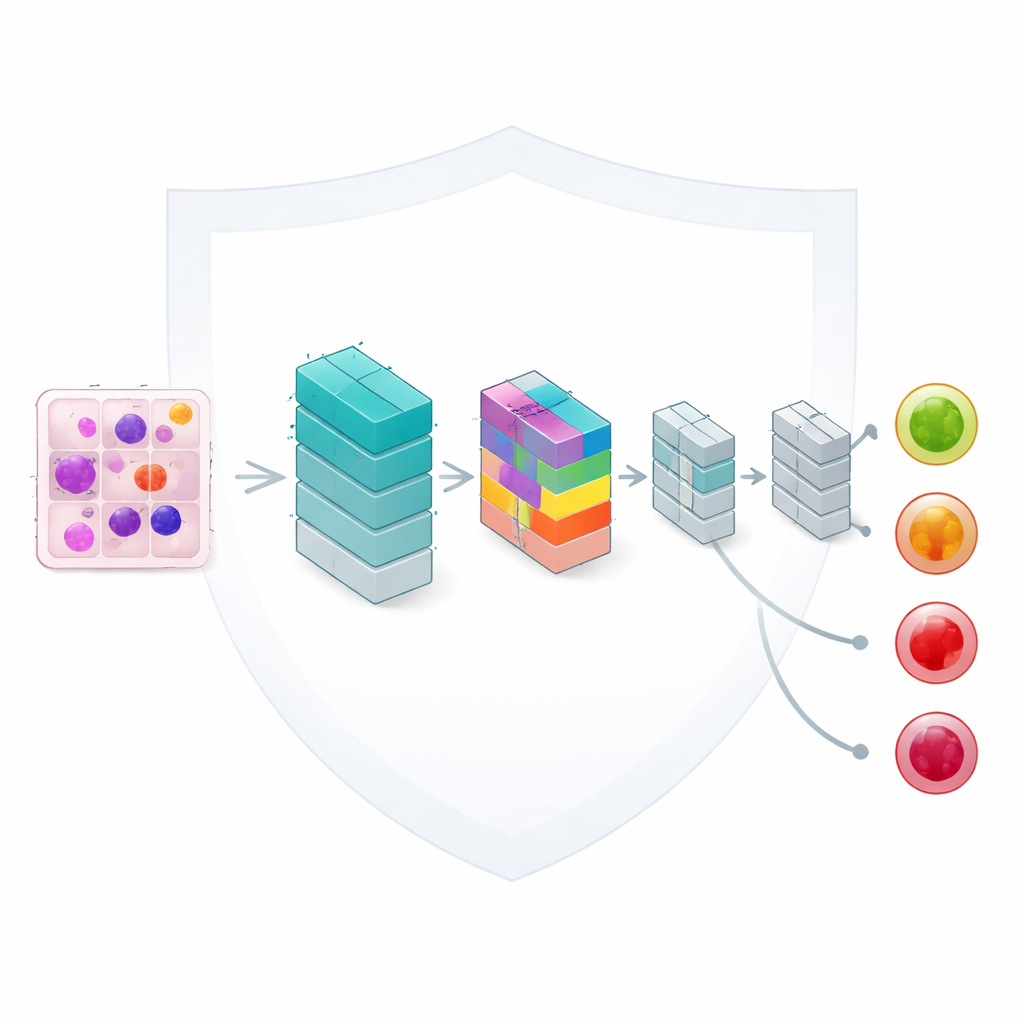
Ein kleines Netz dazu bringen, genau hinzuschauen
Im Kern des Frameworks steht ein leichtgewichtiges Bildanalysemodell auf Basis von Convolutional Neural Networks, einem Standardwerkzeug zur Bildverarbeitung. Die Autor:innen ergänzen es um einen kompakten "Attention"-Mechanismus, der dem Netzwerk hilft, sich auf die aussagekräftigsten Bereiche jeder Blutzelle zu konzentrieren, etwa die Form des Zellkerns und die Textur des umgebenden Materials. Obwohl das Modell nur etwa 33.000 einstellbare Parameter besitzt — ein Bruchteil der Größe vieler moderner Netze — kann es dennoch vier klinisch wichtige Kategorien unterscheiden: gutartige Zellen, frühe Veränderungen, prä-leukämische Zustände und voll entwickelte pro-leukämische Zellen. Durch sorgfältiges Design bleibt die Rechenlast gering genug für den praktischen Einsatz in Routine-Laboren.
Gerechtes Lernen aus ungleich verteilten und verstreuten Daten
In realen Gesundheitssystemen sehen Krankenhäuser nicht dieselbe Mischung an Patient:innen. Ein Zentrum bekommt vielleicht überwiegend Früherkrankungen, ein anderes mehr fortgeschrittene Fälle. Das Team bildet diese reale Ungleichverteilung bewusst nach, indem es einen Datensatz von 3.256 Blutausstrichbildern über mehrere simulierte Krankenhäuser mit unterschiedlichen Anteilen der einzelnen Leukämiestadien aufteilt. Anschließend analysieren sie, wie diese ungleiche Verteilung das Lernen beeinflusst, und nutzen statistische Maße, um zu quantifizieren, wie unterschiedlich die Daten der einzelnen Standorte sind und wie ähnlich deren finale Genauigkeiten ausfallen. Ein gewichtetes Mittelungsverfahren stellt sicher, dass Standorte mit mehr Daten einen entsprechend stärkeren Einfluss haben, während Leistungsunterschiede zwischen den Standorten sehr klein bleiben.
Genauigkeit, die zentralem Training ebenbürtig ist
Trotz fragmentierter und ungleich verteilter Daten lernt das gemeinsame Modell, Leukämiestadien mit beeindruckender Treffsicherheit zu klassifizieren. Bei drei simulierten Krankenhäusern erreicht das globale Modell etwa 95,7 % Genauigkeit auf zurückbehaltenen Testbildern; bei fünf Krankenhäusern und mehr Trainingsrunden steigt die Genauigkeit auf rund 96,6 %. Maligne Kategorien — jene, die prä-leukämische und fortgeschrittenere Erkrankungen darstellen — werden besonders gut erkannt und erreichen in manchen Fällen nahezu perfekte Werte. Die schwierigere, unterrepräsentierte gutartige Kategorie schneidet etwas schlechter ab, was den Bedarf an besserer Balance oder zielgerichteten Techniken für seltene, aber wichtige Klassen unterstreicht. Dennoch kommt das föderierte System in puncto Genauigkeit dem Ergebnis nahe, das erzielt würde, wenn alle Daten zentral zusammengeführt würden, und bewahrt gleichzeitig die Datenschutzvorteile lokaler Speicherung.
Die Entscheidungsfindung der Maschine sichtbar und vertrauenswürdig machen
Um Vertrauen bei Kliniker:innen aufzubauen, gehen die Autor:innen über die reine Genauigkeit hinaus und untersuchen, wie das Modell zu seinen Entscheidungen gelangt. Sie erzeugen visuelle Überlagerungen, die zeigen, welche Bildbereiche jeder Zelle die Vorhersage am stärksten beeinflusst haben. Diese Karten legen offen, dass sich das Modell auf medizinisch sinnvolle Merkmale konzentriert, etwa auf abnorme Kernformen in gefährlicheren Leukämiestadien, und bei gutartigen Zellen diffusere Muster zeigt. Das Team untersucht außerdem die Vorhersagesicherheit des Modells und stellt fest, dass korrekte Antworten tendenziell mit hoher Sicherheit einhergehen, insbesondere bei malignen Stadien — ein Hinweis auf eine gute Übereinstimmung zwischen der Zuversicht des Systems und seiner Verlässlichkeit.
Was das für die künftige Krebsdiagnostik bedeutet
Für Nicht-Fachleute ist die zentrale Botschaft: Krankenhäuser können nun gemeinsam intelligentere Krebsdiagnosen entwickeln, ohne die Bilddaten ihrer Patient:innen preiszugeben. Diese Arbeit zeigt, dass ein kompaktes, sorgfältig entworfendes Modell, das über föderiertes Lernen trainiert wird, die Genauigkeit traditioneller, datenpoolender Methoden annähern kann, während es Datenschutzregelungen und praktische Beschränkungen bei Rechenleistung und Netzwerkverkehr respektiert. Mit weiterer Arbeit zur besseren Behandlung unterrepräsentierter Zelltypen und zur Reduktion der Kommunikationskosten könnten ähnliche datenschutzschützende Systeme auf andere Krebsarten und bildgebende Tests ausgeweitet werden, sodass Kliniker:innen weltweit von gemeinsamem Erfahrungsschatz profitieren, ohne einzelne Patient:innen preiszugeben.
Zitation: Awan, M.Z., Khan, N.A., Strakos, P. et al. Privacy-preserving federated learning with light-weight attention improved CNNs for automated leukemia detection across distributed medical imaging. Sci Rep 16, 9768 (2026). https://doi.org/10.1038/s41598-026-40581-9
Schlüsselwörter: föderiertes Lernen, Leukämie-Bildgebung, medizinische KI und Datenschutz, aufmerksamkeitsbasiertes CNN, digitale Pathologie