Clear Sky Science · de
CMT-Unet: Nutzung eines stufenweisen hybriden Rahmens zur Verbesserung von Genauigkeit und Effizienz in der medizinischen Bildsegmentierung
Schärfere Einblicke in den Körper
Die moderne Medizin ist stark auf Bildgebungsverfahren wie CT und MRT angewiesen, doch aus diesen oft verschwommenen Graustufenaufnahmen klare Konturen von Organen und Geweben zu gewinnen, bleibt eine Herausforderung. Ärztinnen und Ärzte benötigen präzise Grenzen, um Operationen zu planen, die Herzfunktion zu überwachen oder zu messen, wie ein Tumor auf eine Behandlung reagiert. Diese Arbeit stellt einen neuen Computer-Vision-Ansatz vor, genannt CMT-Unet, der darauf ausgelegt ist, diese Grenzen genauer und effizienter zu zeichnen und so die automatisierte Bildanalyse einen Schritt näher an den klinischen Alltag zu bringen.
Warum Bildkonturen wichtig sind
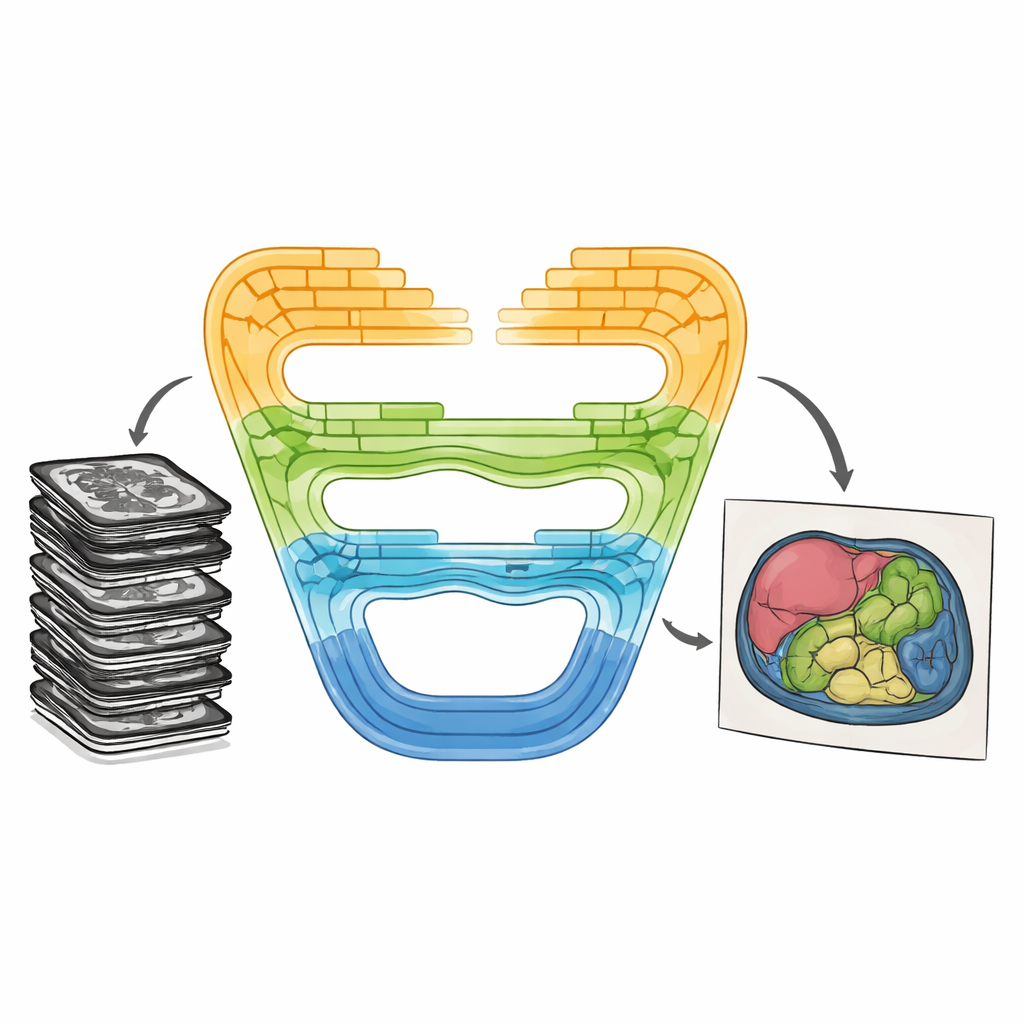
Vor einer Operation oder komplexen Therapie brauchen Klinikerinnen und Kliniker oft eine pixelgenaue Karte der Organe oder Strukturen in einem Scan – ein Prozess, der als Segmentierung bezeichnet wird. Traditionell zeichneten Experten diese Regionen von Hand nach, eine zeitaufwändige und ermüdende Aufgabe, die zu Variationen zwischen Beobachtern führen kann. Im letzten Jahrzehnt haben Deep-Learning-Methoden einen Großteil dieser Arbeit übernommen, insbesondere Modelle auf Basis von Convolutional Neural Networks und Transformer-ähnlichen Aufmerksamkeitsmechanismen. Faltungsmodelle sind besonders gut darin, feine lokale Details wie Kanten zu erfassen, während Transformer breiteren Kontext über das gesamte Bild hinweg abbilden können. Beide Ansätze haben jedoch Vor- und Nachteile: Faltungen können langfristige Beziehungen übersehen, während Transformer oft hohen Rechen- und Speicheraufwand erfordern.
Stärken auf neue Weise kombinieren
CMT-Unet begegnet diesen Kompromissen, indem es drei Arten von Bausteinen in einer stufenweisen Architektur verknüpft, statt sich im ganzen Netzwerk auf einen einzigen Typ zu verlassen. Am Anfang des Systems lernt eine invertierte Residual-Faltungseinheit schnell lokale Muster – scharfe Ränder und Texturen, die helfen, benachbarte Gewebe zu unterscheiden. In den mittleren Stufen überträgt ein Modul, das auf sogenannten Zustandsraummodellen basiert und von einer jüngeren Architektur namens Mamba adaptiert wurde, Informationen entlang von Sequenzen von Bildmerkmalen auf eine sowohl kontextbewusste als auch recheneffiziente Weise. Tiefer im Netzwerk teilen Transformer-Blöcke, ergänzt durch HiLo-Attention, die Informationen in hochfrequente und niederfrequente Komponenten auf, sodass das Modell sowohl winzige Details als auch grobe Organformen erfassen kann, bevor es sie wieder zusammenführt. Dieses geschichtete Design spiegelt den natürlichen Übergang von Rohpixeln zu abstrakter Bedeutung wider, wie Bilder verarbeitet werden.
Wie das neue Modell unter der Haube arbeitet
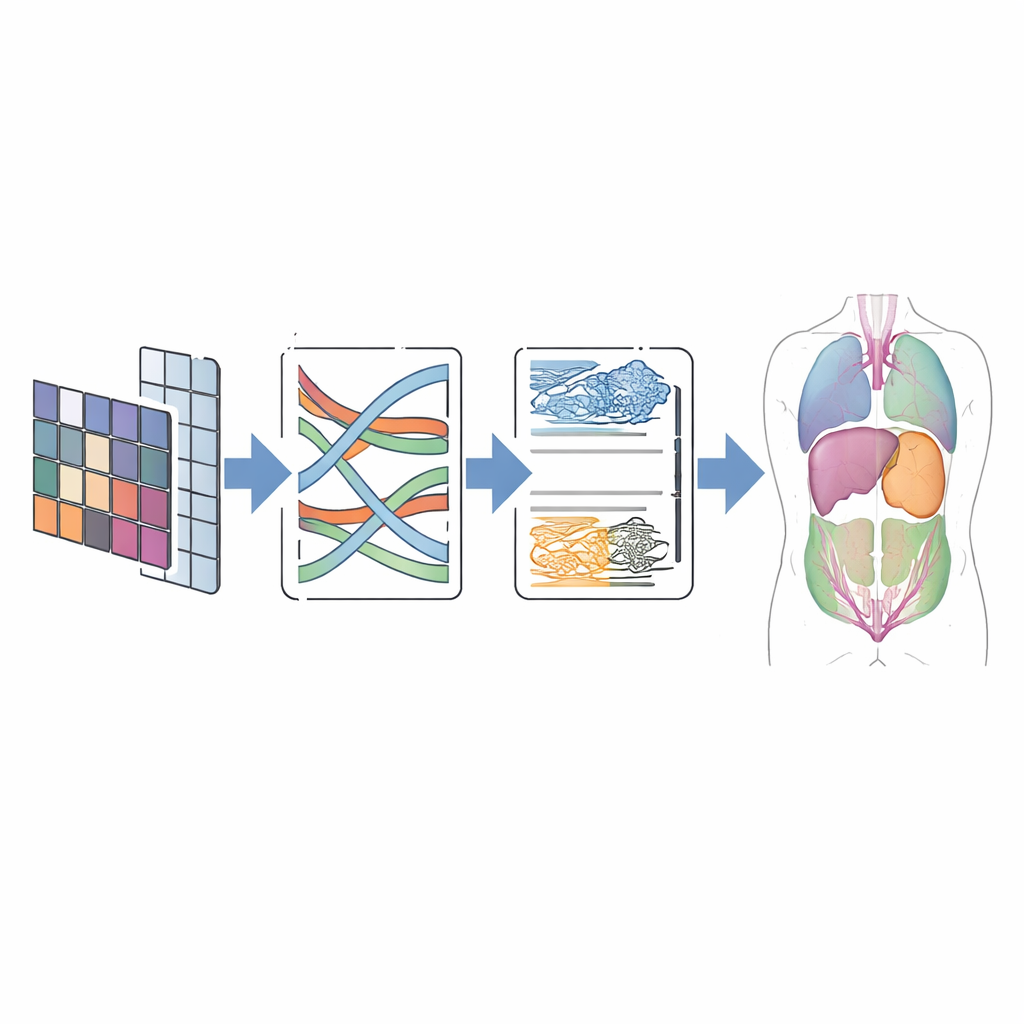
In der Praxis folgt CMT-Unet dem vertrauten U-förmigen Aufbau, der in der medizinischen Bildgebung beliebt ist: ein Encoder, der Informationen in reichhaltigere Merkmale komprimiert, ein Decoder, der eine Vorhersage in voller Größe rekonstruiert, und Skip-Verbindungen, die räumliche Details weiterreichen. Der entscheidende Unterschied liegt in den Modulen, die auf jeder Tiefe eingesetzt werden. Die frühe Faltungseinheit übernimmt die feinstrukturige Darstellung, die die Mamba- und Transformer-Komponenten andernfalls verschmieren könnten. Der modifizierte MambaVision-Block verbessert dann den mittleren Kontext, indem er räumliche Informationen durch speziell gestaltete zweidimensionale Operationen mischt und so die hohen Kosten vollständiger Attention vermeidet, während er trotzdem über lokale Patches hinausblickt. HiLo-Attention in der Transformer-Phase trennt explizit scharfe Kanten von glatten Hintergrundmustern und kombiniert diese so, dass Grenzen erhalten bleiben. Schließlich hilft ein duales Upsampling-Modul im Decoder dabei, saubere, durchgehende Konturen wiederherzustellen und gängige Artefakte wie Schachbrettmuster zu reduzieren.
Tests an realen Scans
Um zu beurteilen, ob dieses Design Vorteile bringt, testeten die Autorinnen und Autoren CMT-Unet an zwei weit verbreiteten öffentlichen Datensätzen. Der erste, Synapse genannt, enthält abdominale CT-Scans mit acht annotierten Organen, darunter Leber, Nieren und Magen. Der zweite, ACDC, umfasst kardiale MRT-Bilder mit Beschriftungen für die Herzventrikel und die Herzmuskulatur. Über diese Benchmarks hinweg erreichte CMT-Unet Segmentierungswerte, die mit führenden Faltungs-, Transformer- und hybriden Modellen gleichzogen oder besser waren, während es eine moderate Anzahl an Parametern und einen überschaubaren Rechenaufwand benötigte. Visuelle Vergleiche zeigten glattere und anatomisch konsistentere Grenzen, insbesondere in schwierigen Bereichen wie den Herzkammern, die für die Messung der Funktion und die Planung von Eingriffen entscheidend sind.
Was das für Patientinnen, Patienten und Kliniken bedeutet
Für Nicht-Fachleute ist die wichtigste Erkenntnis, dass CMT-Unet eine intelligentere Methode bietet, Strukturen in medizinischen Bildern nachzuzeichnen, indem es das jeweils passende Werkzeug für die jeweilige Verarbeitungsstufe auswählt. Durch das Ausbalancieren von lokalen Details und globalem Kontext kann das Modell genaue, saubere Organumrisse erzeugen, ohne Supercomputer-Ressourcen zu verlangen. Während sich die aktuelle Arbeit auf zweidimensionale Scans und eine begrenzte Auswahl öffentlicher Datensätze konzentriert, ist der Ansatz vielversprechend für zukünftige Erweiterungen auf dreidimensionale Bildgebung und breitere klinische Einsatzfelder. Bei weiterer Validierung könnte diese Art leichtgewichtiger, aber präziser Segmentierung schnellere Diagnosen, verlässlichere Therapieplanung und Echtzeitunterstützung in belebten Krankenhausumgebungen ermöglichen.
Zitation: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Schlüsselwörter: medizinische Bildsegmentierung, Deep Learning, hybride neuronale Netze, Zustandsraummodelle, medizinische Bildgebung