Clear Sky Science · de
Ein kNN-basierter Machine-Learning-Ansatz zur Automatisierung der Ursachenzuordnung bei unerwünschten Ereignissen
Warum das für Menschen, die Medikamente einnehmen, wichtig ist
Wenn ein neues Medikament auf den Markt kommt, beginnt seine Geschichte erst richtig. Millionen von Menschen werden es in der Praxis anwenden, und einige werden gesundheitliche Probleme erleben, die möglicherweise durch das Arzneimittel verursacht wurden — oder auch nicht. Zu klären, welche Reaktionen tatsächlich mit dem Wirkstoff zusammenhängen, ist für die Sicherheit der Patienten entscheidend. Heute ist diese Arbeit jedoch langsam, komplex und weitgehend manuell. Diese Studie untersucht, wie eine einfache, aber leistungsfähige Form künstlicher Intelligenz Experten dabei unterstützen kann, diese Sicherheitsberichte schneller und konsistenter zu prüfen, ohne das menschliche Urteil zu ersetzen, das letztlich die Patienten schützt.
Wie Sicherheitsfälle zu Daten werden
Pharmafirmen und Aufsichtsbehörden stützen sich auf individuelle Fall-Sicherheitsberichte, strukturierte Zusammenfassungen realer Erfahrungen mit Arzneimitteln. Jeder Bericht kann enthalten, was schiefgelaufen ist (zum Beispiel Kopfschmerzen oder Leberprobleme), wie schwerwiegend es war, welche anderen Medikamente und Erkrankungen vorlagen und wie der ursprüngliche Prüfer den Zusammenhang mit dem Arzneimittel einschätzte. Für mehr als 800.000 solcher Berichte zu sechs zugelassenen Arzneimitteln hatten die medizinischen Prüfer des Unternehmens bereits entschieden, ob jedes unerwünschte Ereignis dem Arzneimittel zuzuschreiben war, nicht zuzuschreiben war oder wegen fehlender oder widersprüchlicher Informationen nicht beurteilbar war. Die Forschenden nutzten dieses reichhaltige historische Material als Trainingsdaten für ein Computermodell, das lernen sollte, diese menschlichen Entscheidungen bei neuen Fällen zu imitieren.

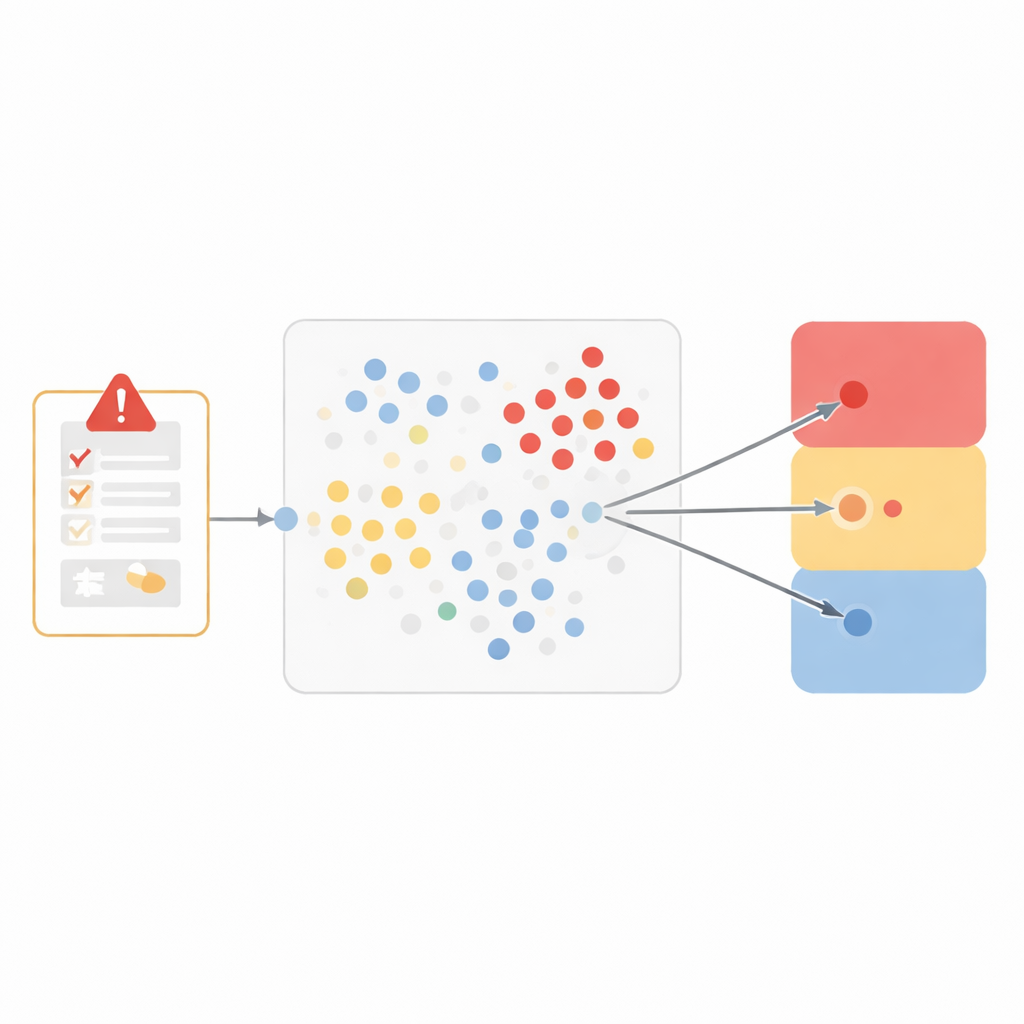
Dem Computer beibringen, ähnliche Fälle zu erkennen
Anstatt ein Black-Box-System zu bauen, entschieden sich die Forschenden für eine besonders transparente Methode, die «nächsten Nachbarn» genannt wird. Die Idee ist eingängig: Wenn zwei Fälle sich sehr ähneln, teilen sie wahrscheinlich dasselbe Fazit darüber, ob das Arzneimittel das Problem verursacht hat. Um Ähnlichkeit zu erfassen, stellten die Forschenden jedes unerwünschte Ereignis als siebenteiligen Steckbrief dar, einschließlich des medizinischen Begriffs für das Ereignis, was geschah, als das Arzneimittel abgesetzt und wieder aufgenommen wurde, ob das Problem für dieses Mittel zu erwarten war, die Einschätzung des Meldenden, andere eingenommene Medikamente, die Krankengeschichte und die Schwere des Ereignisses. Anschließend maßen sie, wie nahe sich zwei Fälle in diesem sieben-dimensionalen Raum befinden, wobei sie Merkmalen, die für die Kausalität am wichtigsten sind — wie das genaue Ereignis und die Reaktion bei Behandlungsänderungen — mehr Gewicht gaben.
Von der Nähe zur Drei-Wege-Entscheidung
Wenn ein neuer Bericht eingeht, durchsucht das Modell die historischen Daten nach den zehn ähnlichsten Fällen. Es prüft dann, wie diese Nachbarn klassifiziert wurden, und lässt sie unter drei breiten Ergebnissen «abstimmen»: wahrscheinlich arzneimittelbedingt, nicht arzneimittelbedingt bzw. unwahrscheinlich und nicht beurteilbar. Diese Drei-Wege-Einteilung findet einen Kompromiss zwischen klinischer Nuance und verlässlicher Leistung. Getestet an mehr als 250.000 zuvor ungesehenen Ereignissen stimmten die Modellvorhersagen bei als arzneimittelbedingt eingestuften Fällen sowie bei den als nicht beurteilbar klassifizierten Fällen eng mit den menschlichen Prüfern überein, mit geringen Fehlerquoten und starken Kennzahlen, die Genauigkeit und Vollständigkeit zusammenfassen. Schwierigkeiten hatte das Modell stärker bei der kleineren Gruppe klar nicht arzneimittelbedingter Ereignisse, was die Herausforderung widerspiegelt, der sich maschinelle Lernsysteme gegenübersehen, wenn ein Beispiels-Typ relativ selten ist.
Den Nebel des „nicht beurteilbar“ verringern
Ein praktisches Problem in der realen Sicherheitsarbeit ist, dass das Label «nicht beurteilbar» zum Auffangbecken wird, wenn Informationen dünn oder mehrdeutig sind, was das Erkennen echter Sicherheitsmuster erschwert. Die Forschenden ergänzten ein Abstimmungswerkzeug, das das Modell vorsichtiger macht, dieses Label zu vergeben. Anstatt «nicht beurteilbar» immer dann zu wählen, wenn es eine einfache Mehrheit unter ähnlichen Fällen erreicht, verlangt das Modell nun einen höheren Prozentsatz an unterstützenden Nachbarn für diese Wahl. Durch Anhebung dieses Schwellenwerts gelang es dem Team, die Häufigkeit, mit der das Modell einen Fall als nicht beurteilbar einstuft, deutlich zu reduzieren und die Leistung in den beiden anderen Kategorien zu verbessern, allerdings zu dem Preis, dass die Abweichungen bei den am schwierigsten zu beurteilenden Fällen etwas zunahmen. Ein webbasiertes Dashboard erlaubt es medizinischen Prüfern, diesen Schwellenwert produktspezifisch anzupassen, sofort zu sehen, wie sich die Verteilung der Ergebnisse verschiebt, und ihre Aufmerksamkeit auf Fälle zu lenken, in denen Modell und Mensch nicht übereinstimmen.
Was das für die Zukunft der Arzneimittelsicherheit bedeutet
Anhand einer Stichprobe jüngerer Fälle, die menschliche Prüfer als nicht beurteilbar markiert hatten, identifizierte das System Hunderte von Fällen mit abweichender Schlussfolgerung. Bei erneuter Begutachtung durch leitende Prüfer stimmten diese in mehr als zwei Dritteln der Fälle mit dem Modell überein, was zeigt, dass solche Werkzeuge übersehene Muster aufdecken und die Qualitätsaufsicht unterstützen können, ohne Experten zu ersetzen. Die Arbeit demonstriert, dass ein klares, Ähnlichkeits-basiertes Vorgehen künstliche Intelligenz in die Arzneimittelsicherheit bringen kann — erklärbar, einstellbar und mit der medizinischen Praxis vereinbar. Mit wachsendem Datenbestand und der Hinzunahme von Textnarrativen durch moderne Sprachtechnologien könnten Systeme dieser Art dazu beitragen, neu auftretende Risiken früher zu erkennen, wobei die klinische Entscheidungsgewalt weiterhin bei den Fachleuten liegt.
Zitation: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Schlüsselwörter: Pharmakovigilanz, unerwünschte Arzneimittelwirkungen, Ursachenzuordnung, maschinelles Lernen, k nächster Nachbar