Clear Sky Science · de
KM-DBSCAN: ein verbessertes dichte- und zentroidbasiertes Randdetektions‑Framework zur Datenreduktion für Green AI
Warum kleinere KI sie grüner machen kann
Künstliche Intelligenz hat einen versteckten Preis: Strom. Das Training moderner Machine‑Learning‑Modelle bedeutet oft, Millionen von Datenpunkten auf energieintensiver Hardware zu verarbeiten, was wiederum CO2‑Emissionen verursacht. Dieses Papier stellt KM‑DBSCAN vor, eine neue Methode, Datensätze vor dem Training zu verkleinern, ohne die für Modelle wichtigen Informationen zu verwerfen. Indem nur die informativsten Daten behalten werden, beschleunigt die Methode das Lernen, reduziert den Energieverbrauch und liefert dennoch genaue Vorhersagen bei Aufgaben von handgeschriebener Ziffernerkennung bis zur Früherkennung von Hautkrebs.
Zu viele Daten, zu viel Energie
Lange Zeit herrschte in der KI die Überzeugung, dass mehr Daten fast immer bessere Modelle ergeben. Das kann zwar die Genauigkeit verbessern, bedeutet aber auch längere Trainingszeiten, größere Rechner und höhere Stromkosten. Forschende unterscheiden zunehmend zwischen „Red AI“, die Genauigkeit um jeden Preis verfolgt, und „Green AI“, die Leistung mit Umweltverträglichkeit in Einklang bringen will. Ein vielversprechender Weg zu grünerer KI ist die Datenreduktion: Anstatt einem Modell jedes verfügbare Beispiel zu geben, identifiziert man eine wesentlich kleinere Menge an Fällen, die das Problem gut abbilden—insbesondere die schwierigen Randfälle, die die Entscheidungen eines Klassifikators bestimmen.
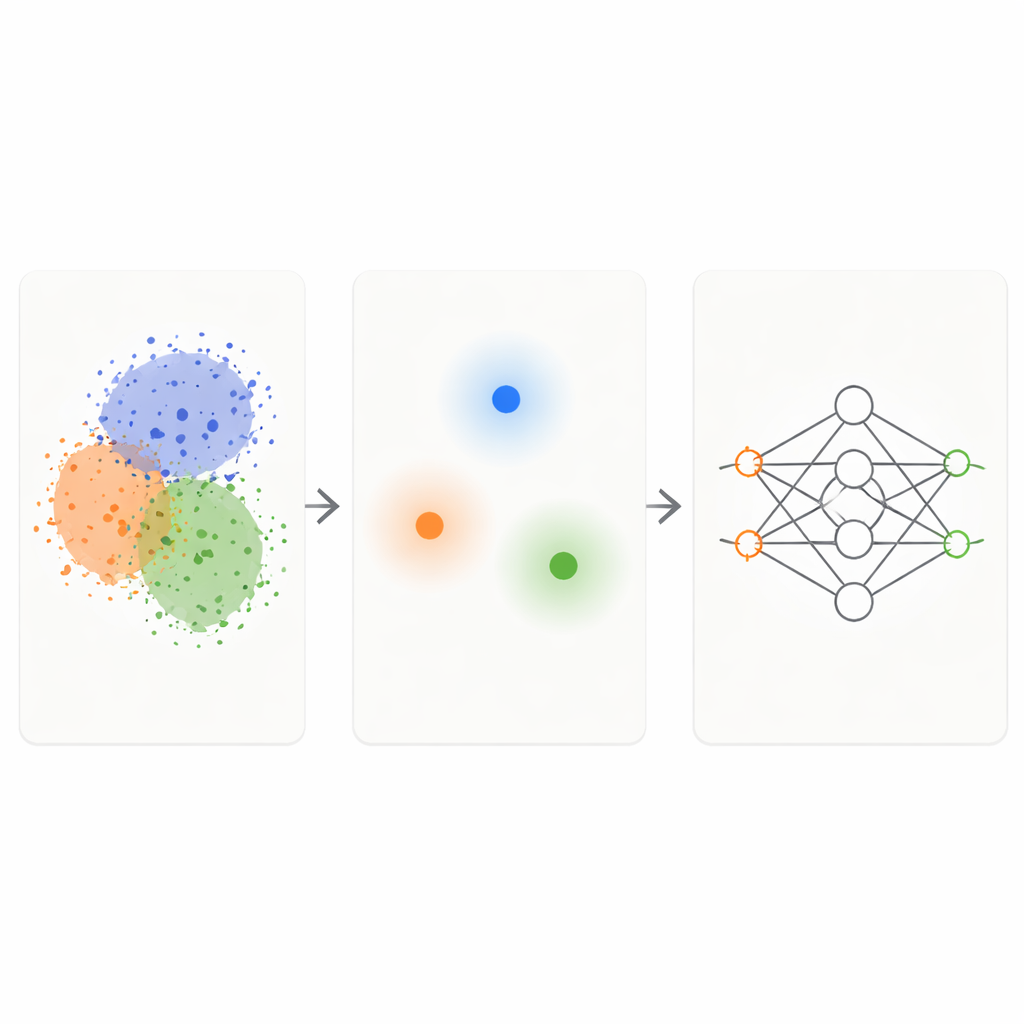
Zwei einfache Ideen zu einem smarten Filter vereint
Das KM‑DBSCAN‑Framework kombiniert zwei bekannte Clustering‑Techniken zu einem intelligenten Filter für Rohdaten. Zuerst gruppiert eine schnelle Methode namens K‑Means Punkte in kompakte Cluster und ersetzt jede Gruppe durch ein repräsentatives Zentrum, einen Zentroid. Dadurch schrumpft das Problem von Tausenden oder Millionen Punkten auf einige hundert repräsentative Punkte. Anschließend wird auf diesen Zentroiden eine dichtebasierte Methode (DBSCAN) ausgeführt, um zu erkennen, welche Regionen an den Rändern zwischen Clustern liegen und welche dichte, homogene Innenbereiche oder isoliertes Rauschen sind. Da DBSCAN auf Zentroiden arbeitet, wird es deutlich schneller und weniger empfindlich gegenüber kniffligen Parameterwahl als bei direkter Anwendung auf alle Datenpunkte.

Nur die schwierigen, informativen Fälle behalten
Sobald KM‑DBSCAN identifiziert hat, wo sich verschiedene Gruppen berühren oder überlappen, behält es nur die Datenpunkte, die in der Nähe dieser Ränder liegen, und verwirft sowohl tiefe Innenpunkte als auch eindeutige Ausreißer. Innenpunkte sind größtenteils redundant: Sie sehen einander ähnlich und vermitteln dem Modell dieselbe Information über ihre Klasse. Randpunkte hingegen zeigen dem Modell genau, wo eine Klasse endet und eine andere beginnt. Bei synthetischen Spielzeugdaten reproduziert diese Strategie dieselben Entscheidungsgrenzen, die ein Klassifikator aus den vollständigen Daten lernt, selbst wenn die meisten Punkte entfernt werden. Bei realen Datensätzen wie Banana, USPS‑Ziffern, dem Adult‑Einkommensdatensatz, Fahrzeugunfalldaten, Trockenbohnen‑Sorten und Melanom‑Hautbildern erhalten die reduzierten Mengen die Schlüsselstruktur des Problems, während sie um eine Größenordnung kleiner sind.
Geschwindigkeit, CO2‑Einsparungen und reale Anwendungen
Die Autorinnen und Autoren testeten KM‑DBSCAN als Vorverarbeitung für mehrere verbreitete Modelle, darunter Support‑Vector‑Machines, Multilayer‑Perzeptrons und Convolutional Neural Networks. In vielen Fällen war das Training auf den reduzierten Daten um das Zehn‑ bis Tausendfache schneller bei nahezu gleicher Genauigkeit—und manchmal sogar mit leichtem Genauigkeitsgewinn. Beispielsweise reduzierte die Methode bei handschriftlicher Ziffernerkennung den Trainingssatz auf nur 1,4 % der ursprünglichen Größe und erhöhte dennoch leicht die Genauigkeit, während das Training 284‑mal schneller wurde. In einer Einkommens‑Vorhersageaufgabe mit unausgeglichenen Klassen erzielte sie eine 6907‑fache Beschleunigung unter Verwendung von nur etwa 3 % der Daten bei minimalem Genauigkeitsverlust. In einem Melanom‑Erkennungs‑Experiment erreichte ein tiefes neuronales Netz über 90 % Genauigkeit, während es auf weniger als einem Drittel des ursprünglichen Hautbildsatzes trainierte, wobei die CO2‑Emissionen um mehr als 70 % reduziert wurden.
Was das für die alltägliche KI bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft: kluge Auswahl kann reiner Menge überlegen sein. KM‑DBSCAN zeigt, dass die sorgfältige Auswahl der Beispiele, die ein Modell sieht—Fokussierung auf die informativsten Randfälle—Rechenzeit und Energieverbrauch drastisch senken kann, während Vorhersagen zuverlässig bleiben. Dieser Ansatz passt zur breiteren Bewegung hin zu Green AI, in der die Qualität der Daten und ein durchdachtes Design der Trainingspipelines ebenso wichtig sind wie die rohe Modellgröße. Bei breiter Anwendung könnte eine solche datenbewusste Filterung alles von medizinischer Bildanalyse bis zu Verkehrssicherheitssystemen nachhaltiger machen und leistungsfähige KI‑Werkzeuge auch für Organisationen zugänglich machen, denen massive Rechenressourcen fehlen.
Zitation: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Schlüsselwörter: Green AI, Datenreduktion, Clustering, Effizienz im maschinellen Lernen, Melanom‑Erkennung