Clear Sky Science · de
R-GAT: Klassifizierung von Krebsdokumenten mittels graphbasierter Residualnetzwerke für Szenarien mit begrenzten Daten
Warum das Sortieren von Krebsartikeln wichtig ist
Jeden Tag veröffentlichen Wissenschaftler Hunderte neuer Studien zu Krebs, von Früherkennung bis zu vielversprechenden Medikamenten. Ein Großteil dieser Arbeiten erscheint zunächst als kurze Zusammenfassungen, sogenannte Abstracts. Ärztinnen und Ärzte, Forscherinnen und Forscher sowie politische Entscheider können unmöglich alles lesen — ein wichtiges Paper zu übersehen kann den Fortschritt verlangsamen. Diese Studie adressiert eine einfache, aber wirkungsvolle Frage: Lässt sich ein schnelles, ressourcenschonendes System entwickeln, das automatisch krebsbezogene Abstracts nach Krebsart sortiert, selbst wenn nur moderate Mengen an gelabelten Daten und begrenzte Rechenkapazität zur Verfügung stehen?
Ein schlauerer Weg, Krebsforschung zu lesen
Die Autoren konzentrieren sich auf vier Arten von Abstracts aus der PubMed-Datenbank: solche zu Schilddrüsenkrebs, Darmkrebs, Lungenkrebs und allgemeineren biomedizinischen Themen. Sie stellten eine sorgfältig geprüfte Sammlung von 1.875 aktuellen Abstracts zusammen, annähernd gleich verteilt auf diese vier Gruppen. Diese Ausgewogenheit hilft, eine Verzerrung zugunsten einer einzelnen Krebsart zu vermeiden. Vor dem Modellieren wurden die Texte bereinigt: Wörter in Token zerlegt, Rechtschreibung geprüft, verwandte Wortformen zusammengeführt und unwichtige Begriffe entfernt. Die bereinigten Abstracts wurden anschließend mit mehreren Standardmethoden numerisch dargestellt, damit verschiedene Modelltypen fair verglichen werden können.
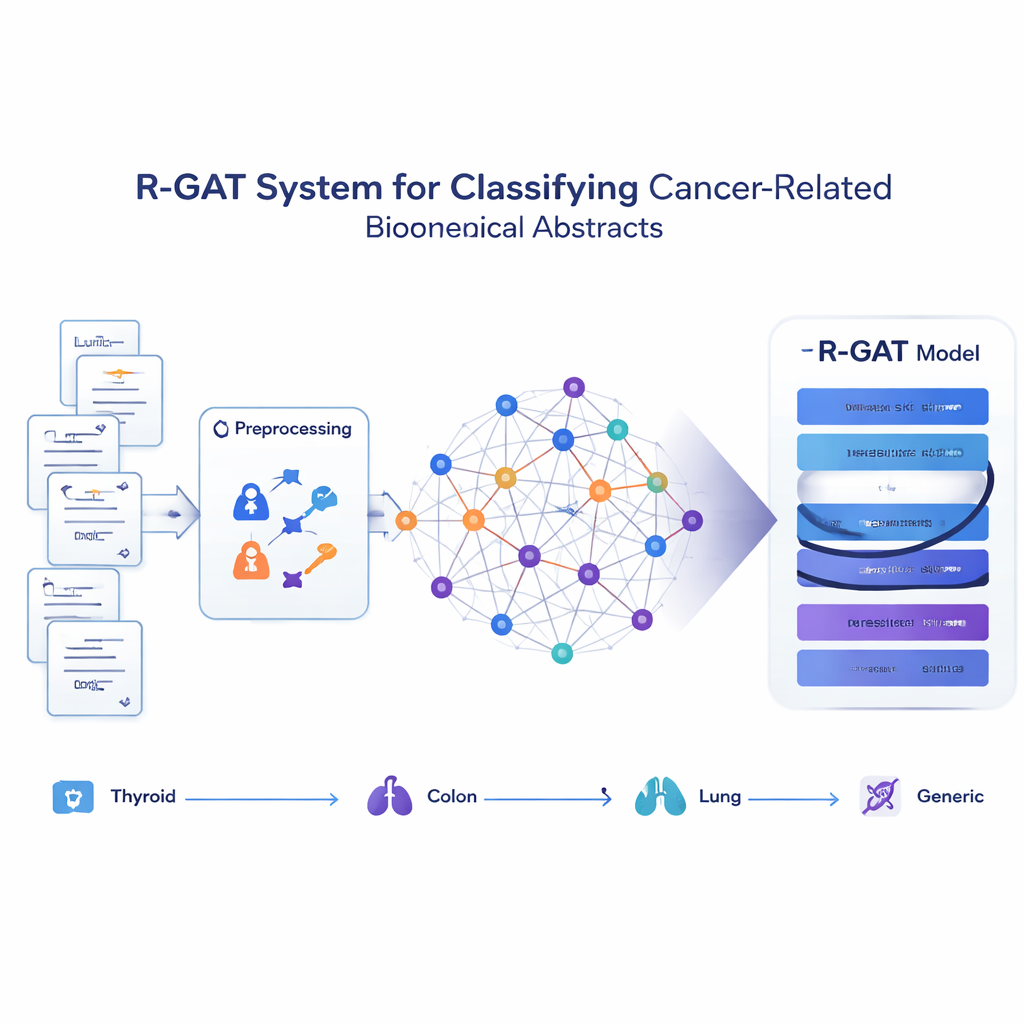
Artikel in ein Netzwerk von Ideen verwandeln
Anstatt jedes Abstract als isolierte Wortfolge zu behandeln, betrachtet die vorgeschlagene Methode R-GAT (Residual Graph Attention Network) die gesamte Sammlung als Netzwerk. In diesem Netzwerk ist jedes Abstract ein Knoten und Verbindungen drücken aus, wie ähnlich sich zwei Abstracts inhaltlich sind. Wenn zwei Arbeiten verwandte Themen behandeln, ist die Verbindung zwischen ihnen stark; andernfalls ist sie schwach oder fehlt. Dadurch kann das Modell ein Abstract im Kontext seiner Nachbarn bewerten und damit dem Vorgehen eines menschlichen Lesers ähneln, der eine Studie besser versteht, wenn er weiß, was verwandte Arbeiten aussagen.
Wie das neue Modell von Nachbarn lernt
R-GAT baut auf zwei Schlüsselideen der modernen künstlichen Intelligenz auf: Attention und Residual-Verbindungen. Attention ermöglicht es dem Modell, sich stärker auf die relevantesten Nachbar-Abstracts im Netzwerk zu konzentrieren, anstatt alle Nachbarn gleich zu behandeln. Mehrere Attention-»Köpfe« suchen gleichzeitig nach unterschiedlichen Mustern. Residual-Verbindungen wirken wie Abkürzungen, die Informationen durch die tieferen Schichten des Netzwerks weiterreichen und dem Modell helfen, wichtige Signale beim Lernen nicht zu verlieren. Nachdem der Graph durch mehrere Attention-Schichten und diese Shortcut-Pfade verarbeitet wurde, kondensiert das System die Informationen aus dem gesamten Netzwerk zu einer kompakten Darstellung, die an einen finalen Klassifikator übergeben wird, der vorhersagt, zu welcher der vier Kategorien jedes Abstract gehört.
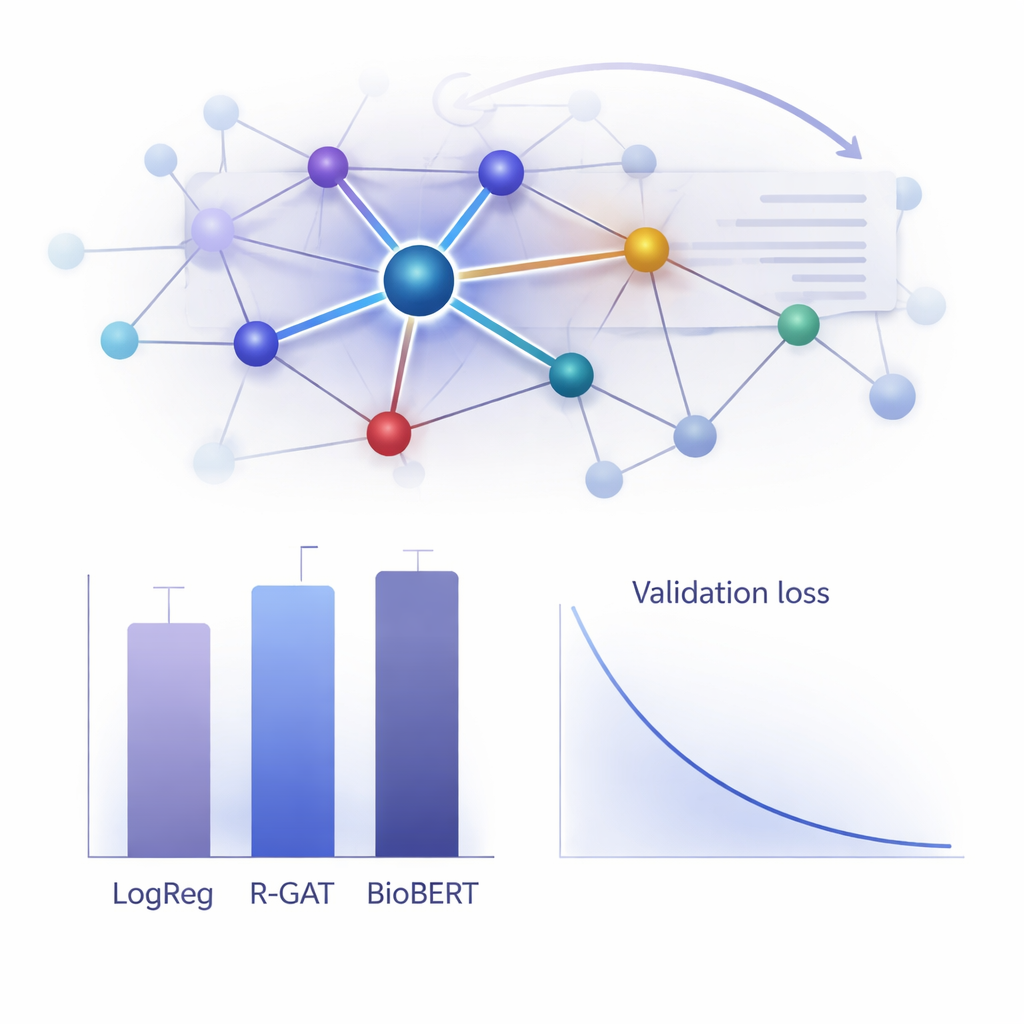
Wie gut funktioniert es in der Praxis?
Um den Wert von R-GAT zu beurteilen, verglichen die Autoren es mit einer breiten Palette von Alternativen, von klassischen linearen Modellen bis hin zu modernen Transformer-Systemen wie BioBERT, die zwar leistungsfähig, aber rechenintensiv sind. Überraschenderweise erzielte ein einfaches logistisches Regressionsmodell mit Wortzählfeatures in diesem Datensatz den höchsten Rohwert, und auch BioBERT schnitt extrem gut ab — beide Ansätze haben jedoch Nachteile, etwa Abhängigkeit von spezifischen Feature-Entscheidungen oder den Bedarf an beträchtlichen Rechenressourcen. R-GAT erreichte eine makro F1-Score von etwa 0,96, also nahe an den besten Modellen, und zeigte dabei sehr stabile Ergebnisse über verschiedene Trainings-Test-Aufteilungen hinweg. Sorgfältige Tests, bei denen Attention oder Residual-Verbindungen entfernt wurden, führten zu deutlichen Leistungseinbußen und bestätigten, dass beide Komponenten für die Robustheit des Modells bei begrenzten Daten entscheidend sind.
Was das für die zukünftige Krebsforschung bedeutet
Für Laien ist die Schlussfolgerung klar: R-GAT ist ein praxisnahes Werkzeug, das Krebsforschungsartikel nach Krebsart mit hoher und konsistenter Genauigkeit sortiert, ohne riesige Datensätze oder teure Hardware zu benötigen. Es ersetzt nicht die leistungsstärksten Sprachmodelle auf dem Markt, bietet aber einen verlässlichen Mittelweg — besonders nützlich für Krankenhäuser, Forschungsgruppen oder Gesundheitsämter, die belastbare, reproduzierbare Ergebnisse unter engen Daten- und Budgetbedingungen benötigen. Indem die Autoren sowohl ihr Modell als auch ihren kuratierten Datensatz offen zugänglich machen, liefern sie zudem einen gemeinsamen Benchmark, den andere zum Aufbau und Test verbesserter Systeme nutzen können. Langfristig könnten solche Werkzeuge es Expertinnen und Experten erheblich erleichtern, in der Krebsforschung auf dem Laufenden zu bleiben und neue Erkenntnisse in bessere Versorgung umzusetzen.
Zitation: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Schlüsselwörter: Krebsinformatik, biomedizinisches Text-Mining, Dokumentklassifikation, graphneuronale Netze, Lernen mit begrenzten Daten