Clear Sky Science · de
EchoNet++: Ein mehrsprachiges Audio-Kommentar-Datensatz für Fußballspiele
Warum Fußball-Geräusche wichtig sind
Wer ein großes Spiel gesehen hat, weiß: Das Rauschen der Menge und die Modulation der Stimme des Kommentators gehören genauso zur Dramatik wie die Tore selbst. Trotzdem konzentriert sich fast die gesamte moderne Sporttechnologie weiterhin auf das, was Kameras sehen, und nicht auf das, was Mikrofone hören. Dieses Papier stellt EchoNet und EchoNet++ vor, ein kombiniertes System und Datensatz, das das chaotische Klangbild professioneller Fußballübertragungen aus vielen Ländern in sauberen, durchsuchbaren Text verwandelt, den Computer analysieren können. Damit lassen sich Taktik, Emotion und Erzählen über Ligen und Sprachen hinweg in einem Umfang untersuchen, den kein menschliches Übersetzerteam erreichen könnte.
Vom lauten Stadion zum sauberen Signal
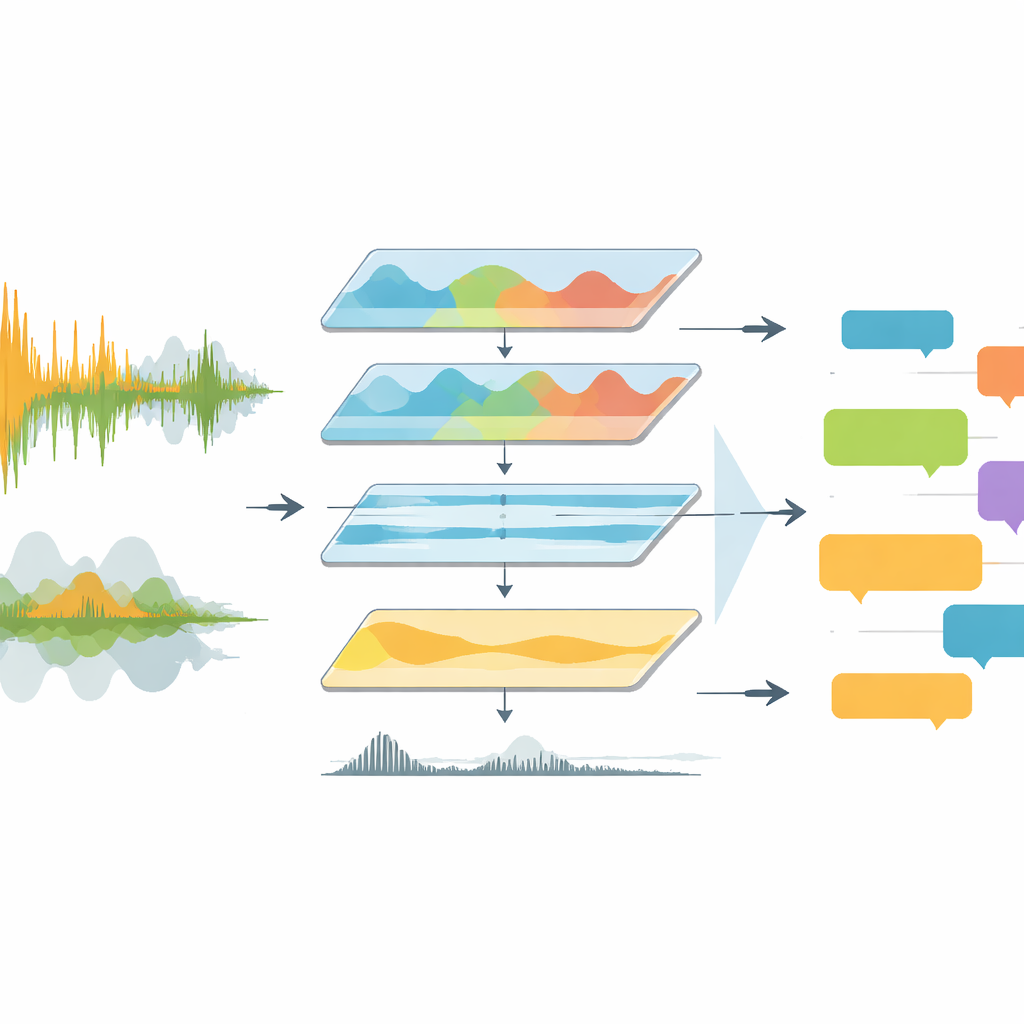
Fernsehübertragungen sind akustisch unordentlich. Kommentatoren sprechen über singende Fans, Stadionmusik und plötzliche Ausbrüche von Jubel hinweg. Bisherige Werkzeuge fütterten diese rohe Geräuschkulisse meist direkt in Spracherkennungssoftware, die mit überlappenden Stimmen, wechselnden Sprachen und schlechter Audioqualität kämpfte. EchoNet begegnet dem Problem als Ingenieur-Pipeline statt als einziges cleveres Modell. Zunächst wird die Audiospur aus den kompletten Spielvideos extrahiert und in ein standardisiertes, hochwertiges Format konvertiert. Das System wechselt dann in den Frequenzbereich, konzentriert sich auf den Bereich, in dem menschliche Sprache liegt, und unterdrückt dröhnende Tieftöne und schrille Artefakte. Ein Deep-Learning-Tool namens Demucs trennt zusätzlich sprachähnliche Klänge vom Rest, wodurch eine deutlich klarere Spur für die weiteren Verarbeitungsstufen bleibt.

Maschinen beibringen, Stimmen von Lärm zu unterscheiden
Sobald der Klang bereinigt ist, muss EchoNet entscheiden, wann tatsächlich gesprochen wird und ob eine Stimme zum Kommentator oder zur Menge gehört. Dafür nutzen die Autoren einen neuronalen Voice-Activity-Detector, der das Audio in kurzen Fenstern scannt und jeden Moment als Sprache oder Nicht-Sprache kennzeichnet. Erkannte Sprachabschnitte werden dann genauer untersucht. Segmente, die den gleichmäßigen Rhythmus und die Struktur gesprochener Sprache zeigen, werden als Kommentar markiert, während jene, die wie Ausbrüche chaotischer Energie aussehen, als Zuschauer gekennzeichnet werden. Diese Trennung ist wichtig: Kommentatoren-Sätze transportieren taktische und erzählerische Bedeutung, während Zuschauereaktionen meist emotionale Höhepunkte wie Tore oder knappe Chancen signalisieren. Durch die Aufspaltung kann das System die Quellen in späteren Analysen unterschiedlich behandeln.
Viele Sprachen zu einer einzigen Geschichte machen
EchoNet speist jedes Kommentarsegment in mehrere Varianten des Whisper-Spracherkennungsmodells, einschließlich Standard- und geschwindigkeitsoptimierter Versionen. Diese Modelle sind auf Hunderttausenden von Stunden mehrsprachiger Audiodaten trainiert, was sie gut geeignet macht für Europas große Ligen, in denen Broadcaster zwischen Englisch, Deutsch, Spanisch, Italienisch, Französisch und anderen Sprachen wechseln. Das System zeichnet Timing, Sprache und Transkript jedes Segments in strukturierten JSON-Dateien auf, die an die Spielhälften gebunden sind. Bei nicht-englischen Clips transkribiert EchoNet zuerst in der Originalsprache und übergibt den Text dann an eine Übersetzungsengine, um englische Versionen zu erhalten. Dieses Zweischritt-Design hält Transkriptions- und Übersetzungsfehler getrennt, was Forschern hilft, Fehler zu analysieren und sprachspezifisches Verhalten zu vergleichen.
Wie gut das alles funktioniert
Da eine Pipeline nur so stark ist wie ihr schwächstes Glied, bewerten die Autoren EchoNet aus mehreren Blickwinkeln. Sie führen eine neue „Report Accuracy“-Metrik ein, die traditionelle Wortfehlerraten in einen intuitiveren Prozentsatz praktisch korrekten Inhalts umwandelt. Über drei Datensätze hinweg – einschließlich ihrer neu veröffentlichten EchoNet++-Sammlung von 20 kompletten Spielen – senkt die Vorverarbeitung mit EchoNet beständig die Transkriptionsfehler und erhöht die Report Accuracy um mehrere Punkte für jedes getestete Whisper-Modell. Maße zur Signalqualität, die abschätzen, wie verständlich die Sprache für einen menschlichen Zuhörer wäre, verbessern sich ebenfalls deutlich nach Filterung, Rauschunterdrückung und Normalisierung. Ablationsstudien, bei denen einzelne Komponenten wie der Bandpassfilter oder der Sprachdetektor entfernt werden, zeigen, dass jede Stufe sowohl zur Klarheit als auch zur Korrektheit beiträgt.
Was das für Fans und Analysten bedeutet
Alltagsbezogen bieten EchoNet und EchoNet++ eine verlässliche Methode, um Stunden lauter, mehrsprachiger Spielkommentare in sauberen, zeitlich ausgerichteten Text und Zuschauerindikatoren zu verwandeln. Darauf aufbauend können Entwickler automatisch Schlüsselmomente aus Tonfall und Wortwahl des Kommentators erkennen, diese Momente mit Ausbrüchen der Publikumsreaktion abgleichen und detaillierte Zusammenfassungen oder Highlight-Reels ohne manuelle Protokollierung erstellen. Entscheidend ist, dass Datensatz und Code für die Forschung freigegeben werden, wodurch die Community eine gemeinsame, reproduzierbare Plattform erhält, um Fußball durch Klang zu untersuchen. Für Fans und Analysten gleichermaßen lenkt diese Arbeit die Sportberichterstattung in eine Zukunft, in der der Soundtrack des Spiels ebenso durchsuch- und analysierbar wird wie das Video selbst.
Zitation: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Schlüsselwörter: Fußball-Analytik, Sport-Audio, Spracherkennung, mehrsprachige Kommentare, Sendungsanalyse