Clear Sky Science · de
Quersvalidierung in die Praxis bringen, um die Übertragbarkeit satellitengestützter Vegetationsmodelle zu bewerten
Warum es wichtig ist, Gras aus dem All zu beobachten
Grasländer ernähren Nutztiere, unterstützen die Tierwelt und speichern Kohlenstoff. Viele Viehhalter und Naturschützer verlassen sich mittlerweile auf Satelliten, um den Vorrat an Pflanzenmaterial am Boden zu überwachen. Neue Karten versprechen nahezu Echtzeit‑Einblicke in den Zustand der Weiden, doch ihre Genauigkeit in ungewöhnlichen Jahren – etwa bei starker Dürre oder sehr nassen Saisons – wird oft unhinterfragt angenommen. Diese Studie stellt eine einfache, aber entscheidende Frage: Wie gut halten die Computermodelle hinter diesen Satellitenkarten stand, wenn die reale Welt nicht so aussieht wie die Daten, mit denen sie trainiert wurden?
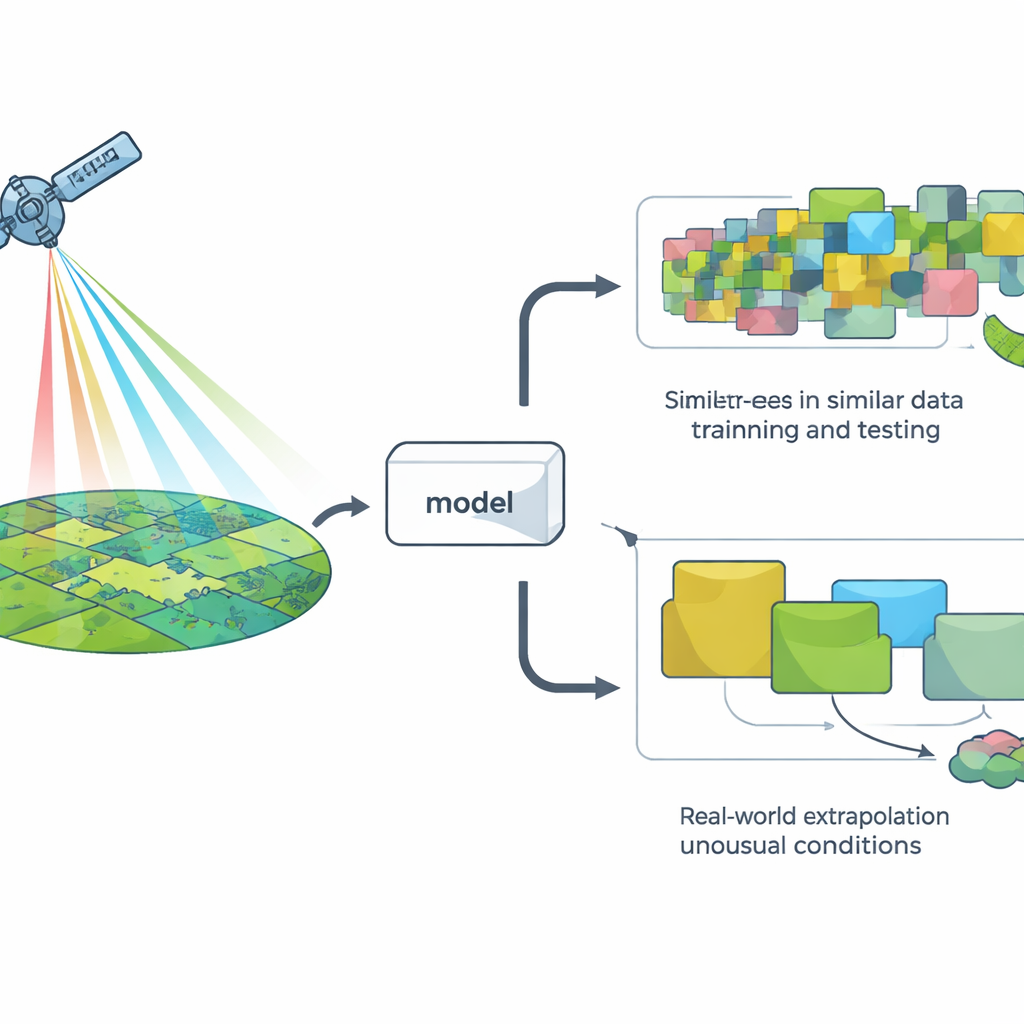
Modelle auf die leichte versus die harte Tour prüfen
Um ein Modell zu bewerten, verwenden Forschende üblicherweise eine Methode namens Quersvalidierung: Sie verstecken einige Daten, trainieren das Modell mit dem Rest und prüfen, wie gut es die versteckten Punkte vorhersagt. Die gängigste Variante teilt die Daten zufällig auf, was für viele Probleme gut funktioniert, aber stillschweigend voraussetzt, dass alle Beobachtungen unabhängig sind. In Landschaften bricht diese Annahme häufig zusammen: räumlich nahe Orte und benachbarte Jahre ähneln sich oft in den Satellitenaufnahmen. Dadurch können zufällige Aufteilungen den Eindruck erwecken, ein Modell würde mit „neuen“ Situationen konfrontiert, obwohl es in Wirklichkeit meist mehr vom Gleichen sieht.
Satellitenmodelle echten Tests aussetzen
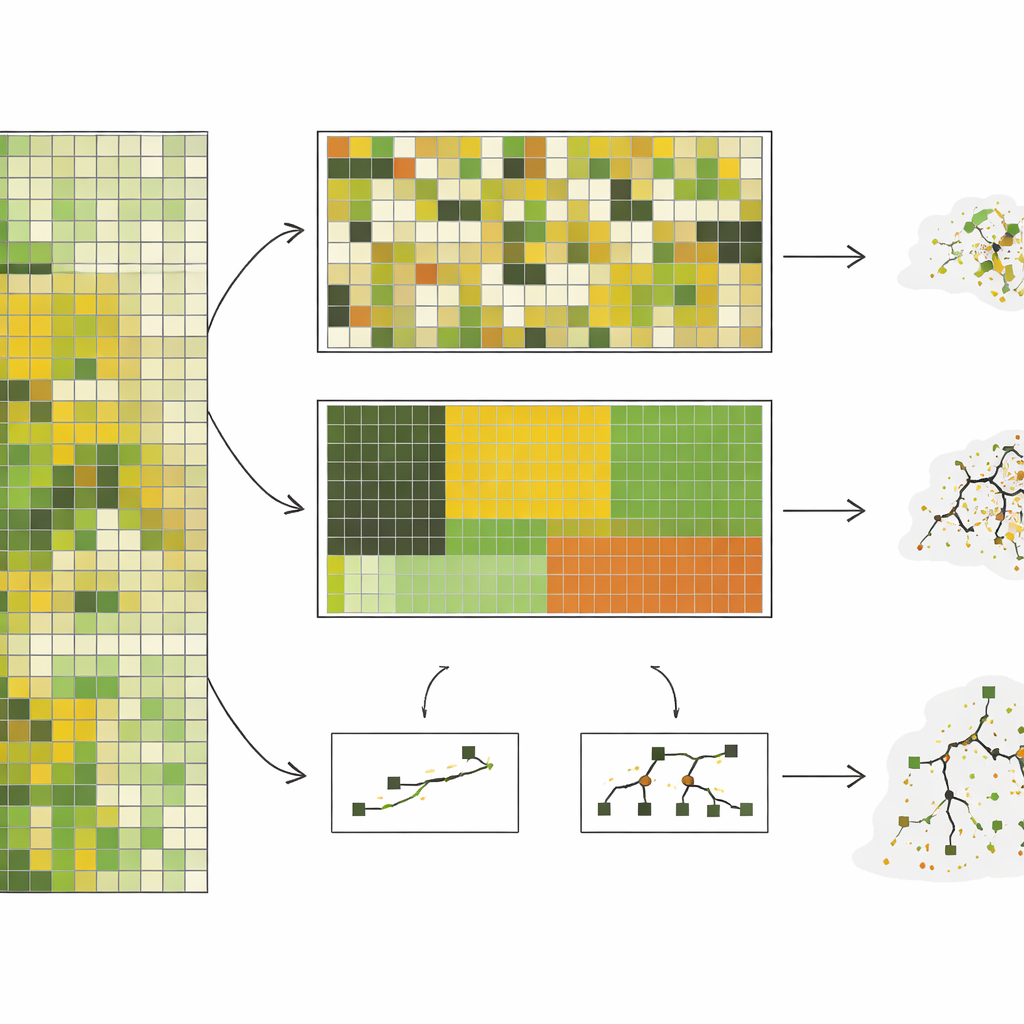
Die Autorinnen und Autoren versammelten fast 10.000 Feldmessungen der stehenden krautigen Biomasse – im Wesentlichen, wie viel weidebares Pflanzenmaterial vorhanden ist – aus einer Kurzgrassteppe in Colorado, erfasst über 10 Jahre. Sie kombinierten diese Messungen mit detaillierten Satellitenbildern und trainierten dann sieben verschiedene Modelltypen, von einfachen linearen Ansätzen bis zu komplexen Entscheidungsbaum‑Systemen. Statt nur zufällige Aufteilungen zu nutzen, testeten sie fünf Arten, Daten zurückzuhalten: nach zufällig ausgewählten Parzellen, nach Weideblöcken, nach ökologischen Standorttypen, nach Jahr und nach Pixelgruppen, die spektral unterschiedlich wirkten. Besonders die letzten beiden Ansätze – Gruppierung nach Jahr und nach spektralen Clustern – zwangen die Modelle, für Bedingungen zu prognostizieren, die wirklich anders waren als das, was sie zuvor gesehen hatten.
Wenn die Zukunft anders aussieht als die Vergangenheit
Über alle Modelle hinweg sank die Leistung deutlich, je anspruchsvoller die Tests wurden. Bei zufälligen Aufteilungen wirkten komplexe Modelle wie Random Forests eindrucksvoll und erklärten etwa drei Viertel der Biomasse‑Variation. Wurden sie jedoch gebeten, für ein völlig ungesehenes Jahr vorherzusagen – eine realistische Aufgabe für die Echtzeitüberwachung – fiel ihre Genauigkeit, und relativ einfache Modelle, die auf wenigen kombinierten Satellitenvariablen basierten, schnitten ebenso gut oder besser ab. Im extremsten Test, bei dem die Daten so unterschiedlich wie möglich gruppiert wurden, brach die Genauigkeit der komplexen Modelle ein, während die besseren einfachen Modelle moderate, besser vorhersagbare Leistungen beibehielten. Die Studie zeigte außerdem, dass komplexe Modelle sehr empfindlich darauf reagieren, ob seltene Bedingungen wie schwere Dürre im Trainingssatz vertreten sind; in solchen kritischen Szenarien konnten sie mitunter sehr schlecht abschneiden.
Stabile Arbeitstiere übertreffen glänzende Sprinter
Über die reine Genauigkeit hinaus untersuchte das Team, wie beständig jedes Modell ist, wenn es mit leicht unterschiedlichen Jahresuntergruppen neu trainiert wird. Einfachere Methoden, insbesondere die partielle kleinste Quadrate‑Regression, tendierten dazu, immer wieder dieselben wichtigen Satellitensignale herauszufiltern, benötigten nur wenige Einstellungen zur Feinabstimmung und lieferten stabilere Ergebnisse über die Jahre. Komplexere Ansätze wechselten oft die Inputs, auf die sie sich stützten, erforderten viele unterschiedliche Hyperparameter‑Einstellungen und zeigten große Schwankungen in der Leistung zwischen einzelnen Trainingsläufen. Für Landmanager, die Karten jährlich aktualisieren müssen, wenn neue Daten eintreffen, kann eine solche Stabilität genauso wichtig sein wie die Spitzenleistung in einem günstigen Jahr.
Was das für die Nutzung satellitengestützter Karten vor Ort bedeutet
Für diejenigen, die sich auf satellitengestützte Vegetationskarten verlassen, um zu entscheiden, wann und wo Tiere weiden sollen, auf Dürre zu reagieren oder den Zustand von Ökosystemen zu verfolgen, enthält diese Studie eine klare Botschaft. Übliche Testgewohnheiten, die Daten zufällig durchmischen, können ein zu optimistisches Bild davon zeichnen, wie ein Modell bei Wetterextremen oder an neuen Orten abschneiden wird. Werden Modelle auf eine Weise bewertet, die ihrer realen Nutzung ähnelt – etwa durch Vorhersagen für neue Jahre, neue ökologische Bedingungen oder seltene Szenarien – können einfachere, gut handhabbare Methoden anspruchsvollere Modelle übertreffen und verlässlichere Hinweise liefern. In der Praxis sollten Entwicklerinnen und Entwickler berichten, wie ihre Modelle unter mehreren härteren, realistischeren Prüfungen abschneiden, und Anwender sollten Produkte bevorzugen, deren Leistung in den herausfordernden Situationen geprüft wurde, denen sie am ehesten begegnen werden.
Zitation: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Schlüsselwörter: satellitengestützte Vegetationskartierung, Quersvalidierung, Graslandbiomasse, Maschinelle Lernmodelle, Dürreüberwachung