Clear Sky Science · de
Robuste Orterkennung bei Beleuchtungsänderungen mithilfe von Pseudo-LiDAR aus omnidirektionalen Bildern
Roboter, die sich in der Dunkelheit nie verirren
Stellen Sie sich einen Roboter vor, der in einem Gebäude weiß, wo er sich befindet – ganz gleich, ob es mittags mit Sonnenstrahlen durch die Fenster ist oder spät in der Nacht mit nur wenigen Lampen. Diese Arbeit stellt eine neue Methode vor, um Robotern genau dieses zuverlässige Ortsbewusstsein nur mit einer einzigen, relativ günstigen Kamera zu geben. Indem flache Bilder in 3D-Informationen überführt werden, macht die Arbeit die Roboter-Navigation deutlich unempfindlicher gegenüber Schatten, Blendung und anderen schwierigen Lichtwechseln, die bildbasierte Systeme normalerweise verwirren.
Warum es schwer ist, denselben Ort zweimal wiederzuerkennen
Für einen Roboter bedeutet „Orterkennung“, zu erkennen: „Ich war schon einmal hier“, damit er sich auf einer Karte lokalisieren und sicher navigieren kann. Traditionelle Systeme verlassen sich entweder auf normale Kameras oder auf laserbasierte Entfernungssensoren, sogenannte LiDARs. Kameras sind preiswert und erfassen reichhaltige Farbe und Textur, aber ihr Bild verändert sich drastisch zwischen bewölkten, sonnigen und nächtlichen Szenen. LiDAR ist deutlich stabiler, weil es Entfernungen direkt misst, ist aber sperrig und teuer. Manche Roboter kombinieren mehrere Sensoren, was Preis und Komplexität erhöht. Die Autorinnen und Autoren dieser Arbeit wählen einen anderen Weg: Sie halten die Hardware einfach und verwenden nur eine omnidirektionale Kamera, die rundum sieht, und verbessern die Software so, dass der Roboter über 3D-Struktur statt über reines Erscheinungsbild nachdenkt.
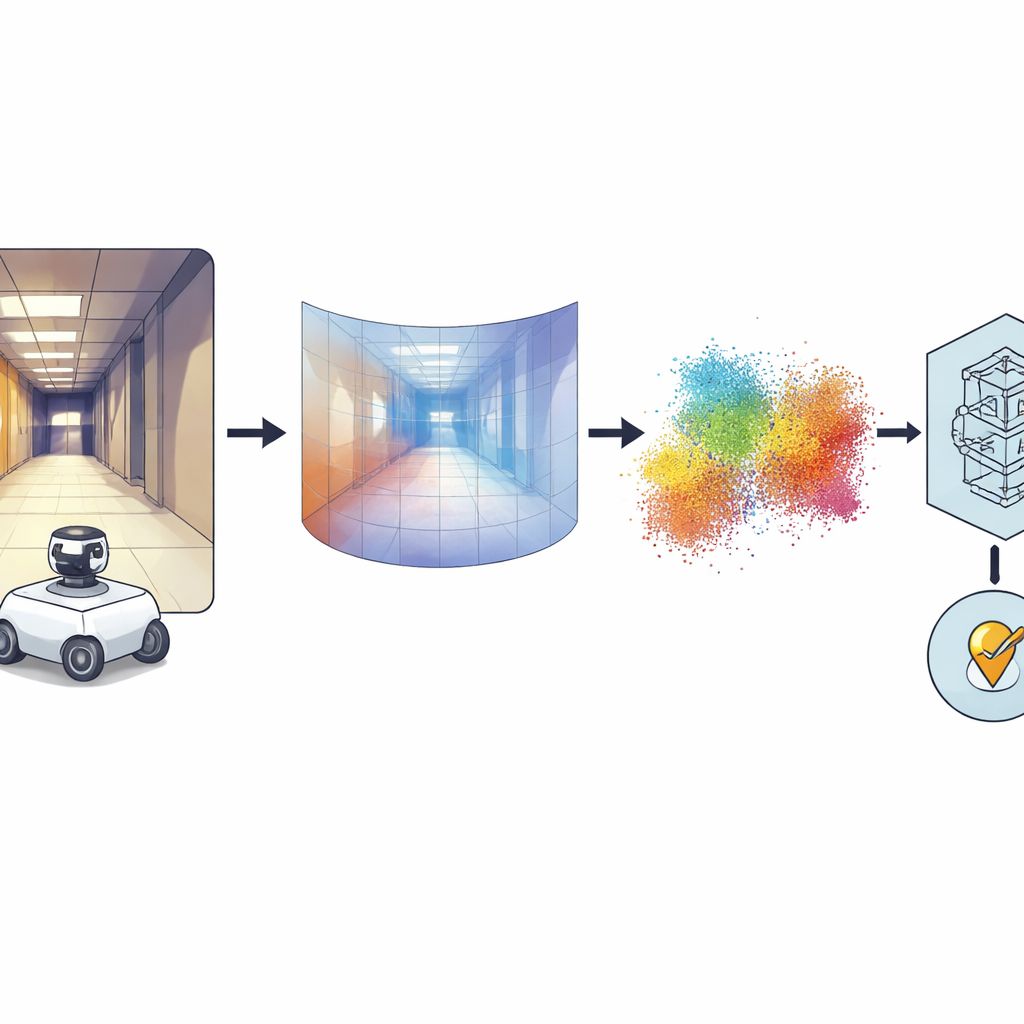
Von Rundum-Fotos zu 3D-Formen
Die zentrale Idee ist, jedes Panoramabild in eine dichte Tiefenkarte umzuwandeln, bei der jeder Pixel kodiert, wie weit dieser Teil der Szene von der Kamera entfernt ist. Dafür greifen die Autorinnen und Autoren auf ein leistungsfähiges „Foundation“-Modell namens Distill Any Depth zurück, das gelernt hat, Tiefe aus enormen Bildsammlungen zu schätzen. Die resultierende Tiefenkarte wird dann in eine Wolke von 3D-Punkten umgewandelt – eine Art virtueller LiDAR oder Pseudo-LiDAR – ganz ohne echten Laserscanner. Zusätzliche Verarbeitung beseitigt Artefakte, die durch den speziellen Spiegel der 360-Grad-Kamera entstehen, sodass fehlende oder verdeckte Bereiche aufgefüllt werden. Schließlich komprimiert ein neuronales Netzwerk namens MinkUNeXt, das direkt auf 3D-Punktwolken arbeitet, jede Wolke zu einem kompakten Fingerabdruck, der die Gesamtanordnung des Ortes erfasst.
Dem System beibringen, Lichttricks zu ignorieren
Tiefenschätzungen sind nicht perfekt, besonders wenn sich die Beleuchtung stark zwischen zwei Aufnahmen ändert. Um das System robust zu machen, führen die Forschenden einen neuen Trainingstrick ein, den sie Distilled Depth Variations nennen. Statt einem einzelnen Tiefenmodell blind zu vertrauen, mischen sie absichtlich Tiefenvorhersagen mehrerer kleinerer, weniger genauer Versionen des Tiefenschätzers bei. Dieses kontrollierte „Rauschen“ imitiert die Verzerrungen, die unter unterschiedlichen Beleuchtungsbedingungen auftreten, und zwingt das 3D-Netzwerk dazu, zu lernen, was an der Geometrie eines Ortes wirklich wichtig ist und was gefahrlos ignoriert werden kann. Außerdem reichern sie jeden 3D-Punkt mit Informationen zu Bildkanten und Texturstärke an – Merkmalen, die sich bei Lichtwechseln tendenziell stabiler verhalten als rohe Farbe.
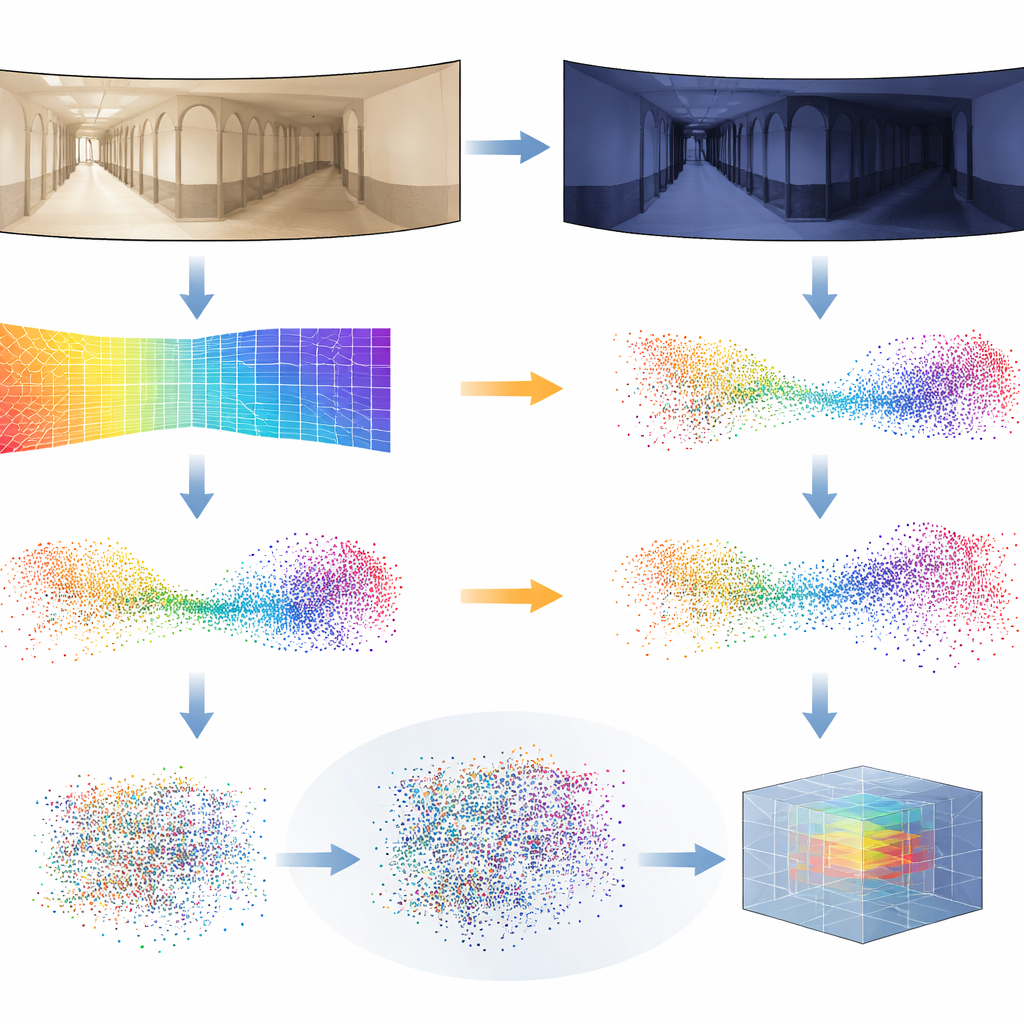
Der Nachweis der Alltagstauglichkeit
Um ihren Ansatz zu testen, nutzte das Team anspruchsvolle öffentliche Datensätze von Indoor-Robotikfahrten. In diesen Sammlungen durchstreift ein Roboter Gänge und Räume mehrfach bei bewölktem Tageslicht, strahlendem Sonnenschein und nachts, während Möbel und Menschen sich bewegen. Die Autorinnen und Autoren trainierten ihr System nur mit Bildern an einem Gebäude bei Bewölkung und evaluierten es dann über alle Gebäude und Beleuchtungsbedingungen hinweg, einschließlich Szenen, die es zuvor nie gesehen hatte. Ihre Pseudo-LiDAR-Methode erzielte durchweg gleichwertige oder bessere Ergebnisse als führende 2D-bildbasierte Techniken und andere 3D-Systeme, insbesondere in den härtesten Fällen wie nächtlichen Fahrten oder Übertragungen in völlig neue Umgebungen. Sie zeigten außerdem, dass dieselbe Pipeline auch mit gewöhnlichen frontalen Kameras funktioniert, nicht nur mit panoramischen, indem sie die geeignete Projektion von Tiefe zu 3D austauschten.
Was das für zukünftige Roboter bedeutet
Praktisch bedeutet diese Arbeit, dass ein Roboter eine LiDAR-ähnliche Wahrnehmung seiner Umgebung mit nur einer einzigen Kamera und cleverer Software erhalten kann. Indem der Fokus auf 3D-Struktur statt auf die unbeständigen Details von Licht und Farbe gelegt wird, kann das System Orte zuverlässig bei Tag, Nacht und Wetterwechseln erkennen und gleichzeitig die Hardware einfach und erschwinglich halten. Das könnte robuste Innenraumnavigation für Serviceroboter, Lagerfahrzeuge und Assistenzgeräte zugänglicher machen und den Weg für künftige Systeme ebnen, die Tiefe mit höherstufigem Szenenverständnis verbinden, um noch robustere Autonomie zu erreichen.
Zitation: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
Schlüsselwörter: Roboterlokalisierung, 3D-Vision, Orterkennung, Tiefenschätzung, omnidirektionale Kameras