Clear Sky Science · de
Kalibrierung tiefer Klassifikatoren mit dynamischer Vertrauensverbreitung und adaptiver Normalisierung
Warum es wichtig ist, KI‑Konfidenzen zu vertrauen
Moderne künstliche Intelligenzsysteme geben nicht nur an, was sie in einem Foto oder Sensormesswert zu sehen glauben, sondern auch wie sicher sie sich sind. Diese selbstberichtete Zuversicht ist in sicherheitskritischen Bereichen wie medizinischer Bildgebung, autonomem Fahren oder Industrieüberwachung entscheidend, denn ein fehlgeleitetes Gefühl von Sicherheit kann gefährlich sein. Gleichzeitig sind heutige tiefe neuronale Netze dafür berüchtigt, bei Fehlern übermäßig selbstsicher zu sein, und vorhandene Korrekturen versagen oft, wenn Daten unausgewogen sind oder sich die Umgebungsbedingungen verschieben. Dieses Papier stellt eine neue Methode vor, genannt Dynamic Confidence Propagation with Alternating Normalization (DCP‑AN), die darauf abzielt, die Vertrauenswerte von KI‑Systemen unter realistischen, sich ändernden Bedingungen ehrlicher, stabiler und effizienter zu machen.
Wenn intelligente Maschinen sich zu sicher sind
Die meisten verbreiteten Deep‑Learning‑Modelle werden darauf trainiert, das korrekte Label vorherzusagen, nicht darauf, wie vertrauenswürdig jede Vorhersage ist. Daher kann ein Netzwerk zu 99 % "sicher" sein, dass ein Bild eine Katze zeigt, obwohl es tatsächlich ein Hund ist. Standardkalibrierverfahren wie Temperature Scaling oder das Einteilen von Vorhersagen in Konfidenz‑Bins versuchen, dieses Problem nach dem Training durch globale Anpassungen zu beheben. Diese Methoden behandeln jedoch alle Kategorien und alle Beispiele gleich. In der realen Welt sind Daten selten ausgeglichen: Einige häufige „Head“‑Klassen haben viele Beispiele, während seltene „Tail“‑Klassen nur sehr wenige Instanzen aufweisen. Netzwerke neigen dazu, bei häufigen Klassen überkonfident und bei seltenen unterkonfident zu sein — eine Diskrepanz, die statische, einheitliche Korrekturen nicht schließen können, insbesondere wenn sich die Datenverteilung zwischen Domänen verschiebt, etwa von künstlerischen Skizzen zu realen Fotos.
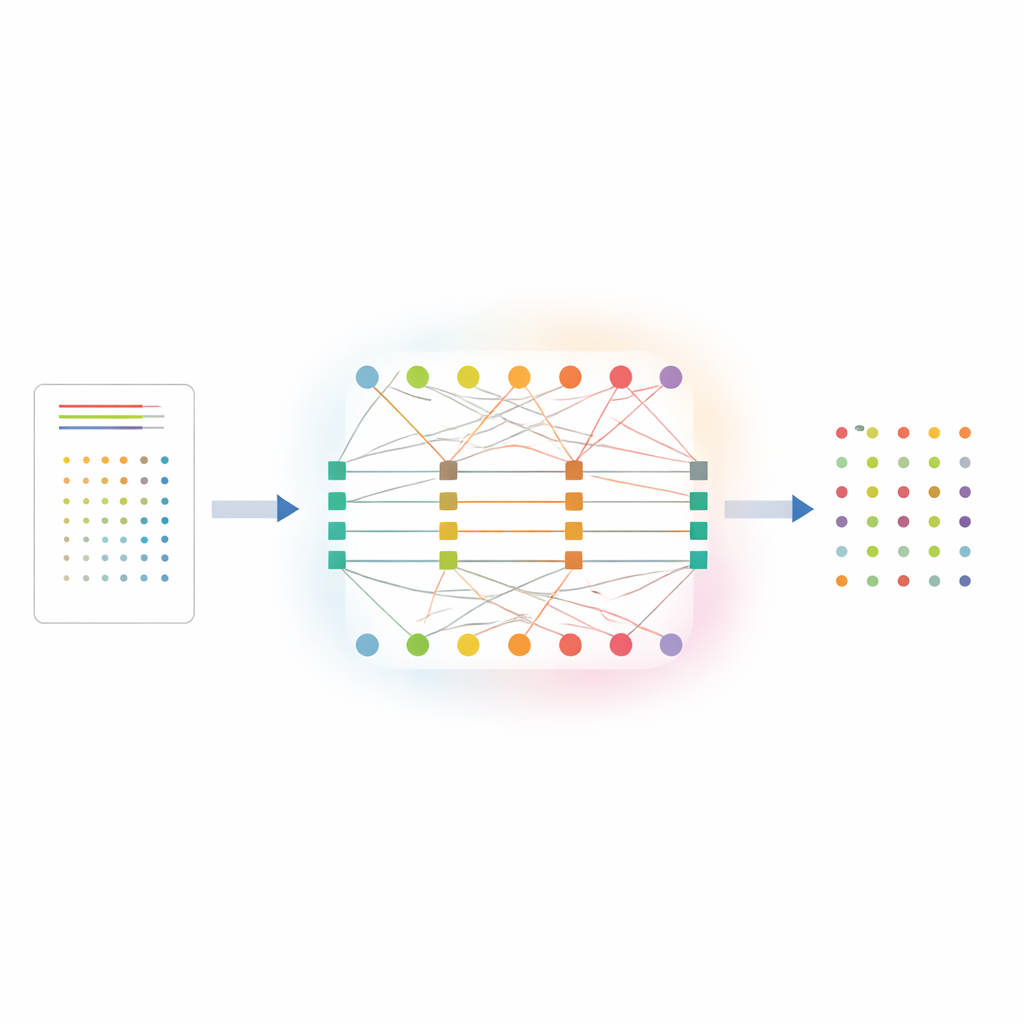
Eine neue Art, Informationen zwischen Daten und Labels zu teilen
DCP‑AN geht dieses Problem an, indem es explizit modelliert, wie Vertrauen zwischen einzelnen Proben und den Klassen, denen sie angehören, fließen sollte. Die Methode stellt die Beziehung zwischen Proben und Klassen als zweischichtiges Netzwerk dar: eine Schicht mit Knoten für Proben, eine weitere für Klassen, verbunden durch gewichtete Verbindungen, die die anfänglichen Vorhersagestärken kodieren. Das Vertrauen wird dann in einem zweistufigen Ablauf verfeinert. Im ersten Schritt fließt Information von den Proben zu den Klassen und passt an, wie stark die Vorhersagen jeder Klasse verstreut sind, gesteuert durch die derzeit wahrgenommene Unsicherheit dieser Klasse. Im zweiten Schritt fließt Information von den Klassen zurück zu den Proben und justiert das Vertrauensprofil jeder Probe anhand der Konsistenz mit früheren Schätzungen. Durch das begrenzte Wiederholen dieses Hin‑ und Herprozesses fördert das System eine bessere "Teamarbeit" zwischen Beispielen und Labels, sodass seltene Klassen klarere Signale erhalten, statt von häufigen überschattet zu werden.
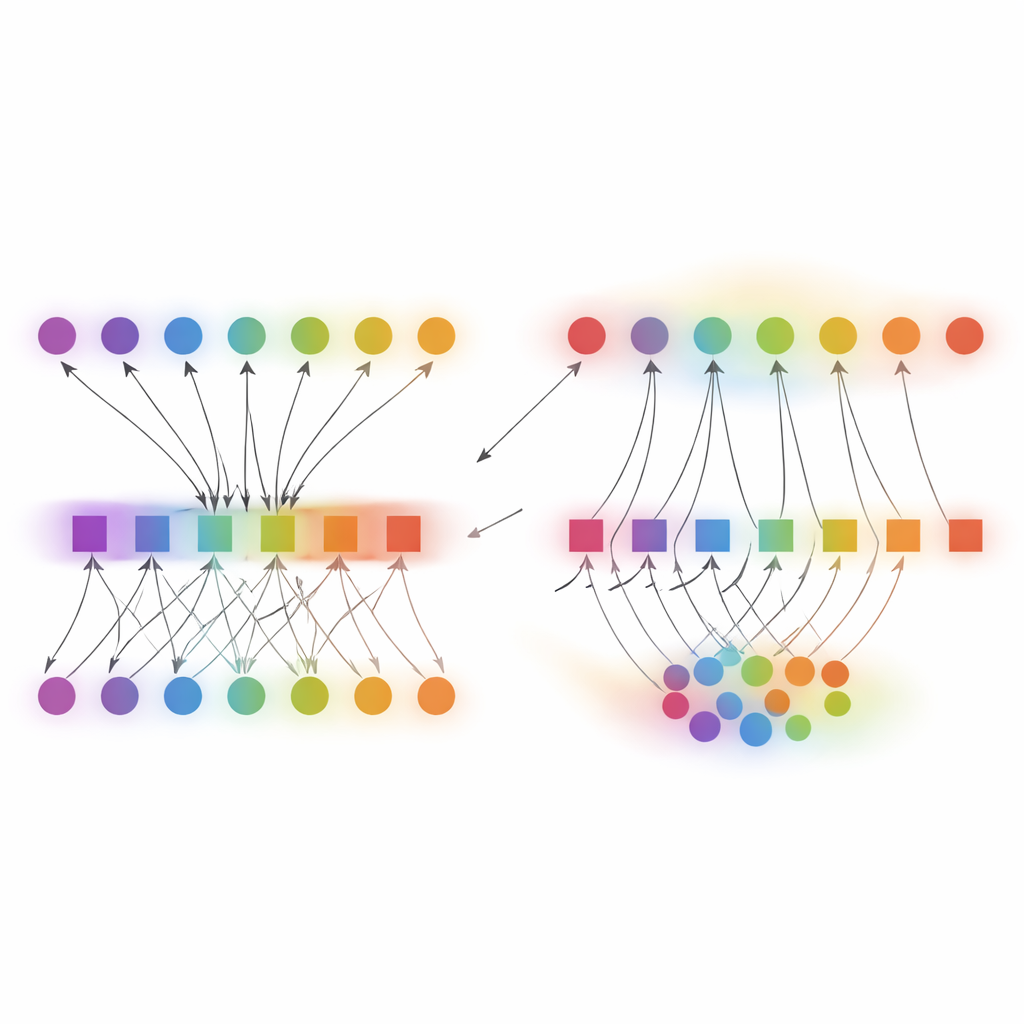
Die Temperatur dort erhöhen, wo sie gebraucht wird
Eine Schlüsselinnovation von DCP‑AN ist ein adaptives "Temperaturfeld", das steuert, wie stark die Methode das Vertrauen umformt, abhängig davon, wie unsicher die Situation lokal und global erscheint. Anstatt einen einzigen Temperaturwert für alle Vorhersagen zu verwenden, berechnet die Methode separate Anpassungsstärken für Klassen und für Proben, basierend auf Unsicherheits‑ und Diskrepanzmaßen über die Zeit. Für Head‑Klassen, die das Netzwerk bereits zuversichtlich behandelt, kühlt die effektive Temperatur sanft ab, um Überglättung zu vermeiden und scharfe Unterscheidungen zu erhalten. Bei Tail‑Klassen und mehrdeutigen Proben steigt die Temperatur, was stärkere Korrekturen erlaubt, die gerechtfertigte Zuversicht erhöhen und zufällige Ausreißer dämpfen. Dieses dynamische Verhalten ergibt sich aus einer prinzipiellen Aktualisierungsregel und reagiert schnell, wenn die Unsicherheit wächst, bleibt aber stabil, wenn das Modell bereits gut angepasst ist.
Zuverlässige Verbesserung über Aufgaben und Hardware hinweg
Die Autoren bewerten DCP‑AN sorgfältig auf mehreren weit verbreiteten Bilddatensätzen. Auf einer long‑tailed Variante von ImageNet, bei der manche Kategorien hunderte Male mehr Bilder haben als andere, steigert die Methode die Genauigkeit bei seltenen Tail‑Klassen um etwa 10 absolute Prozentpunkte und reduziert einen gängigen Kalibrierfehler mehr als zur Hälfte im Vergleich zu einer ungeprüften Basislinie. In einem Domänenübertragungs‑Test, bei dem ein auf Kunstwerken trainiertes Modell auf reale Fotos übertragen wird, erhöht DCP‑AN sowohl die Genauigkeit in der neuen Domäne als auch ein statistisches Maß für die Lücke zwischen Quell‑ und Zielverteilung. Wichtig ist, dass diese Verbesserungen nicht mit hohem Rechenaufwand erkauft werden: Auf einer modernen Grafikkarte fügt die Methode etwas mehr als eine Millisekunde Verzögerung und weniger als ein halbes Megabyte zusätzlichen Speicher hinzu, sodass sie praktisch für Echtzeit‑ und Edge‑Geräte bleibt.
Was das für den Alltag der KI bedeutet
Einfach gesagt zeigt diese Arbeit, dass wir KI‑Systeme nicht nur intelligenter, sondern auch selbstbewusster darüber machen können, wann sie falsch liegen könnten. Indem Vertrauensinformationen zwischen Beispielen und Kategorien hin und her fließen dürfen und indem die Aggressivität der Selbstkorrektur an die sich ändernde Unsicherheit angepasst wird, liefert DCP‑AN Wahrscheinlichkeitsabschätzungen, die besser mit der Realität übereinstimmen — selbst bei seltenen Ereignissen und in wechselnden Umgebungen. Da die Methode eine mathematische Garantie dafür liefert, dass ihre iterativen Aktualisierungen schnell konvergieren, und weil sie mit minimalem Overhead läuft, kann dieses Framework in bestehende neuronale Netze in Bereichen wie Gesundheitswesen, Robotik und Sicherheitsüberwachung integriert werden. Das Ergebnis ist eine KI, die weiterhin Fehler macht, aber viel ehrlicher darüber ist, wie sicher sie sich ist — ein entscheidender Schritt hin zu Systemen, denen Menschen vertraulich vertrauen können.
Zitation: He, P., Fu, W., Wang, L. et al. Calibrating deep classifiers with dynamic confidence propagation and adaptive normalization. Sci Rep 16, 10959 (2026). https://doi.org/10.1038/s41598-026-39842-4
Schlüsselwörter: Vertrauenskalibrierung, tiefe neuronale Netze, long‑tailed Recognition, Unsicherheitsabschätzung, Domänenanpassung