Clear Sky Science · de
Mathematische Modellierung und Berechnung von NM‑Polynomindizes zur Vorhersage physikochemischer Eigenschaften
Warum das für zukünftige Arzneimittel wichtig ist
Die Entwicklung eines neuen Medikaments ist ein wenig wie der Entwurf eines Flugzeugs: Man möchte wissen, wie es sich verhält, lange bevor man es tatsächlich baut. Bei Arzneistoffen gehört dazu, wie leicht sie verdampfen, wie sie sich mit Wasser oder Fetten mischen und wie sie sich im Körper verteilen. Dieser Artikel zeigt, wie sorgfältig gestaltete Mathematik viele dieser physikalischen und chemischen Eigenschaften allein aus der Struktur eines Wirkstoffs vorhersagen kann — und damit Zeit, Kosten und Versuch‑und‑Irrtum in der Arzneimittelforschung einsparen könnte. 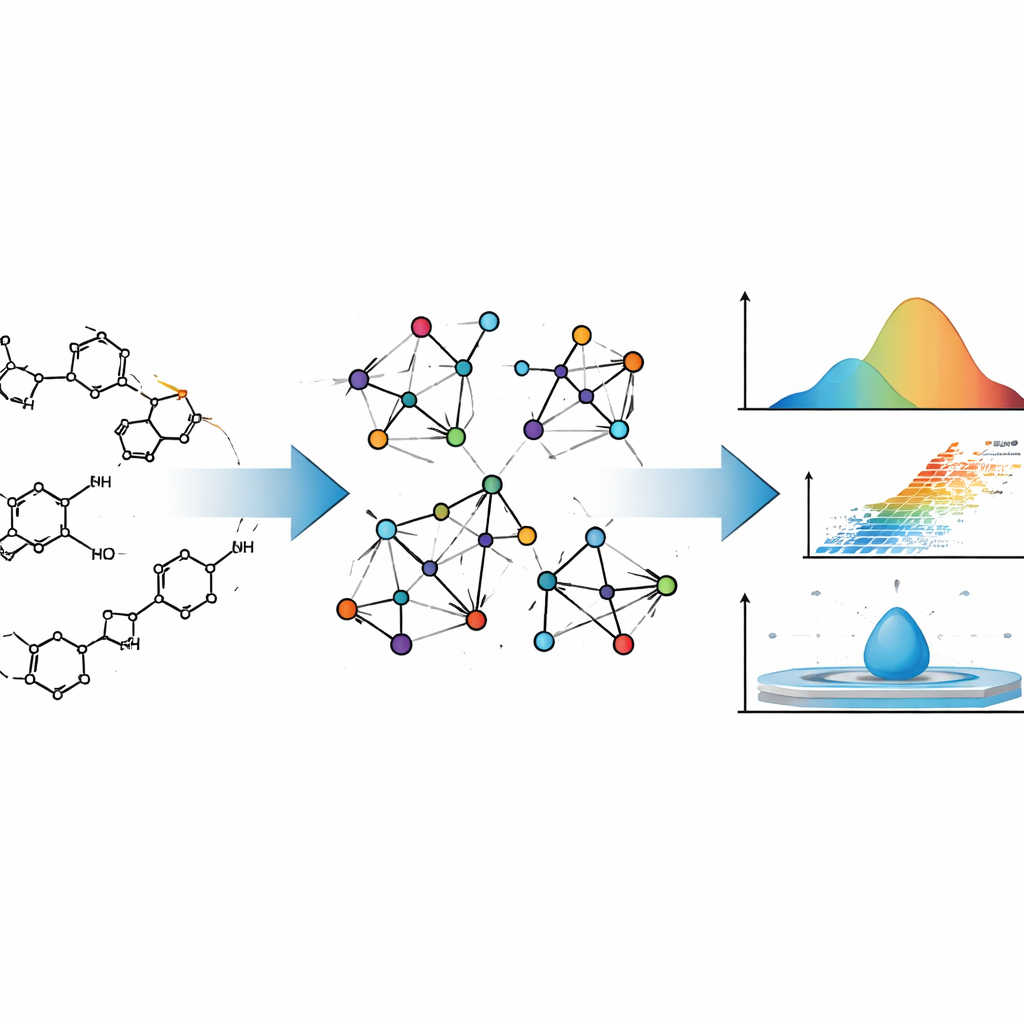
Von Molekülen zu Netzwerken
Die Autor:innen betrachten Wirkstoffmoleküle nicht nur als Ansammlungen von Atomen, sondern als Netzwerke. In diesem Bild ist jedes Atom ein Punkt und jede chemische Bindung eine Linie, die zwei Punkte verbindet. Diese Beschreibung stammt aus der Graphentheorie, einem Teilgebiet der Mathematik, das Netzwerke aller Art untersucht — von sozialen Netzwerken bis zu Stromnetzen. Chemiker nutzen solche „molekularen Graphen“ seit Jahrzehnten, weil bestimmte numerische Zusammenfassungen dieser Graphen — sogenannte topologische Indizes — oft mit realen molekularen Eigenschaften korrelieren, etwa mit dem Siedepunkt oder der Dichte.
Mehr Nachbarschaftsdetails in die Darstellung
Traditionelle Indizes betrachten meist nur, wie viele Bindungen an jedes Atom angrenzen. Das Team hinter dieser Studie geht einen Schritt weiter. Sie verwenden sogenannte Neighborhood‑M‑Polynom (NM‑Polynom) Indizes, die nicht nur die Verbindungen eines Atoms zählen, sondern auch zusammenfassen, wie stark seine Nachbarn vernetzt sind. Diese reichere Beschreibung erfasst Feinheiten wie den Verzweigungsgrad eines Moleküls, wie Ringe miteinander verschmolzen sind und wo Sauerstoff‑ oder Stickstoffatome im Gerüst liegen. Diese Merkmale beeinflussen wiederum, wie stark Moleküle aneinander haften, wie starr sie sind und wie ihre Elektronen auf elektrische Felder reagieren — alles Faktoren, die zentrale physikochemische Eigenschaften bestimmen.
Die Idee an echten Krebsmedikamenten testen
Um ihre Mathematik in der Praxis zu verankern, berechnen die Autor:innen zunächst NM‑Polynomindizes für zwei bekannte Zytostatika, Mitoxantron und Doxorubicin. Beide sind komplexe, mehrringige Moleküle, die in der Chemotherapie breit eingesetzt werden. Indem sie die detaillierten chemischen Zeichnungen in molekulare Graphen und anschließend in NM‑Polynomindizes übersetzen, zeigen die Forschenden, wie die Methode strukturelle Änderungen über verschiedene „Größen“ dieser Moleküle systematisch erfasst. Sie automatisieren den Prozess mit einem Python‑Programm, das die Konnektivität eines Moleküls (in Form einer Adjazenzmatrix) übernimmt und sofort die vollständige Menge an Indizes ausgibt — wodurch Fehler durch Handarbeit minimiert und zeitaufwändige Berechnungen beschleunigt werden. 
Maschinen das Lesen molekularer Fingerabdrücke beibringen
Im nächsten Schritt erweitern die Forschenden den Datensatz über diese beiden Wirkstoffe hinaus auf eine Kollektion von 45 polycyclischen Arzneimitteln, darunter bekannte Substanzen wie Paracetamol, Ibuprofen und mehrere moderne zielgerichtete Therapien. Für jedes Medikament erstellen sie neun NM‑Polynomindizes und neun experimentell gemessene Eigenschaften: Komplexität, Siedepunkt, Verdampfungsenthalpie, Flammpunkt, molare Brechzahl, Polarisierbarkeit, Oberflächenspannung, Molvolumen und Brechungsindex. Anschließend trainieren sie mehrere regressionsartige Machine‑Learning‑Modelle — Linear, Ridge, Lasso und Elastic Net — um zu lernen, wie Kombinationen der Indizes auf jede Eigenschaft abgebildet werden. Sorgfältige statistische Vorkehrungen werden durchgängig getroffen: redundante Eingaben werden entfernt, Variablen standardisiert, wiederholte Kreuzvalidierung auf 80 % der Daten durchgeführt und die finalen Modelle an 20 % unberührter Testdaten geprüft.
Was die Zahlen verraten
Die Modelle zeigen, dass NM‑Polynomindizes besonders aussagekräftig für Eigenschaften sind, die mit Packungsdichte und Wechselwirkungen zwischen Molekülen zusammenhängen. Für Siedepunkt, Verdampfungsenthalpie, Flammpunkt, molare Brechzahl, Polarisierbarkeit und Molvolumen erreichen die besten Modelle sehr hohe Korrelationswerte, was bedeutet, dass die vorhergesagten Werte eng mit den experimentellen übereinstimmen. Regularisierte Verfahren wie Ridge und Elastic Net schneiden im Allgemeinen am besten ab, was darauf hindeutet, dass eine moderate Einschränkung der Modelle hilft, sich auf die informationsreichsten Aspekte der Indizes zu konzentrieren. Eine Korrelations‑Heatmap bestätigt, dass mehrere Indizes — insbesondere solche, die mit genereller Konnektivität und „Nachbarschaftsreichtum“ zu tun haben — über das 45‑Medikamenten‑Panel hinweg stark und konsistent mit diesen Eigenschaften korrelieren.
Grenzen und Verbesserungsmöglichkeiten
Nicht jede Eigenschaft lässt sich gleich gut vorhersagen. Der Brechungsindex, der beschreibt, wie Licht beim Eintritt in ein Material gebrochen wird, erweist sich als hartnäckig: Die Modelle tun sich schwer, besser als einfache Mittelwerte zu sein, und die NM‑Polynomindizes zeigen nur schwache Korrelationen damit. Die Oberflächenspannung wird mäßig gut erfasst, aber nicht so stark wie die anderen Merkmale. Diese Lücken deuten darauf hin, dass einige Verhaltensweisen von Merkmalen abhängen, die über die zweidimensionale Konnektivität hinausgehen, etwa die dreidimensionale Gestalt oder subtile elektronische Effekte. Die Autor:innen schlagen vor, NM‑Polynomindizes in Zukunft mit quantenchemischen oder 3D‑Deskriptoren zu kombinieren, um diese Lücke zu schließen.
Was das für die Wirkstoffentwicklung bedeutet
Vereinfacht gesagt zeigt die Studie, dass ausgefeilte, aber klar strukturierte Mathematik eine statische Skizze eines Moleküls in einen überraschend genauen Vorhersager für dessen Laborverhalten verwandeln kann. Für viele wichtige Eigenschaften — wie schwer es zu verdampfen ist, wie massereich es ist oder wie leicht sich seine Elektronen verschieben — liegt der NM‑Polynom‑Ansatz in Kombination mit modernen Regressionsverfahren auf Augenhöhe mit oder übertrifft ältere Methoden, die einfachere Indizes oder kleinere Datensätze verwendeten. Zwar ersetzt er Experimente noch nicht vollständig, aber er bietet Wirkstoffentwicklern ein schnelleres Screening‑Werkzeug: Durch die Berechnung dieser graphbasierten Fingerabdrücke können sie frühe Schätzungen wichtiger physikochemischer Eigenschaften erhalten, Laborarbeit auf die vielversprechendsten Kandidaten konzentrieren und den chemischen Raum effizienter erkunden.
Zitation: Tawhari, Q.M., Naeem, M., Koam, A.N.A. et al. Mathematical Modeling and Computation of NM-Polynomial Indices for Physicochemical Properties Prediction. Sci Rep 16, 8136 (2026). https://doi.org/10.1038/s41598-026-39562-9
Schlüsselwörter: chemische Graphentheorie, Vorhersage von Wirkstoff‑Eigenschaften, molekulare Topologie, Machine Learning in der Chemie, physikochemische Deskriptoren