Clear Sky Science · de
Ein adaptives Datenwiederbalancierungs‑Framework zur Echtzeit‑Vorhersage von Verkehrsrisiken
Warum das Ausbalancieren von Verkehrsdaten für die Sicherheit wichtig ist
Unfälle auf Autobahnen sind im Vergleich zur überwältigenden Menge an gewöhnlichem, ereignislosem Fahren selten. Das ist zwar gut für die Sicherheit, aber es schafft ein verstecktes Problem für Computer, die in Echtzeit vorhersagen wollen, wann und wo Unfälle eintreten könnten. Wenn die Daten von sicheren Situationen dominiert werden, können Algorithmen sehr gut darin werden, „nichts wird passieren“ vorherzusagen und auf dem Papier trotzdem genau aussehen – während sie in Wirklichkeit die wirklich gefährlichen Momente übersehen. Diese Studie nimmt sich dieses Ungleichgewichts direkt an und schlägt eine adaptive Methode zur „Wiederbalancierung“ von Verkehrsdaten vor, damit Warnsysteme seltene, aber wichtige Risikosituationen besser erkennen können, ohne für den Echtbetrieb zu langsam zu werden.
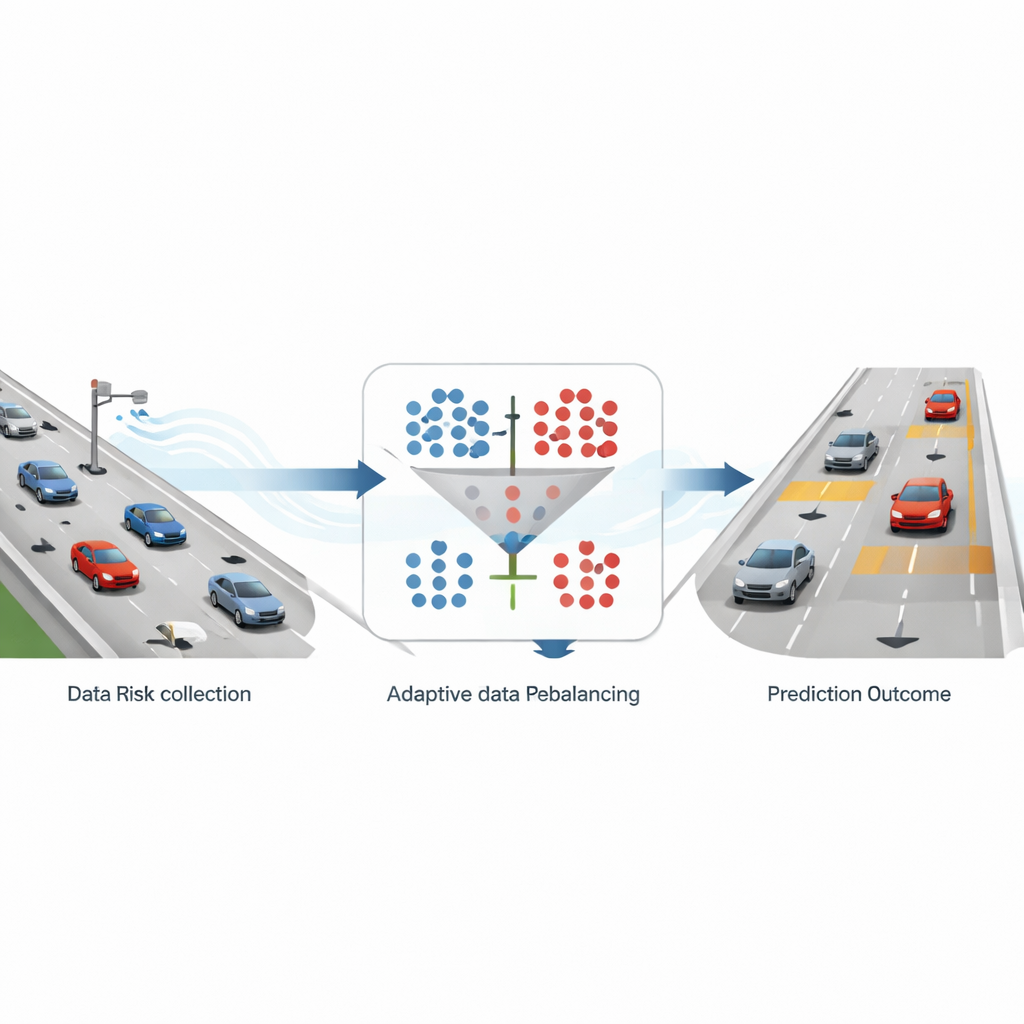
Wie realer Verkehr in Warnsignale verwandelt wird
Die Forschenden bauen ihr Framework auf detaillierten Autobahn‑Trajektoriendaten aus einem großen drohnenbasierten Datensatz auf, der über deutsche Autobahnen erfasst wurde. Die Position und Geschwindigkeit jedes Fahrzeugs werden viele Male pro Sekunde entlang sechsspuriger Autobahnabschnitte verfolgt. Aus diesem umfangreichen Bewegungsprotokoll berechnet das Team einen weit verbreiteten Sicherheitsindikator namens Time‑to‑Collision, der schätzt, wie lange es dauern würde, bis ein folgendes Fahrzeug das vorausfahrende trifft, falls beide ihren Kurs und ihre Geschwindigkeit beibehalten. Fällt diese Zeit unter drei Sekunden, wird die Situation als „hohes Risiko“ markiert; andernfalls gilt sie als „kein Risiko“. Nach Aggregation dieser Messwerte in 10‑Sekunden‑Schnitten und der Beschränkung auf sechsspurige Straßen ergibt sich etwa ein sicheres Sample auf neun riskante, ein stark verzerrter Datensatz, der reale Autobahnbedingungen widerspiegelt.
Das Ungleichgewicht beheben, ohne das Wesentliche zu verlieren
Um dieses Ungleichgewicht anzugehen, vergleicht die Studie zwei gängige Strategien. Die eine, Oversampling genannt, fügt mehr Beispiele seltener riskanter Situationen hinzu, indem synthetische Proben erzeugt werden, die den realen Hochrisikofällen ähneln. Die andere, Undersampling, reduziert die vielen sicheren Fälle, indem einige zufällig verworfen werden. Die Autoren verwenden eine verbreitete Oversampling‑Methode (SMOTE) und ein einfaches zufälliges Undersampling und wenden sie in mehreren festen Verhältnissen von sicheren zu riskanten Proben an – 1:1, 2:1, 3:1 und 4:1. Anschließend speisen sie sowohl die ursprünglichen als auch die veränderten Datensätze in vier Vorhersagemodelle: zwei traditionelle Ansätze des maschinellen Lernens und zwei Deep‑Learning‑Modelle, die auf Zeitreihen spezialisiert sind. Durch das Testen all dieser Kombinationen können sie sehen, wie verschiedene Arten der Datenbalance die Fähigkeit des Systems verändern, Risiken zu erkennen und gleichzeitig sichere Zustände korrekt einzuschätzen.
Ein Algorithmus sucht die optimale Balance
Anstatt davon auszugehen, dass exakt gleiche Anzahlen sicherer und riskanter Proben am besten sind, lassen die Forschenden einen genetischen Algorithmus – eine suchmethodische Vorgehensweise, die von der Evolution inspiriert ist – nach dem effektivsten Verhältnis suchen. Dieser Optimierer passt das Verhältnis von sicher zu riskant in einem realistischen Bereich von 1:1 bis 4:1 an, generiert wiederholt Kandidatenverhältnisse, bewertet sie und verfeinert sie über hunderte Iterationen. Entscheidend ist, dass er sich nicht nur an der Vorhersagegenauigkeit orientiert: Er berücksichtigt auch, wie lange das Modell zum Trainieren und zur Vorhersage braucht, um den Echtzeitanforderungen von Verkehrsleitstellen Rechnung zu tragen. Damit Genauigkeit und Rechenzeit fair kombiniert werden können, werden alle Messgrößen normalisiert, bevor sie zu einer einzigen „Fitness“-Kennzahl zusammengeführt werden, die der Algorithmus zu minimieren versucht.
Was die Modelle über Risiko auf der Straße lernen
Über die vielen Experimente hinweg fällt ein Muster auf. Das Ausbalancieren der Daten verbessert die Risikoerkennung gegenüber dem originalen Ungleichgewicht, und Oversampling mit synthetischen riskanten Fällen schneidet tendenziell besser ab als das Wegwerfen sicherer Fälle. Ein Verhältnis von 2:1 (sicher zu riskant) liefert unter den festen Einstellungen die beste Leistung und übertrifft die weit verbreitete 1:1‑Wahl. Wenn der genetische Algorithmus dieses Verhältnis feinabstimmen darf, landet er auf leicht ungeraden, aber optimalen Werten – etwa 2,3:1 beim Oversampling und 2,7:1 beim Undersampling. Unter den Vorhersagemodellen erzielt ein bestimmter Typ rekurrenter neuronaler Netze, bekannt als Gated Recurrent Unit, durchgehend die stärksten Ergebnisse, insbesondere in Kombination mit Oversampling und Optimierung. Die Modelle zeigen außerdem, dass mittlere Fahrzeuggeschwindigkeiten flussaufwärts und flussabwärts eines Punktes auf der Autobahn aussagekräftiger für Risiko sind als einfache Fahrzeugzählungen.
Stabilitätsprüfung und Vorbereitung für den Einsatz
Weil Optimierungsverfahren manchmal in irreführenden Lösungen stecken bleiben können, untersuchen die Autorinnen und Autoren, wie sich ihre Suche über die Zeit verhält. Sie zeigen, dass die Fitness‑Scores stetig sinken und sich schließlich abflachen, was darauf hindeutet, dass der Algorithmus zu stabilen, hochwertigen Verhältnissen konvergiert, statt zu springen. Anschließend variierten sie die gewählten Verhältnisse um ein paar Prozent nach oben und unten, um zu prüfen, ob die Leistung zusammenbricht. In der Praxis sinkt die Genauigkeit bei kleinen Änderungen nur leicht, was darauf hindeutet, dass das System robust ist und nicht übermäßig auf eine einzige fragile Einstellung abgestimmt ist. Wenn jedoch der Anteil der für Tests reservierten Daten sehr groß wird, reagieren die Modelle empfindlicher, was die Notwendigkeit ausreichend reichhaltiger Trainingsdaten unterstreicht.
Was das für sicherere, intelligentere Autobahnen bedeutet
Alltagsgemäß zeigt die Studie, dass das Komputerlernen von Gefahr auf der Straße nicht allein eine Frage cleverer Modelle ist; es geht ebenso darum, diesen Modellen ein ausgewogenes Bild seltener, aber kritischer Ereignisse zuzuführen. Durch die sorgfältige Anpassung der Anzahl sicherer und riskanter Beispiele im Training – und indem ein adaptiver Algorithmus den besten Kompromiss zwischen Genauigkeit und Geschwindigkeit finden darf – macht das vorgeschlagene Framework die Echtzeit‑Risikovorhersage auf Autobahnen zuverlässiger und praktischer. Verkehrsbehörden könnten diesen Ansatz in Systeme integrieren, die Verkehrssensordaten überwachen und frühzeitig vor wahrscheinlichen Auffahrunfällen warnen, um Fahrerhinweise, Streifeneinsätze oder automatische Bremsstrategien zu steuern. Obwohl die Arbeit an deutschen Autobahnen unter guten Wetterbedingungen demonstriert wurde, bietet die zugrundeliegende Idee der adaptiven Datenbalance ein allgemeines Rezept zur Verbesserung von Sicherheitsvorhersagen überall dort, wo gefährliche Ereignisse selten, aber zu wichtig sind, um übersehen zu werden.
Zitation: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
Schlüsselwörter: Verkehrssicherheit, Unfallrisiko‑Vorhersage, unausgeglichene Daten, maschinelles Lernen, Autobahntrajektorien