Clear Sky Science · de
Ein daten-effizientes 3D-Medizin-Vision‑Language‑Modell mit nur einem 2D‑Encoder
Intelligentere Hilfe aus 3D‑Scans
Wenn Ärztinnen und Ärzte CT‑ oder MRT‑Scans lesen, betrachten sie nicht nur einzelne Bilder – sie setzen mental Hunderte von Schichten zu einem dreidimensionalen Gesamtbild zusammen. Computern das gleiche beizubringen könnte schnellere, konsistentere Diagnosen und klarere Befunde für Patientinnen und Patienten ermöglichen. Aktuelle künstliche Intelligenzsysteme, die 3D‑Scans verarbeiten, sind jedoch extrem „datenhungrig“ und benötigen riesige, sorgfältig annotierte Datensätze, die vielen Kliniken gar nicht zur Verfügung stehen. Dieser Beitrag stellt einen Weg vor, wie sich 3D‑Verständnis mit vorhandener 2D‑Bildtechnik erreichen lässt und damit leistungsfähige Werkzeuge einfacher und kostengünstiger zu entwickeln und einzusetzen sind.
Warum 3D‑Scans für KI schwierig sind
Moderne Vision‑Language‑Systeme können bereits ein 2D‑medizinisches Bild ansehen und Fragen beantworten oder einen Befund in verständlicher Sprache formulieren. Diese Fähigkeit auf 3D‑Volumen auszudehnen würde es der KI erlauben, über ganze Organe und subtile Läsionen zu urteilen, die erst bei Betrachtung vieler Schichten klar werden. Das Problem ist, dass die meisten aktuellen 3D‑Systeme auf speziellen 3D‑Encoder‑Architekturen basieren, die von Grund auf mit großen Sammlungen gelabelter Scans trainiert werden. Solche Datensätze sind selten, teuer zu annotieren und häufig an gut ausgestattete Zentren gebunden, was den Nutzen einschränkt. Gleichzeitig führt die einfache Behandlung jeder Schicht als separates 2D‑Bild dazu, dass die natürliche Kontinuität zwischen den Schichten verloren geht und das Modell mit sich wiederholender Information überflutet wird.
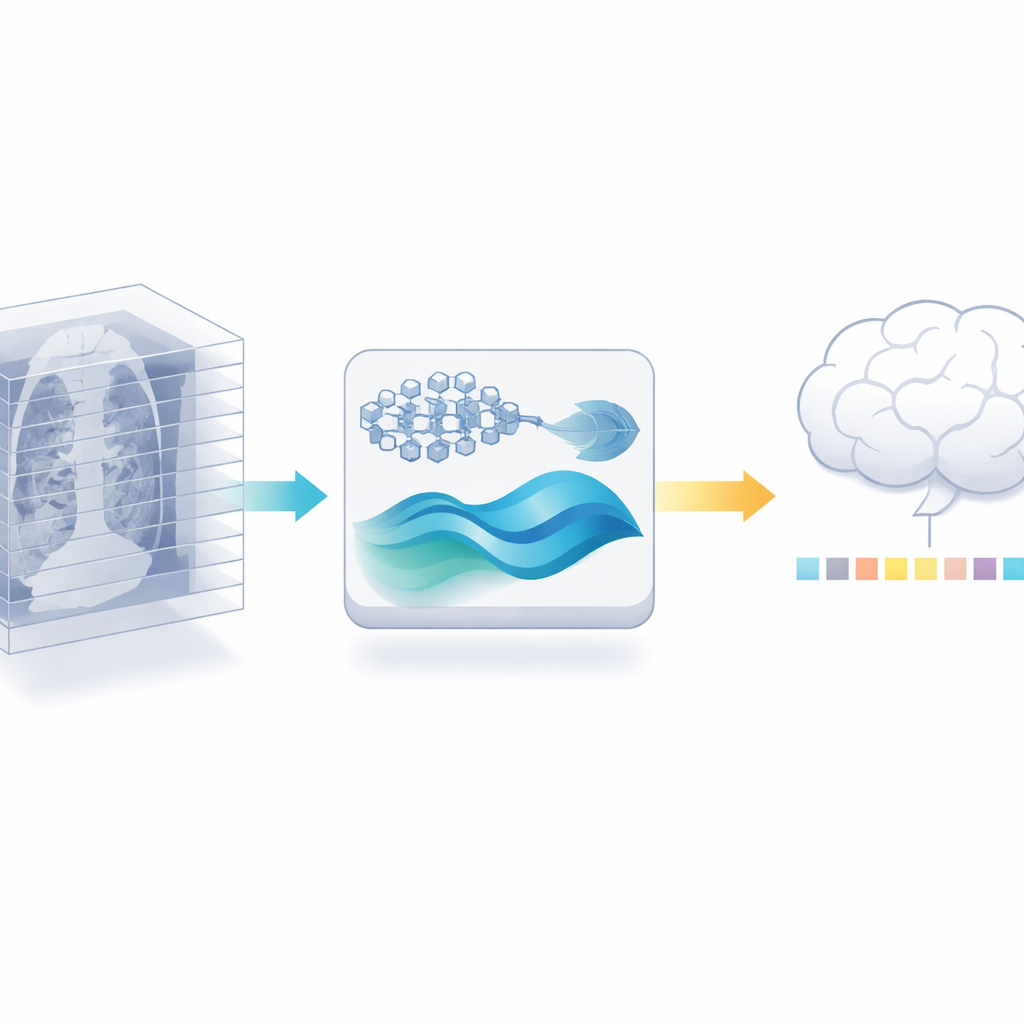
Einen 2D‑Experten für 3D‑Aufgaben wiederverwenden
Die Autorinnen und Autoren schlagen einen anderen Weg vor: Statt einen neuen 3D‑Encoder zu trainieren, nutzen sie ein leistungsfähiges 2D‑Medizinbildmodell, das bereits an Millionen gelabelter Bilder aus der medizinischen Literatur trainiert wurde. Sie zerlegen jeden 3D‑Scan in seine einzelnen Schichten und lassen das 2D‑Modell aus jeder Schicht detaillierte Merkmale extrahieren. Anschließend beseitigen sie gezielt Redundanz: Da benachbarte Schichten eines Scans oft sehr ähnlich sind, kann ein Ähnlichkeitscheck viele nahezu identische Ansichten verwerfen und gleichzeitig die informativsten Bilder behalten. Dieser Schritt reduziert allein die Datenmenge, die spätere Stufen verarbeiten müssen, ohne weitere gelabelte Scans zu verlangen.
Die 3D‑Geschichte aus Fragmenten neu zusammensetzen
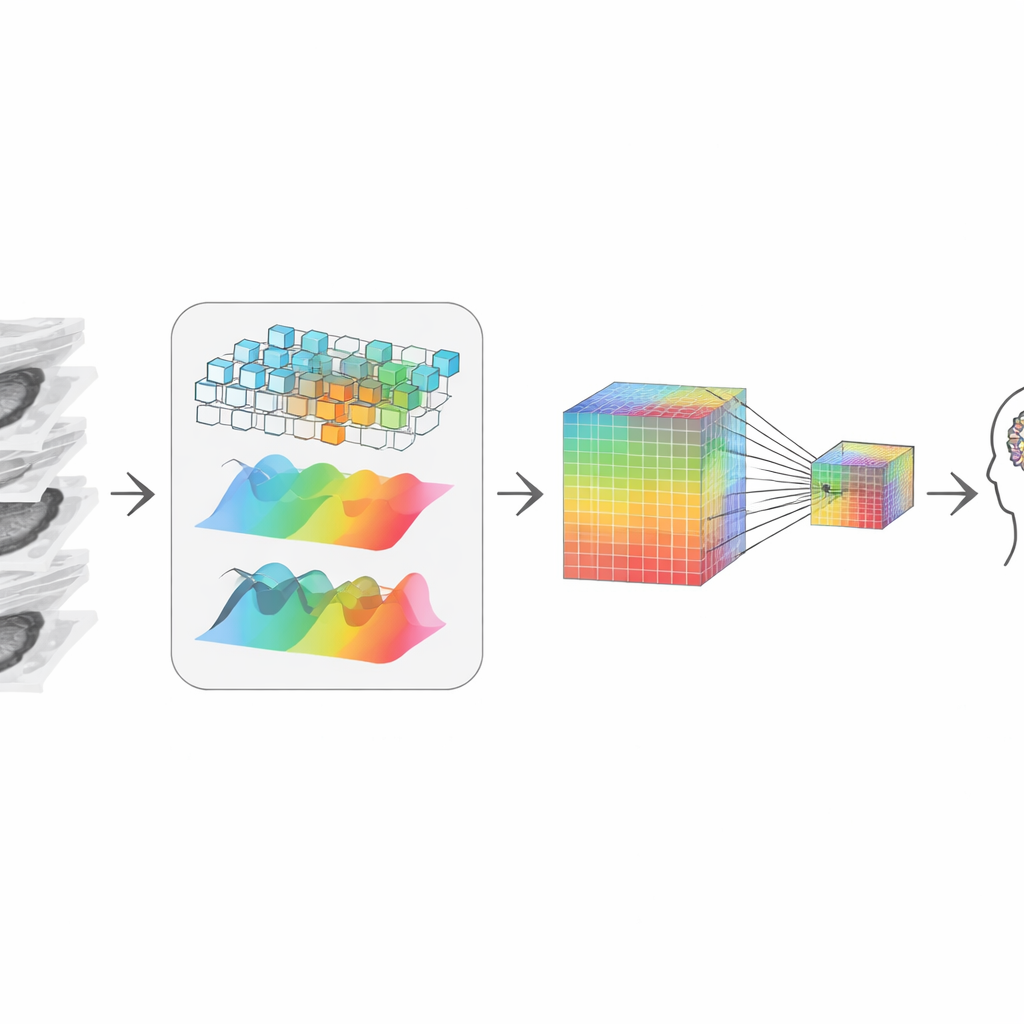
Nach dem Beschneiden muss das System die verbleibenden Schichten wieder zu einem kohärenten 3D‑Bild „zusammenfügen“. Die Autoren erreichen das, indem sie zwei komplementäre Blickwinkel auf die Daten kombinieren. Ein Pfad betrachtet lokale Formen und Kanten, wie eine Lupe, die durch das Volumen bewegt wird und auf scharfe Grenzen und Texturen reagiert. Der andere Pfad transformiert die Daten in eine Frequenzsicht, die besser breit angelegte Muster und langfristige Strukturen über die Schichten erfasst – etwa wie sich ein Tumor ausdehnt oder wie ein Organ insgesamt geformt ist. Ein adaptiver Fusionsschritt lernt, wie viel Vertrauen jedem Blickwinkel an jedem Punkt geschenkt werden sollte und liefert so eine Darstellung, die sowohl feine Details als auch globalen Kontext respektiert, obwohl sie von 2D‑Schnitten ausgeht.
Kleine Hinweise bewahren beim Komprimieren
Um mit einem großen Sprachmodell zu kommunizieren – dem Teil, der Fragen beantwortet und Berichte verfasst – muss die visuelle Information auf eine überschaubare Anzahl von Token oder „visuellen Wörtern“ komprimiert werden. Ein einfaches Verkleinern würde winzige, aber kritische Signale verwischen, wie kleine Verkalkungen oder subtile Texturveränderungen, die für die Diagnose wichtig sind. Um das zu vermeiden, erzeugen die Autorinnen und Autoren eine zweigleisige Repräsentation: eine hochauflösende Spur, die reich an Details bleibt, und eine kleinere, kostengünstigere Spur. Ein Attention‑Mechanismus erlaubt es jedem Punkt der kleineren Spur, selektiv in der größeren Spur „nachzuschauen“ und die schärfsten verfügbaren Details zu übernehmen. Das Ergebnis ist eine kompakte visuelle Zusammenfassung, die dennoch die Hinweise enthält, die Radiologinnen und Radiologen wichtig sind, und die dann dem Sprachmodell zur weiteren Schlussfolgerung übergeben wird.
Nachweis an realen medizinischen Aufgaben
Um ihr Design zu prüfen, evaluierten die Forschenden es auf öffentlichen 3D‑Benchmarks mit zwei zentralen Aufgaben: Kann das System radiologieähnliche Beschreibungen von 3D‑Scans verfassen, und kann es Fragen zu dem in ihnen Sichtbaren beantworten? Ihr Ansatz übertraf, obwohl niemals ein 3D‑spezifischer Encoder trainiert wurde, mehrere starke 3D‑basierte Modelle in beiden Aufgaben. Er erzeugte präzisere, klinisch reichhaltigere Befunde und beantwortete Fragen genauer, auch schwierige Fragen zur exakten beteiligten Organstruktur, Auffälligkeit oder Lokalisation. Zudem lief das System schneller, benötigte deutlich weniger 3D‑Trainingsdaten und generalisierte gut auf unterschiedliche Scan‑Typen wie MRT und PET.
Was das für die zukünftige Versorgung bedeutet
Praktisch gezeigt bedeutet diese Arbeit, dass es nicht nötig ist, mit datenhungrigen 3D‑Modellen von vorn zu beginnen, um hochwertige KI‑Unterstützung bei volumetrischen Scans zu erhalten. Durch intelligentes Wiederverwenden eines starken 2D‑Experten, gezielte Auswahl informativer Schichten und den Wiederaufbau des 3D‑Bildes bei gleichzeitiger Bewahrung winziger Details erreichen die Autorinnen und Autoren Spitzenleistung mit deutlich weniger Daten und Rechenaufwand. Bei breiter Anwendung könnte ein solcher Ansatz fortschrittliche KI‑Unterstützung – wie bessere Befunde, klarere Erklärungen und zuverlässigere Triage – für Krankenhäuser und Kliniken zugänglich machen, denen umfangreiche Datenressourcen fehlen, und so die anspruchsvolle Bildanalyse näher an die routinemäßige klinische Praxis bringen.
Zitation: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Schlüsselwörter: 3D-Medizinbildgebung, Vision‑Language‑Modelle, Radiologie‑KI, daten-effizientes Lernen, CT‑ und MRT‑Analyse