Clear Sky Science · de
Eine kaskadierte Interferometer‑Mikroresonator‑Struktur für photonic reservoir computing
Licht als ultraschneller Problemlöser
Das moderne Leben läuft auf Daten: von Streaming‑Video bis zu Hochgeschwindigkeits‑Internet‑Backbones treiben wir Elektronik ständig dazu, Informationen schneller zu bewegen. Herkömmliche Computerchips tun sich dabei schwer, ohne Überhitzung oder enormen Energieverbrauch mitzuhalten. Diese Arbeit untersucht einen anderen Ansatz – Licht auf einem Chip zur Teilübernahme der Berechnung zu nutzen. Die Autoren zeigen, wie eine clevere Kombination winziger optischer Schaltkreise komplexe zeitveränderliche Signale mit Dutzenden von Milliarden Operationen pro Sekunde verarbeiten kann, während die Lösung zugleich einfacher und praktischer bleibt als frühere Entwürfe.
Ein physikalischer Trick wird zur Denkmaschine
Die zentrale Idee dieser Forschung ist eine Rechenmethode namens „Reservoir Computing“. Statt ein großes, sorgfältig verdrahtetes neuronales Netzwerk zu bauen, wird ein Eingangssignal in ein festes, komplexes System eingespeist – hier ein Netzwerk winziger optischer Bauelemente auf einem Chip. Durch die Interferenz und Vermischung von Lichtwellen innerhalb dieses Netzwerks transformiert das System das Eingangssignal auf natürliche Weise in ein vielfältiges Muster interner Zustände. Eine einfache elektronische Schaltung am Ausgang lernt dann, wie diese Zustände zu kombinieren sind, um Signale vorherzusagen oder zu klassifizieren, etwa komplizierte Zeitreihen für Machine‑Learning‑Benchmarks oder verzerrte Datenströme in Glasfaserverbindungen.
Warum frühere photonische Ansätze an eine Geschwindigkeitsgrenze stießen
Frühere optische Reservoir‑Computer basierten oft auf den intrinsischen nichtlinearen Effekten von Silizium‑Mikroringresonatoren – mikroskopischen, rastförmigen Schleifen, die Licht einfangen und verzögern. In diesen Bauteilen verändert intensives Licht die Materialeigenschaften, was wiederum das Verhalten des Rings verändert. Obwohl dies die für Rechnen notwendige Nichtlinearität liefert, sind die entscheidenden Effekte an langsame physikalische Prozesse gebunden, etwa an die Bewegung von Ladungsträgern und Wärmeleitung, die sich über Milliardstel bis Hundertmilliardstel Sekunden abspielen. Um diese langsamen Zeitskalen zu kompensieren, müssen Ingenieure lange Verzögerungsleitungen auf dem Chip unterbringen, die schwer herzustellen sind, Verluste verursachen und letztlich die maximale Verarbeitungsgeschwindigkeit begrenzen.
Ein einfacherer, schnellerer Weg: Optik linear halten, Nichtlinearität an die Ränder verlagern
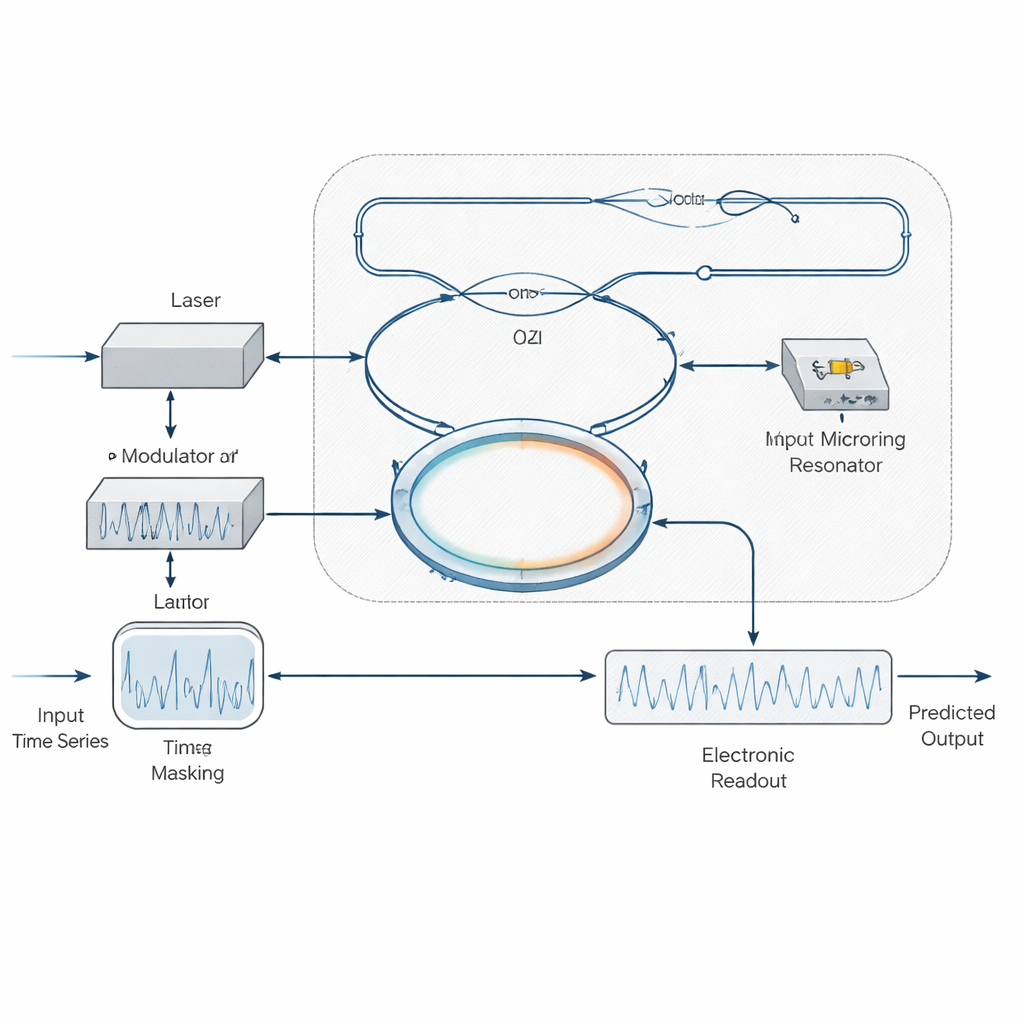
Die Autoren schlagen eine andere Strategie vor: den Mikroringresonator im rein linearen Regime zu betreiben, bei extrem niedrigen optischen Leistungen, bei denen die langsamen Materialänderungen gar nicht einsetzen. Statt den Ring selbst nichtlinear wirken zu lassen, verlagern sie die Nichtlinearität auf die Modulations‑ und Detektionsstufen. Ein kontinuierlich strahlender Laser wird zunächst mit einer maskierten Version des Eingangssignals überprägt – durch Variation der Helligkeit oder der Phase des Lichts – und dann durch ein On‑Chip‑Interferometer (eine Mach‑Zehnder‑Struktur) gefolgt vom Mikroring geleitet. Diese linearen Komponenten erzeugen mehrere verzögerte und gefilterte Kopien des Signals, die miteinander interferieren. Trifft dieses komplexe optische Muster auf einen Photodetektor, der Feldstärke natürlich in Intensität umwandelt, entsteht die benötigte Nichtlinearität „gratis“. Eine elektronische Ausleseschicht lernt anschließend, wie aktuelle und vergangene Detektorsamples zu gewichten sind, wodurch die Gedächtnisaufgaben effektiv zwischen Optik und Elektronik geteilt werden.
Aufbau eines kompakten optischen „Kurzzeitgedächtnisses“
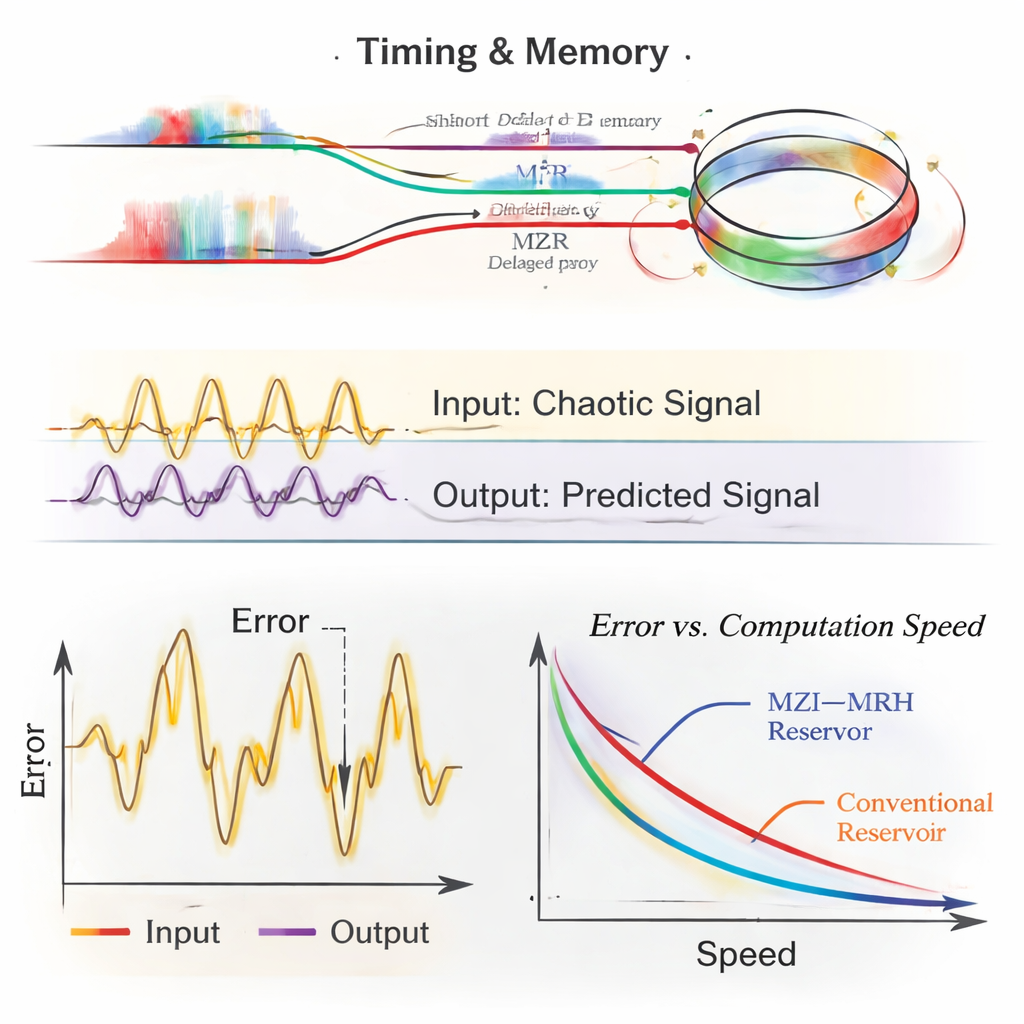
Um die Leistungsfähigkeit ihres Entwurfs zu demonstrieren, simulieren die Forschenden ein Reservoir, das aus einem unausgeglichenen Mach‑Zehnder‑Interferometer besteht, das kaskadiert mit einem Mikroringresonator verbunden ist. Durch sorgfältige Wahl der Längenunterschiede der Interferometerarme und der Kopplungsstärke des Rings an die Bus‑Wellenleiter stimmen sie ab, wie stark verschiedene „Zeitpunkte“ des Eingangssignals miteinander interagieren können. Sie untersuchen außerdem, wie die Länge der digitalen Maske und die Zahl der in der elektronischen Auslese genutzten Samples die Leistung beeinflussen. Mit kurzen Masken und einem vergleichsweise modesten elektronischen Speicher bewältigt ihr System Standard‑Vorhersageaufgaben wie NARMA‑10, Mackey‑Glass und Santa‑Fe‑Zeitreihen mit hoher Genauigkeit und erreicht dabei niedrige Fehler bei effektiven Rechengeschwindigkeiten von etwa 8 bis 25 Gigahertz – bis zu einer Größenordnung schneller als viele frühere siliziumbasierte optische Reservoirs.
Bereinigung realer optischer Kommunikationssignale
Über abstrakte Benchmarks hinaus wenden die Forscher ihr Reservoir auf ein realistisches Glasfaserkommunikationsszenario an: einen 112‑Gigabaud‑PAM‑4‑Kanal (vierstufige Pulsamplitudenmodulation) im O‑Band, ähnlich den Setups, die für 800‑Gigabit‑Ethernet standardisiert werden. Solche Verbindungen leiden unter Dispersion in der Faser und Verzerrungen durch die Senderlaser. In Simulationen senkt das neue photonische Reservoir die Bitfehlerrate deutlich im Vergleich zu einem konventionellen digitalen Feed‑Forward‑Equalizer gleicher Komplexität. Es toleriert außerdem mehr akkumulierte Dispersion – was einer Verlängerung der Übertragungsstrecke um rund 15 Kilometer entspricht – ohne gängige Fehlerkorrektur‑Schwellen zu überschreiten, und hält dabei die aufwendigen Operationen überwiegend im optischen Bereich.
Was das für künftiges ultraschnelles Rechnen bedeutet
Alltagssprachlich zeigt diese Studie, wie sich einfache optische Bauelemente in einen leistungsfähigen, hochgeschwindigkeitsfähigen „analogen Vorverarbeiter“ für Daten verwandeln lassen. Indem langsame Materialeffekte und lange optische Verzögerungen vermieden und stattdessen schnelle Modulatoren, Detektoren sowie intelligente digitale Nachverarbeitung genutzt werden, kann der vorgeschlagene Entwurf prinzipiell auf Dutzende oder sogar Hunderte Gigahertz mit vorhandener Technologie skaliert werden. Das könnte künftige Rechenzentren und Kommunikationssysteme schneller und energieeffizienter machen, indem kompakte photonische Chips als Frontend‑Co‑Prozessoren komplexe Signaldynamiken behandeln, bevor digitale Elektronik übernimmt.
Zitation: Mataji-Kojouri, A., Kühl, S., Seifi Laleh, M. et al. A cascaded interferometer-microresonator structure for photonic reservoir computing. Sci Rep 16, 6492 (2026). https://doi.org/10.1038/s41598-026-39410-w
Schlüsselwörter: photonic reservoir computing, Siliziumphotonik, Mikroringresonator, optische Signalverarbeitung, Hochgeschwindigkeitskommunikation