Clear Sky Science · de
Vergleichende Leistungsanalyse von quantenbasierten Feature-Maps für Kernel-gestütztes maschinelles Lernen
Warum das über das Labor hinaus wichtig ist
Mit wachsender Komplexität von Daten und Aufgaben stoßen selbst die besten heutigen Methoden des maschinellen Lernens manchmal an Grenzen, Muster klar zu erkennen. Quantencomputer versprechen neue Wege zur Lösung solcher Probleme, doch ist noch unklar, wann und wie sie wirklich nützlich sind. Dieser Artikel untersucht ein praktisches Teilstück dieses Puzzles: wie man quantenbasierte Klassifikatoren entwirft und abstimmt, damit sie mit etablierten klassischen Methoden konkurrieren können und diese in manchen Fällen auf sowohl synthetischen Problemen als auch einem realen medizinischen Datensatz übertreffen.
Ähnlichkeit in Quantenstärke verwandeln
Viele erfolgreiche Lernverfahren, etwa Support-Vektor-Maschinen, beruhen auf „Kernels“, die messen, wie ähnlich sich zwei Datenpunkte nach einer nicht sichtbaren Transformation in einen reicheren Merkmalsraum sind. Quantencomputer können solche Transformationen natürlich implementieren, indem sie Daten in Quantenzustände kodieren und dann messen, wie stark zwei Zustände überlappen. Die Autoren konzentrieren sich auf diese Quantenkernel und auf die „Feature-Maps“, die einem Quantenkreis vorgeben, wie gewöhnliche Zahlen in Quantenzustände umzusetzen sind. Eine gute Feature-Map macht verstrickte Daten leichter trennbar; eine schlechte verschwendet die Quantensystemressourcen. Die Arbeit stellt zwei zentrale Fragen: Welche Feature-Maps funktionieren am besten, und wie viel lässt sich durch sorgfältiges Tuning gewinnen?
Mehrere Quantenrezepte testen
Die Forschenden führen eine neue hochordentliche Feature-Map ein und vergleichen sie mit fünf zeitgemäßen Entwürfen aus früheren Arbeiten. Jede Map verwendet einen einfachen Zwei-Qubit-Schaltkreis mit Einzelqubit-Rotationen und einem Verschränkungs-Gate, doch unterscheiden sich die mathematischen Formeln, die diese Rotationen steuern. Um die Studie fokussiert zu halten, bleiben die Struktur des Quantenkreises, die Einstellungen der Support-Vektor-Maschine und das Evaluationsverfahren konstant, während nur die Feature-Map und ihre interne „Rotationsstärke“ variiert werden. Dadurch lassen sich Leistungsgewinne direkt der Art der Datenkodierung in Quantenzustände zuschreiben und nicht zusätzlichem Feintuning des klassischen Lernalgorithmus.
Von Spielmustern bis zur Krebsdiagnose
Das Team bewertet die Quantenkernel an drei klassischen zweidimensionalen Testproblemen — konzentrische Kreise, Sichelmond‑Muster und ein XOR-Muster — sowie an einer reduzierten Version des Wisconsin Breast Cancer Diagnostic-Datensatzes. Für die medizinischen Daten werden mittels einer standardmäßigen Merkmal‑Auswahlmethode zwei der informativsten bildbasierten Merkmale ausgewählt. Alle Eingaben werden dann auf denselben Bereich skaliert und in flache Zwei-Qubit-Schaltkreise eingespeist, sodass die Experimente realistisch für gegenwärtige rauscharme, intermediäre Quantengeräte bleiben. Die Leistung wird gegen ein breites Spektrum klassischer Modelle verglichen, darunter lineare und radialbasierte SVMs, Entscheidungsbäume, Random Forests, Boosting, Naive Bayes, lineare Diskriminanzanalyse und Mehrschichtperzeptrons; als Metriken dienen Genauigkeit und der Matthews-Korrelationskoeffizient, um sowohl Korrektheit als auch Klassenbalance zu erfassen.
Was die Vergleiche zeigten
Bei den einfacheren Benchmark-Datensätzen erzielen die verbesserten Quantenkernel — insbesondere jene, die aus der neuen Feature-Map und zwei der bestehenden Maps gebaut sind — nahezu perfekte Klassifikationen und erreichen oder übertreffen die meisten klassischen Konkurrenten. Bei den anspruchsvolleren Brustkrebsmessungen bleiben die besten Quanten-Feature-Maps konkurrenzfähig gegenüber starken klassischen Baselines wie radialen Basisfunktionen und neuronalen Netzen. Ein entscheidender Regler ist der Rotationsfaktor, der skaliert, wie stark Eingabewerte die Quantenrotationen beeinflussen. Durch Variation dieses Faktors über mehrere Werte zeigen die Autoren, dass seine sinnvolle Wahl die Leistung deutlich verbessern kann und dass der beste Wert vom Datensatz abhängt. Visualisierungen der Merkmalsräume und der daraus resultierenden Entscheidungsgrenzen veranschaulichen, dass einige Maps fein abgestimmte, gut ausgerichtete Trennregionen herstellen, während andere verzerrte oder ungünstig platzierte Grenzen hinterlassen — was die Streuung der Ergebnisse erklärt.
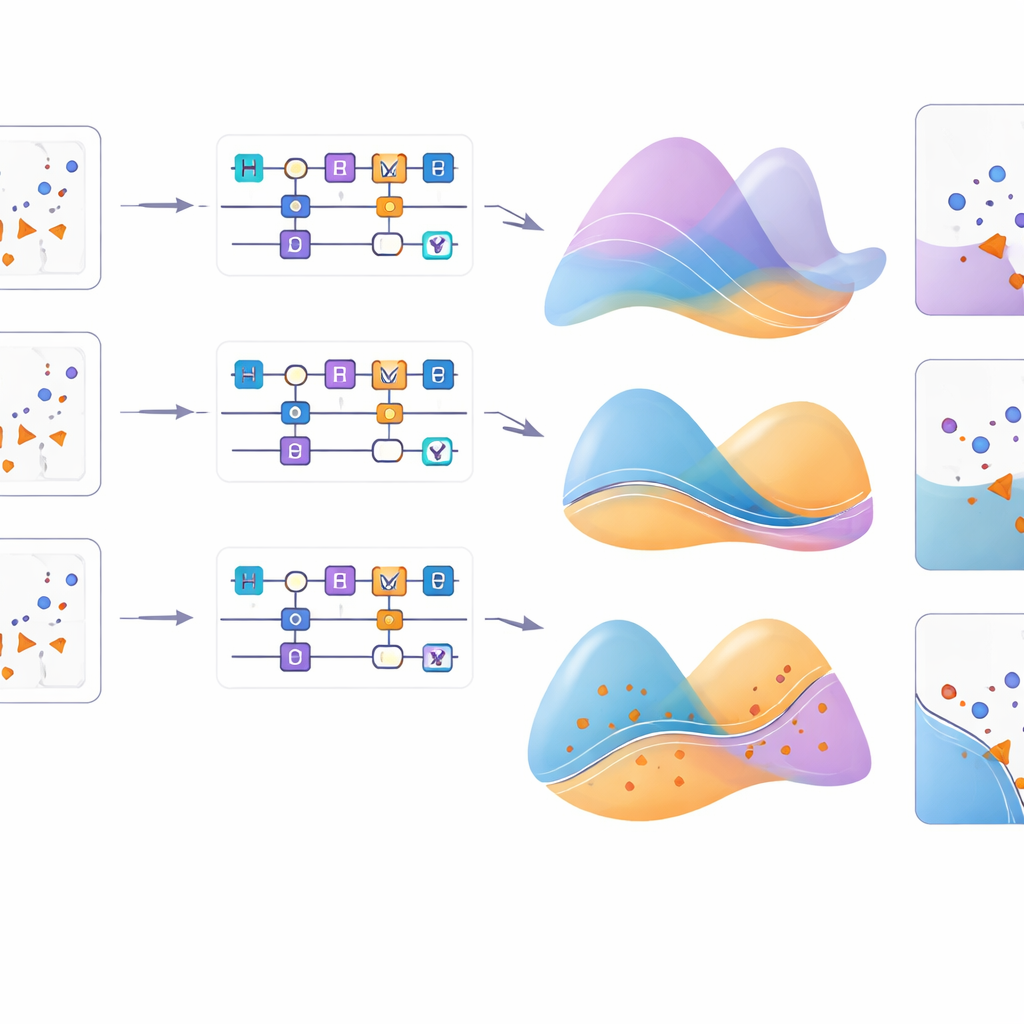
Einen genaueren Blick darauf, wie es funktioniert
Um diese Effekte besser zu verstehen, visualisiert die Studie, wie jede Feature-Map ein Gitter von Eingabepunkten für verschiedene Probleme umformt. Beim Kreis‑Muster reproduzieren die meisten Maps erfolgreich die zugrundeliegende Struktur, bei Sichelmond‑Muster und den realen Krebsdaten stimmt jedoch nur eine Teilmenge der Maps gut mit der tatsächlichen Verteilung überein. Zusätzliche Experimente variieren die Art der verwendeten Einzelqubit‑Rotation und bestätigen, dass bei bestimmten Mustern wie XOR die Wahl der Rotationsachse genauso wichtig sein kann wie die genaue Kodierungsformel. Insgesamt zählt die neue Feature-Map beständig zu den besten, besonders in Kombination mit einem geeigneten Rotationsfaktor, und unterstreicht das feine Zusammenspiel zwischen Quanten‑Gates, Kodierungsformeln und Hyperparameter‑Einstellungen.
Was das für die Zukunft bedeutet
Für Nicht-Spezialisten lautet die wichtigste Botschaft: Ein quantenbasierter Vorteil im maschinellen Lernen entsteht nicht „einfach so“, nur weil Standardmodelle auf Quantenhardware ausgeführt werden. Erfolg hängt vielmehr davon ab, die richtige Art zu entwickeln, Daten in Quantenkreise einzuspeisen, und einige kritische Einstellungen so zu justieren, dass die Quantenzustände die Struktur der Aufgabe widerspiegeln. Dieser Artikel liefert eine Roadmap dafür, genau dies bei Quantenkernel‑Methoden zu tun, und zeigt, dass durchdacht entworfene und abgestimmte Quanten-Feature-Maps selbst mit sehr kleinen Schaltkreisen starke, teils überlegene Leistungen erzielen können. Gleichzeitig weisen die Autoren darauf hin, dass ihre Ergebnisse auf Rausch‑freien Simulationen und vergleichsweise bescheidenen Datensätzen beruhen; die vollständige Realisierung dieser Vorteile auf realen Quantenmaschinen und in größerem Maßstab bleibt daher eine wichtige Herausforderung für zukünftige Arbeiten.
Zitation: Jha, R.K., Kasabov, N., Bhattacharyya, S. et al. Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning. Sci Rep 16, 8142 (2026). https://doi.org/10.1038/s41598-026-39392-9
Schlüsselwörter: quantum machine learning, quantum kernels, feature maps, hyperparameter tuning, classification