Clear Sky Science · de
CGDFNet: ein dualer Echtzeit-Semantischen-Segmentationsnetzwerk mit kontextgeführter Detailfusion
Autos beibringen, die ganze Straße zu sehen
Moderne Autos und Roboter verlassen sich zunehmend auf Kameras, um die Umgebung zu erfassen — Straßen, Gehwege, Personen, Fahrzeuge und Schilder in Echtzeit zu erkennen. Dieses Papier stellt CGDFNet vor, ein neues Computer‑Vision‑System, das genau diese Art von „Szenenverständnis“ schneller und genauer ausführen soll, besonders in belebten Straßen. Indem es gleichzeitig feine Details (wie Ampelmasten oder Fahrradreifen) und den großflächigen Aufbau (wie Straßen und Gebäude) im Blick behält, zielt CGDFNet darauf ab, automatisiertes Fahren und andere Echtzeit‑Visionsaufgaben sicherer und zuverlässiger zu machen.
Warum Pixel‑genaue Sicht so anspruchsvoll ist
Bei der semantischen Segmentierung ordnet ein Computer jeder einzelnen Bildpixel eine Kategorie zu: Straße, Auto, Fußgänger, Himmel usw. Das ist deutlich anspruchsvoller als nur ein Rechteck um ein Auto zu zeichnen, weil das System Objektgrenzen und kleine Formen sehr präzise nachzeichnen muss. Viele hochgenaue Methoden existieren, doch sie sind meist langsam und energiehungrig — schlecht geeignet für Echtzeitsysteme in Autos, Drohnen oder Wearables. Leichtgewichtigere, schnelle Methoden opfern dagegen oft Details oder verlieren das große Ganze aus den Augen, was bei kleinen Objekten, dünnen Strukturen oder überfüllten städtischen Szenen problematisch ist.
Zwei Pfade: einer für Details, einer für Kontext
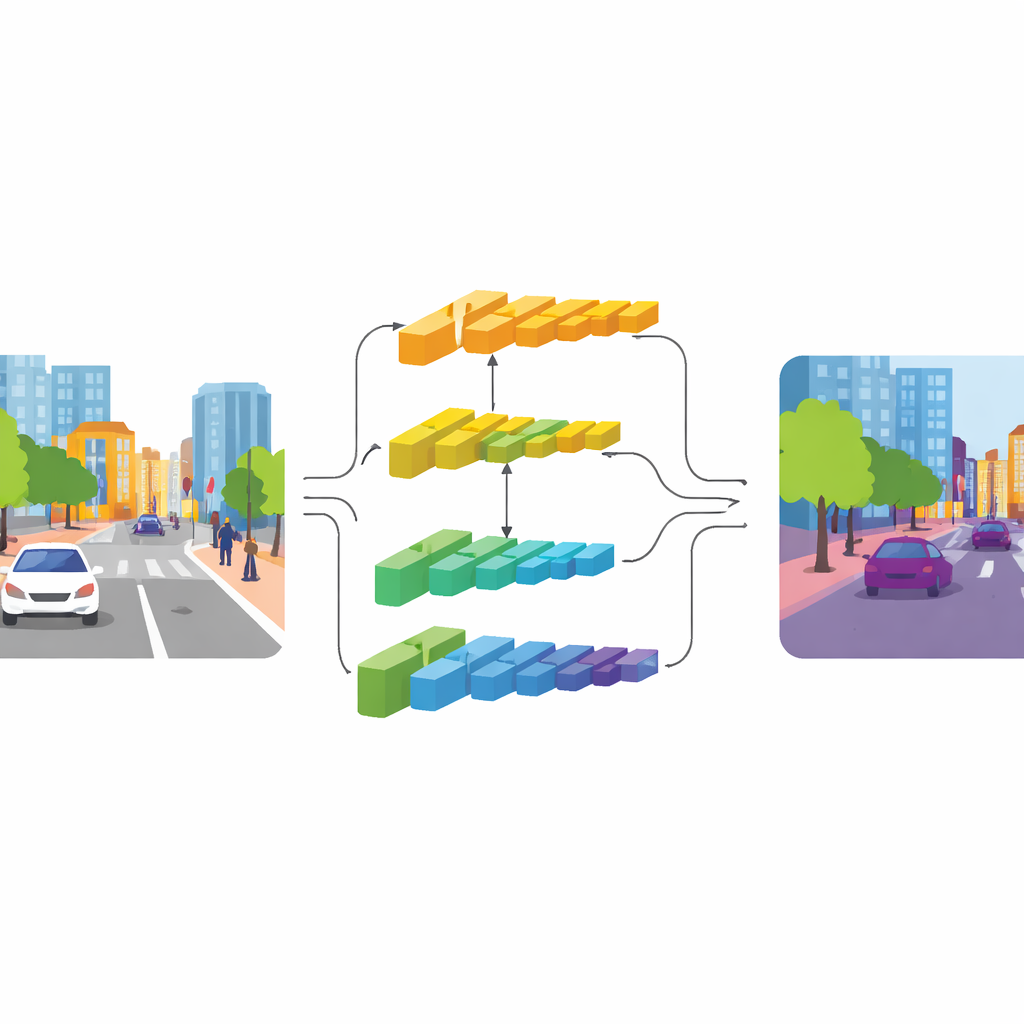
CGDFNet begegnet diesem Spannungsfeld mit einem dualen Zweig‑Design: Ein Zweig konzentriert sich auf scharfe Details, der andere erfasst den weiten Kontext. Aufbauend auf einem effizienten Backbone speisen niedrigere Schichten einen „Detailzweig“, der höhere Auflösung behält, um Kanten und Texturen zu bewahren. Tiefere Schichten speisen einen „Kontextzweig“, der die Szene stärker komprimiert betrachtet und so gut die Gesamtstruktur und Beziehungen zwischen Objekten erfasst. Anders als frühere Zwei‑Zweig‑Entwürfe, die diese Ströme weitgehend getrennt halten und am Ende grob zusammenfügen, fördert CGDFNet den kontinuierlichen Austausch zwischen ihnen während der Verarbeitung, sodass feine Details ständig gegen das Wissen über die Gesamtszene abgeglichen werden.
Details mit Bedeutung leiten
Zwei zentrale Komponenten stärken diese Interaktion. Im Kontextzweig lernt ein Semantic Refinement Module, die informativsten Regionen und Kanäle in seinen Merkmalskarten hervorzuheben. Es kombiniert lokale Hinweise (welche Bildbereiche in der Nähe aktiv sind) mit globalen Signalen (was das Netzwerk über das gesamte Bild sieht), sodass die Repräsentation sowohl Nachbarschaftsdetails als auch szenenweite Bedeutung trägt. Im Detailzweig verwendet ein Context‑Guided Detail Module diese semantischen Informationen, um die Aufmerksamkeit auf Kanten und feine Strukturen zu lenken, die wichtig sind, etwa die Kontur eines Busses oder den Rahmen eines Fahrrads. Es nutzt eine spezielle Art von Faltung, die empfindlicher auf Unterschiede zwischen benachbarten Pixeln reagiert und so Konturen und kleine Objekte betont, ohne viele zusätzliche Parameter hinzuzufügen.
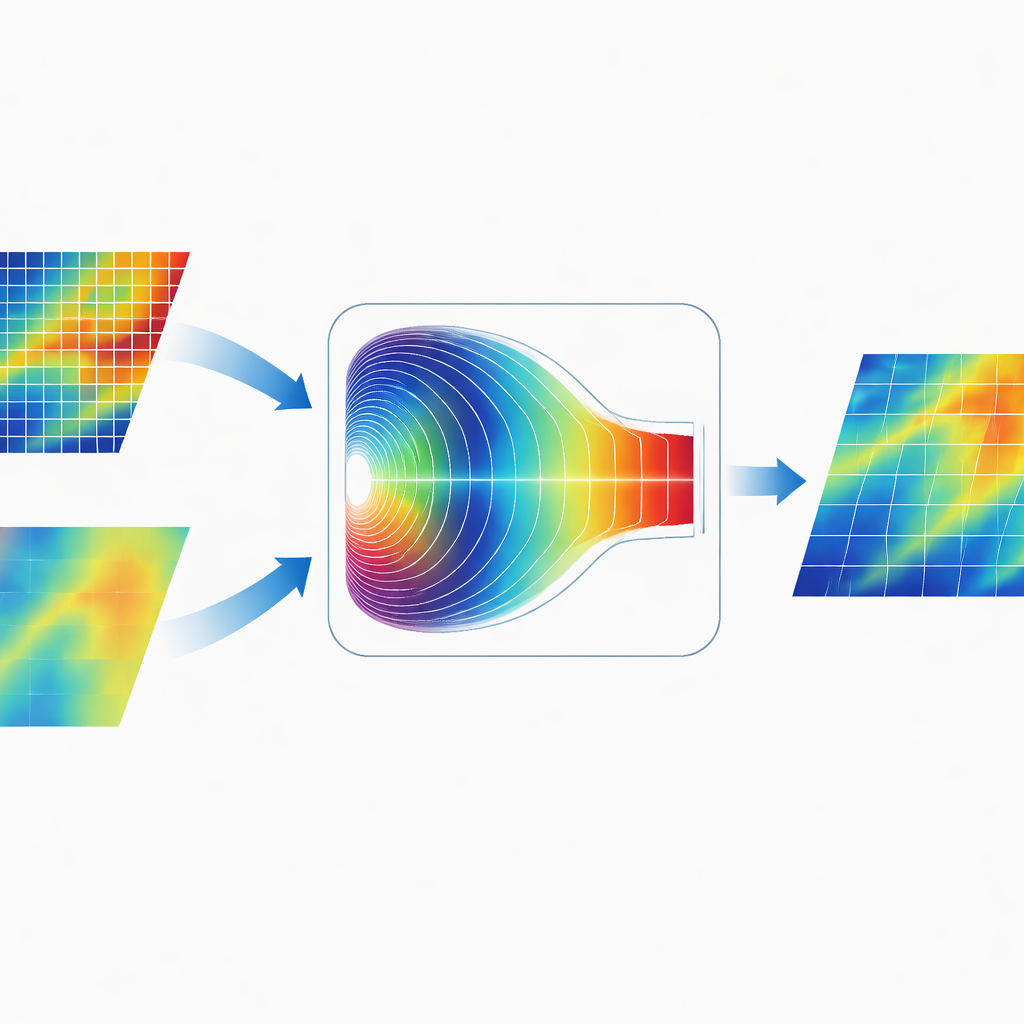
Informationen in der Frequenz‑Welt mischen
Ein markantes Merkmal von CGDFNet ist, wie es die beiden Zweige zusammenführt. Anstatt ihre Karten einfach im Bildraum zu addieren, entwerfen die Autoren ein Fourier‑Domain Adaptive Fusion Module. Dieses Modul transformiert die kombinierten Merkmale vorübergehend in den Frequenzbereich, wo Muster als langsame, breitflächige Variationen und schnelle, scharfe Änderungen dargestellt werden. Ein adaptiver Steuermechanismus lernt dann, welche Frequenzkomponenten vom Detailzweig und welche vom Kontextzweig betont werden sollen. Nach dieser Gewichtung werden die Merkmale zurücktransformiert, wodurch eine Repräsentation entsteht, die scharfe Kanten mit kohärenter globaler Struktur effektiver vereint als herkömmliche rein räumliche Fusionen.
Ergebnisse auf realen Straßen
Das Team testete CGDFNet auf zwei weitverbreiteten Benchmarks für städtische Fahrszenen: Cityscapes, aufgenommen in europäischen Städten, und CamVid, aus Fahrerperspektive im Vereinigten Königreich. CGDFNet verarbeitete große Bilder in Echtzeit — etwa 88 Frames pro Sekunde auf Cityscapes und rund 129 Frames pro Sekunde auf CamVid — und erreichte dabei Segmentierungsgenauigkeit, die mit vielen State‑of‑the‑Art‑Systemen mithalten oder sie übertreffen kann. Besonders gut schnitt es bei Kategorien ab, die normalerweise schwer zu segmentieren sind, wie Zäune, Verkehrszeichen, Busse und Fahrräder, wo das Bewahren präziser Grenzen und kleiner Strukturen entscheidend ist.
Was das für Alltagstechnologie bedeutet
Praktisch zeigt CGDFNet, dass es möglich ist, Vision‑Systeme zu bauen, die sowohl schnell genug für Echtzeitanwendungen als auch sorgfältig genug sind, um kleine, sicherheitskritische Details in komplexen Stadtszenen zu berücksichtigen. Durch die Kombination eines detailorientierten Zweigs, eines kontextorientierten Zweigs und eines intelligenten Fusionsschritts im Frequenzbereich behält das Netzwerk eine ausgewogene Sicht auf die Straße: Es weiß, wo alles ist und wo jedes Objekt beginnt und endet. Zwar bleiben Herausforderungen bestehen — etwa dichtgedrängte Menschenmengen oder schlechtes Wetter — doch der Ansatz bietet ein vielversprechendes Konzept für zukünftige On‑Device‑Vision, von selbstfahrenden Autos über intelligente Verkehrskameras bis zu assistiven Robotern.
Zitation: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Schlüsselwörter: Echtzeit-Semantische Segmentierung, Vision für autonomes Fahren, Dualer Zweig-Neuronales Netzwerk, Fourier-basierte Merkmalsfusion, Stadtbildverständnis