Clear Sky Science · de
Skelett-Bewegungs‑Topology‑maskierte Vorhersage und kontrastives Lernen für selbstüberwachtes Erkennen menschlicher Aktionen
Computern beibringen, Körpersprache zu lesen
Von Video-Türklingeln bis zu intelligenten Reha‑Hilfen: Viele moderne Systeme müssen allein aus der Bewegung von Menschen erkennen, was sie tun. Das Trainieren von Computern zur Erkennung menschlicher Aktionen erfordert jedoch meist große, sorgfältig annotierte Datensätze, in denen jede Geste, jeder Tritt oder Handschlag manuell beschriftet ist. Diese Studie stellt einen Weg vor, wie Maschinen ausschließlich aus rohen Bewegungsdaten lernen können, indem sie nur das bewegte Skelett des Körpers nutzen—ohne Labels, ohne Gesichter und ohne Vollfarbvideo—was die Aktionserkennung genauer, privater und deutlich weniger abhängig von teuren menschlichen Annotationen macht.
Warum Skelettdaten genügen
Anstatt Vollbild‑Video zu analysieren, arbeitet die Methode mit 3D‑Skelettdaten: den Koordinaten wichtiger Gelenke wie Schultern, Ellbogen, Hüften und Knien über die Zeit. Diese reduzierte Darstellung des Körpers hat mehrere Vorteile. Sie umgeht weitgehend Datenschutzprobleme, weil Gesichter und Kleidung entfallen, und ist kompakt genug, um auch lange Aufnahmen effizient zu verarbeiten. Skelettdaten sind zudem robust gegenüber unruhigen Hintergründen und Lichtverhältnissen, die herkömmliche videobasierte Systeme irritieren können. Dennoch verlassen sich die meisten existierenden Skelett‑Methoden noch stark auf gelabelte Beispiele und haben Schwierigkeiten, komplexe, koordinierte Gelenkbewegungen vollständig zu erfassen.
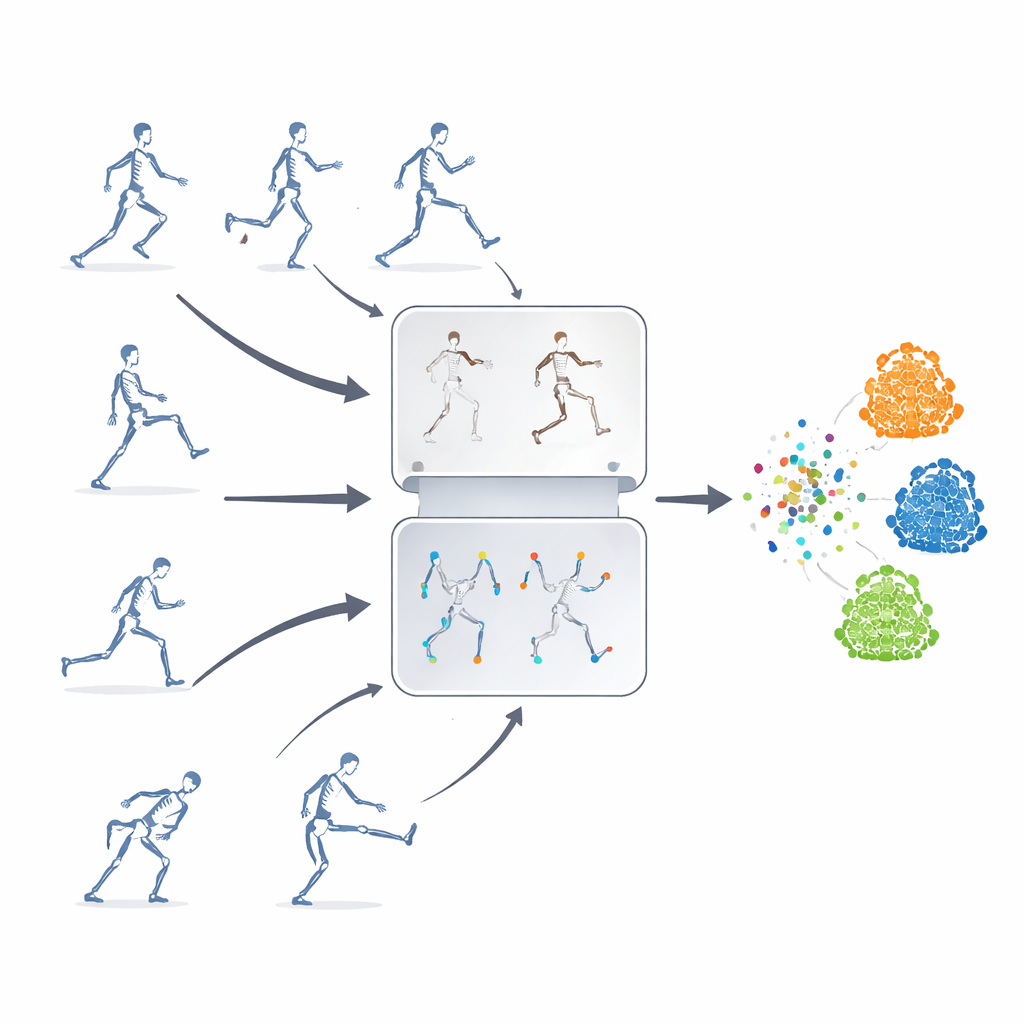
Lernen ohne Labels
Die Autoren schlagen ein selbstüberwachtes Lernframework vor, das heißt das System bringt sich aus unlabeled Skelettsequenzen selbst etwas bei. Ihre Kernidee ist, zwei leistungsfähige Strategien zu kombinieren, die üblicherweise separat verwendet werden. Die eine ist „maskierte Vorhersage“, bei der Teile der Skelettdaten absichtlich verborgen werden, sodass das Modell die fehlende Bewegung aus dem verbliebenen Kontext erraten muss. Die andere ist „kontrastives Lernen“, bei dem dem Modell mehrere veränderte Versionen derselben Aktion gezeigt werden und es lernt, dass diese Varianten trotzdem dieselbe zugrunde liegende Bewegung darstellen. Durch die Verbindung dieser Ansätze lernt das System sowohl feine Details der Gelenkbewegung als auch das große Ganze einer Aktion.
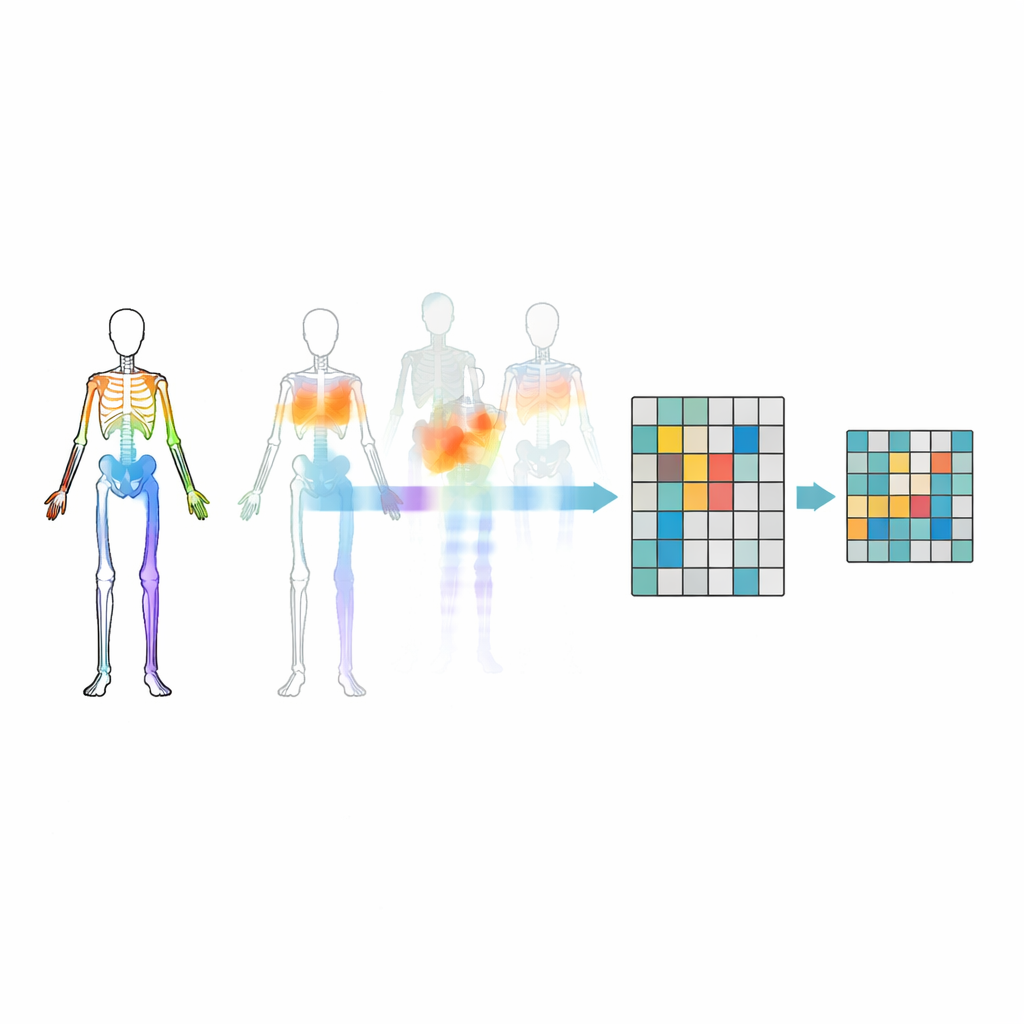
Die richtigen Gelenke verbergen
Einfach zufällige Gelenke zu maskieren reicht nicht aus—das Modell könnte wichtige Zusammenhänge zwischen Körperteilen ignorieren oder sich auf die offensichtlichste Bewegung fixieren. Um das zu vermeiden, führen die Forschenden eine Bewegungs–Topologie‑Maskierungsstrategie ein. Sie gruppieren Gelenke in sinnvolle Körperregionen wie Arme, Beine und Rumpf und messen, wie stark sich jede Region über die Zeit bewegt. Maskierungsentscheidungen werden sowohl von der Körperstruktur als auch von der Bewegungsstärke der Regionen geleitet, sodass manchmal sehr aktive Teile verborgen werden und das Modell gezwungen ist, sie aus dem Rest des Körpers zu erschließen. Dieses gezielte Verbergen hilft dem System zu lernen, wie Gelenke bei Aktionen zusammenarbeiten, statt nur ein paar auffällige Bewegungen auswendig zu lernen.
Aktionen auf vielfältige Weise strecken
Für den kontrastiven Teil des Systems wird dieselbe ursprüngliche Skelettsequenz in viele verschiedene „Ansichten“ transformiert. Manche Änderungen sind dezent, etwa das Beschneiden des Zeitfensters oder eine leichte Verzerrung der Trajektorie, während andere stärker ausfallen, einschließlich Spiegelungen, Rotationen und stärkerem Rauschen. Diese mehreren Ebenen von Augmentierungen setzen das Modell einer reichen Vielfalt von Bewegungsmustern aus und ermutigen es, sich auf die Kernstruktur einer Aktion statt auf oberflächliche Details zu konzentrieren. Gleichzeitig verfolgt ein trajektoriengeführtes Feature‑Dropping‑Modul, auf welche Bewegungsmerkmale das Modell am meisten vertraut, und unterdrückt diese gezielt während des Trainings. Indem seine bevorzugten Hinweise vorübergehend entfernt werden, wird das System dazu gebracht, Ausweichhinweise zu entdecken und allgemeinere, übertragbare Repräsentationen zu erlernen.
Wie gut funktioniert es?
Das Framework wurde an drei großen öffentlichen Benchmarks für 3D‑Mensch‑Aktionen getestet, die Alltagsverhalten, medizinisch relevante Bewegungen und Interaktionen zwischen Personen abdecken. Obwohl es nur skelettbasierte Gelenkdaten und ein vergleichsweise leichtes rekurrentes neuronales Netzwerk verwendet, erreicht die Methode Werte, die mit vielen state‑of‑the‑art Systemen mithalten oder diese übertreffen, welche komplexere Eingaben oder Architekturen nutzen. Besonders stark ist sie, wenn Annotationen knapp sind oder Teile des Körpers verdeckt sind—Bedingungen, die in realen Umgebungen häufig vorkommen. Während die Fähigkeit, Wissen zwischen sehr unterschiedlichen Datensätzen zu übertragen, noch Raum für Verbesserungen lässt, verringert der Ansatz die Lücke zwischen gelabeltem und ungelabeltem Training für die Aktionserkennung deutlich.
Was das für reale Systeme bedeutet
Für Nicht‑Spezialisten ist die Kernaussage, dass diese Arbeit zeigt, wie Computer deutlich besser Körpersprache lesen können, ohne dass jede Bewegung explizit erklärt werden muss. Durch intelligentes Verbergen und Verfremden von Skelettdaten während des Trainings lernt das Modell robuste Bewegungsmuster, die auch bei schlechten Lichtverhältnissen, visuellem Durcheinander oder fehlenden Gelenken Bestand haben—und das mit deutlich weniger menschlich bereitgestellten Labels. Das eröffnet Möglichkeiten für privatere, skalierbarere und anpassungsfähigere Aktionserkennungssysteme in Anwendungen von Heimüberwachung und Sportcoaching bis hin zu medizinischer Rehabilitation und Mensch‑Roboter‑Interaktion.
Zitation: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Schlüsselwörter: Erkennung menschlicher Aktionen, 3D-Skelettdaten, selbstüberwachtes Lernen, kontrastives Lernen, Bewegungsanalyse