Clear Sky Science · de
Deep Learning-gestützte Pseudonymisierung zum Schutz der Datenprivatsphäre finanzieller Kennungen in öffentlichen Dokumenten in Indien
Warum Ihre Unterschrift auf einem Ausweis gefährdet ist
Die meisten von uns unterschreiben Namen auf amtlichen Ausweisen, Bankformularen und Steuerunterlagen, ohne daran zu denken, dass diese geschwungenen Linien kopiert, gefälscht oder von Kriminellen analysiert werden können. Da immer mehr Stellen diese Dokumente scannen und online teilen, sind handschriftliche Unterschriften – die an vielen Orten weiterhin rechtlich bindend sind – zu einem attraktiven Ziel für Identitätsdiebstahl geworden. Diese Arbeit untersucht eine neue Methode, Unterschriften auf indischen Steuer‑ID‑Karten zu verbergen, ohne die Nützlichkeit der Dokumente für die Archivierung, Prüfungen und mögliche spätere Sicherheitsüberprüfungen zu verlieren.
Echte Unterschriften in sichere Stellvertreter verwandeln
Die Autoren konzentrieren sich auf die indische Permanent Account Number (PAN)-Karte, die häufig für finanzielle Transaktionen und Steuererklärungen verwendet wird. Diese Karten tauchen zunehmend in E‑Mails, Cloud‑Speichern und öffentlichen Einreichungen auf, wo freigelegte Unterschriften kopiert oder auf gefälschte Dokumente gedruckt werden können. Einfaches Verwischen oder Schwärzen der Unterschrift schützt zwar die Privatsphäre, zerstört aber den Wert des Dokuments für spätere Verifizierungen oder Untersuchungen. Stattdessen verwenden die Forscher eine Strategie namens Pseudonymisierung: Die ursprüngliche Unterschrift wird erkannt und durch eine synthetische, ähnlich aussehende Unterschrift ersetzt, die Position und Struktur der Markierung bewahrt, aber nicht mehr eng genug der Handschrift der realen Person entspricht, um missbraucht zu werden.
Wie ein intelligentes Vision‑System erkennt, was zu verbergen ist
Um diesen Prozess zu automatisieren, baut das Team auf ein Deep‑Learning‑Modell namens SuperPoint auf, das ursprünglich dafür entwickelt wurde, wichtige Punkte in Bildern zu finden – etwa Ecken und Kanten –, die auch bei Rauschen, Schieflage oder leichter Unschärfe zuverlässig bleiben. Die Methode verarbeitet PAN‑Karten‑Scans zunächst vor, indem sie deren Größe anpasst und in Graustufen konvertiert, um die Rechnung zu vereinfachen. Anschließend isoliert sie den Bereich mit der Unterschrift. Innerhalb dieses Bereichs wirkt das SuperPoint‑Netzwerk wie eine spezialisierte Lupe: Ein Teil des Netzwerks erzeugt eine Heatmap, die zeigt, wo markante Stiftstriche liegen, und ein anderer Teil erzeugt kompakte numerische Beschreibungen dieser Striche. Diese Kombination erlaubt es dem System, genau die Teile der Handschrift zu lokalisieren, die am charakteristischsten und damit am gefährlichsten sind, offen liegen zu bleiben.
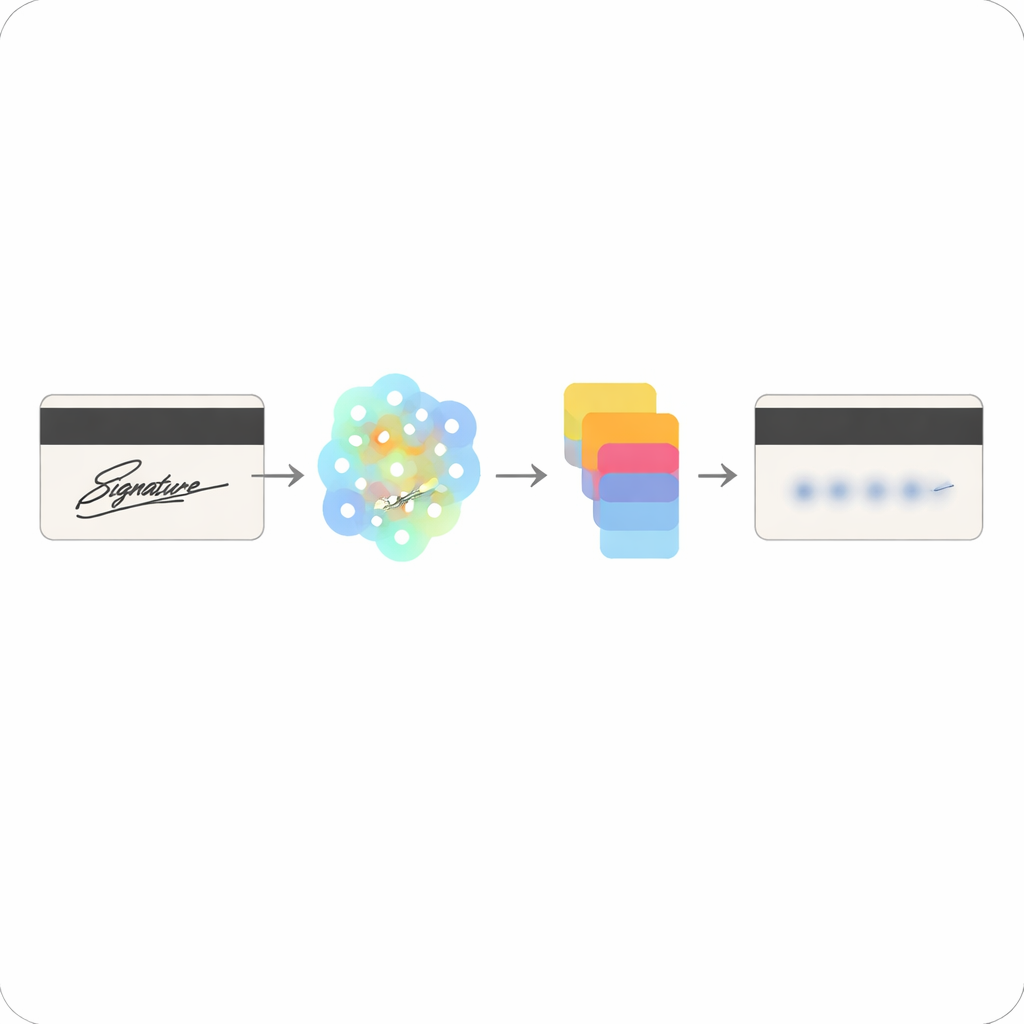
Von Strichen und Schlüsselpunkten zu maskierten Markierungen
Sobald die wichtigen Stellen in der Unterschrift identifiziert sind, ersetzt das System sie durch neutrale Formen, die das Gesamtbild eines unterschriebenen Feldes bewahren, ohne den persönlichen Stil der Schreiberin oder des Schreibers preiszugeben. Anstatt das ursprüngliche Tintenmuster zu speichern, stützt sich das Modell auf abstrakte Feature‑Maps – mathematische Zusammenfassungen, wo die Schlüsselpunkte lagen – wodurch es für einen Angreifer deutlich schwerer wird, die echte Unterschrift zu rekonstruieren. Die Autoren nutzen außerdem ein Werkzeug namens Kornia, um die rohen Ausgaben des Netzwerks in präzise Koordinaten, Skalierungen und Orientierungen zu überführen, was sicherstellt, dass die maskierte Region sauber mit dem ursprünglichen Unterschriftsbereich ausgerichtet ist und über verschiedene Kartendesigns und Scanqualitäten hinweg funktioniert.
Wie gut der neue Ansatz abschneidet
Das Framework wurde an mehr als 500 realen PAN‑Kartenbildern aus offenen Datensätzen getestet, die viele Handschriftenstile und Kartendesigns abdecken. Seine Leistung wurde mit weitverbreiteten traditionellen Merkmalserkennungsverfahren – ORB, FAST und SIFT – sowie einem tiefen Residualnetz verglichen. Die Forscher messen, wie genau das System Unterschriftsdetails findet, wie nah das maskierte Dokument im Erscheinungsbild am Original bleibt und wie viel Rechenleistung und Speicher erforderlich sind. Ihre Methode erzielt hohe Präzision und Recall bei der Lokalisierung der entscheidenden Teile der Unterschriften und erreicht einen strukturellen Ähnlichkeitswert von rund 97 Prozent, was bedeutet, dass die pseudonymisierten Karten bis auf die geschützten Markierungen nahezu identisch mit den Originalen aussehen. Gleichzeitig verwendet sie eine moderate Anzahl von Schlüsselpunkten und kompakte Deskriptoren und findet so ein Gleichgewicht zwischen Genauigkeit, Geschwindigkeit und Speicherbedarf.
Was das für den alltäglichen Datenschutz bedeutet
Für Nicht‑Spezialisten lautet die Kernbotschaft, dass es nun möglich ist, eines der sensibelsten Elemente auf einem Ausweis – Ihre handschriftliche Unterschrift – automatisch zu schützen, ohne das Dokument in ein unbrauchbares schwarzes Rechteck zu verwandeln. Indem reale Unterschriften durch sorgfältig konstruierte Stellvertreter ersetzt werden, ermöglicht das vorgeschlagene System Regierungen und Organisationen das Teilen, Speichern und Analysieren gescannter Ausweise bei gleichzeitig deutlich reduziertem Risiko von Fälschung und Identitätsdiebstahl. Die Autoren schlagen vor, dass ähnliche Deep‑Learning‑Werkzeuge in Arbeitsabläufe öffentlicher Stellen integriert werden könnten, um moderne Datenschutzvorgaben wie die DSGVO zu erfüllen, und dass die Methode schließlich über PAN‑Karten hinaus auf Pässe, Führerscheine und andere Ausweisdokumente weltweit ausgeweitet werden könnte.
Zitation: Roopalakshmi, R., Kailas, S. & Sreelatha, R. Deep learning enabled pseudonymization for preserving data privacy of financial identifiers in public documents in India. Sci Rep 16, 8120 (2026). https://doi.org/10.1038/s41598-026-39309-6
Schlüsselwörter: Signaturprivatsphäre, Identitätsschutz, Dokumentenanonymisierung, Deep-Learning-Sicherheit, Personalausweise der Regierung