Clear Sky Science · de
Ein CNN-RNN-Siamese-Rahmen mit mehrstufiger Aggregation für video-basierte Personenwiedererkennung
Warum das Verfolgen von Personen über Kameras hinweg wichtig ist
Moderne Städte sind mit Kameras übersät, doch diese Kameras "sprechen" selten miteinander. Wenn eine Person von einer Straßenecke zu einer Bahnstation geht, sehen verschiedene Kameras sie aus neuen Blickwinkeln, unter unterschiedlicher Beleuchtung und oft durch Menschenmengen. Automatisch zu erkennen, dass es sich in unterschiedlichen Videoclips um dieselbe Person handelt – sogenannte video-basierte Personenwiedererkennung – kann Ermittlern helfen, Bewegungen nach einem Vorfall nachzuverfolgen, bei der Suche nach Vermissten unterstützen oder Analysen in stark frequentierten öffentlichen Bereichen ermöglichen. Dies genau und effizient zu tun, besonders auf bescheidener Hardware, ist jedoch eine große technische Herausforderung.
Ein einfacheres "Gehirn" zum Abgleichen sich bewegender Personen
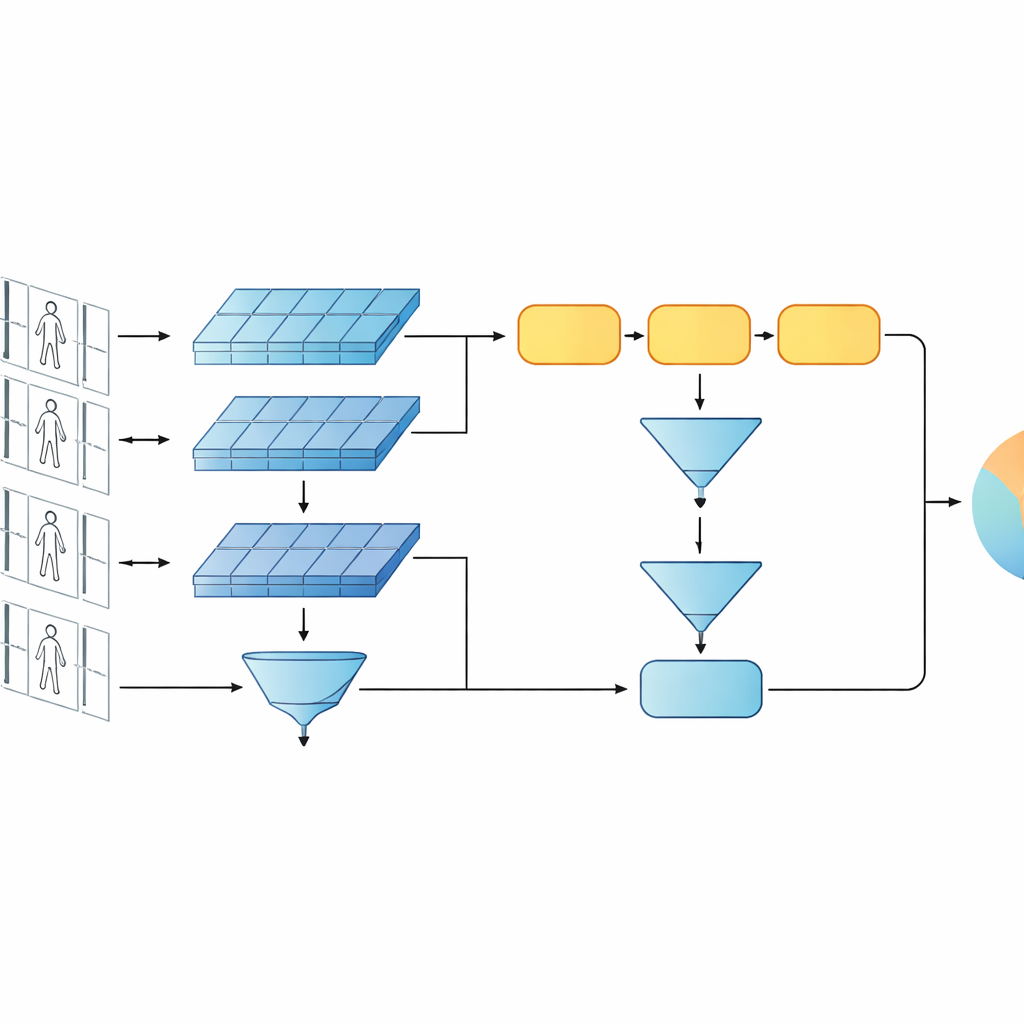
Diese Studie stellt ein kompaktes KI-System vor, das entscheidet, ob zwei kurze Videoclips dieselbe Person zeigen. Anstatt den aktuellen Trend zu sehr tiefen oder transformer-basierten Netzen zu folgen, bauen die Autoren auf einem schlankeren Entwurf auf, der zwei klassische Bausteine kombiniert: ein Faltungsnetz, das jeden Videoframe analysiert, und eine gated recurrent unit (GRU), die verfolgt, wie sich das Aussehen über die Zeit verändert. Diese beiden Zweige sind in einem Siamese-Aufbau angeordnet – praktisch Zwillingskopien desselben Netzes, die alle internen Einstellungen teilen. Jeder Zwilling verarbeitet eine Videosequenz, und das System lernt, für Clips derselben Person ähnliche interne Signaturen und für verschiedene Personen deutlich unterschiedliche Signaturen zu erzeugen.
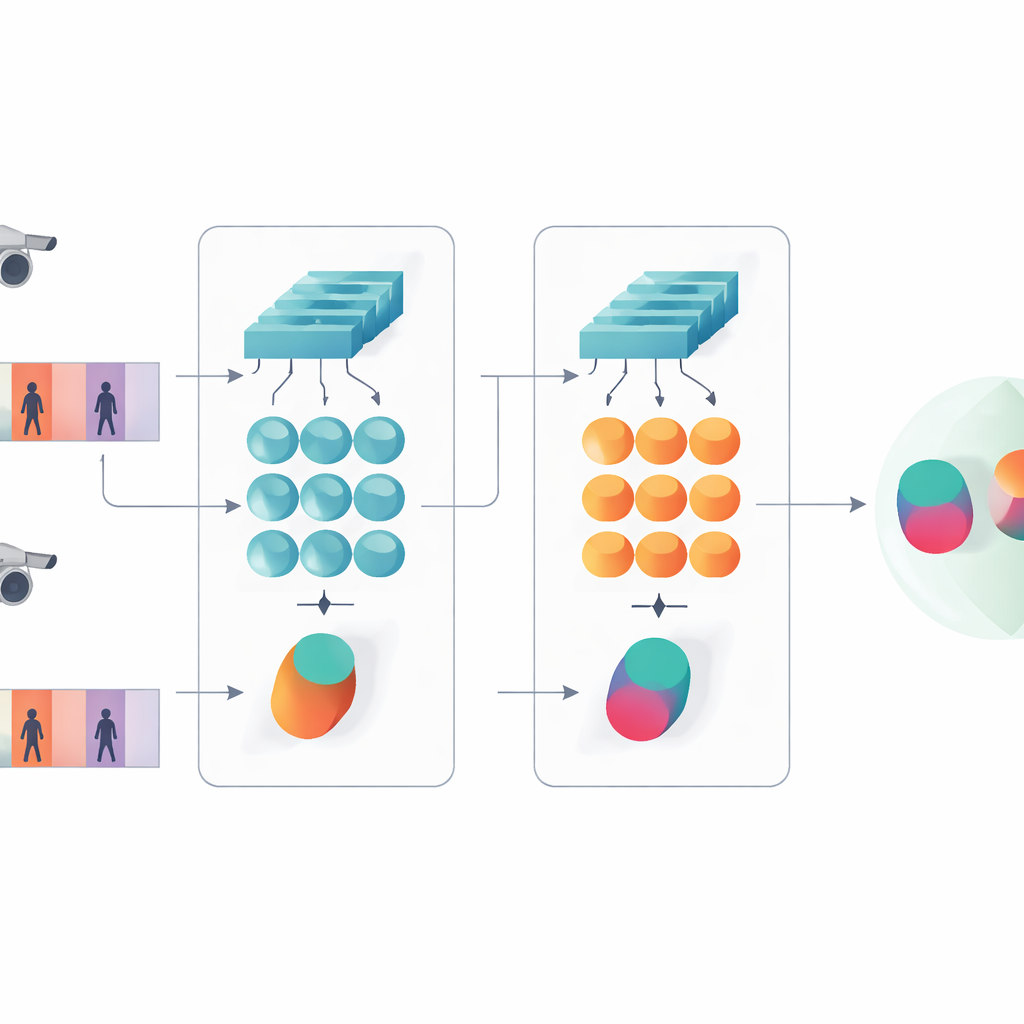
Details und zeitliche Muster zugleich sehen
Eine zentrale Idee der Arbeit ist, dass die Erkennung nicht nur auf die tiefsten, abstraktesten Merkmale eines Netzes vertrauen sollte. Frühe Schichten enthalten nach wie vor prägnante visuelle Details wie die Webart einer Jacke, Streifen auf Hosen oder die Kontur eines Rucksacks – Hinweise, die oft Veränderungen des Kamerawinkels überdauern. Das vorgeschlagene Modell hält deshalb zwei Beschreibungsebenen bereit. Ein Zweig fasst die frühen Schichtmerkmale über alle Frames zusammen, um feinkörnige Texturen und lokale Muster zu erfassen. Der andere Zweig speist spätere Merkmale in die GRU, die die Sequenz Frame für Frame verfolgt und anschließend ihre internen Zustände über die Zeit mittelt. Dieser Mittelungsschritt vermeidet eine Überbetonung der letzten Frames und erfasst stattdessen eine konsensartige Sicht darauf, wie die Person über den gesamten Clip aussieht und sich bewegt.
Die Zwillingsnetze darauf trainieren, übereinzustimmen und zu klassifizieren
Um dem System beizubringen, was wichtig ist, kombinieren die Autoren zwei Trainingsziele. Erstens ermutigt ein Verifikationsziel die Zwillinge dazu, für Videos derselben Person nahe Signaturen und für unterschiedliche Personen ferne Signaturen zu erzeugen. Zweitens verlangt ein Klassifikationsziel vom Netzwerk, jedem Trainingsclip eine spezifische Identität zuzuordnen. Durch gleichzeitige Optimierung beider Ziele und dies sowohl auf niedriger als auch auf hoher Merkmalsebene lernt das Modell interne Beschreibungen, die nicht nur zwischen Personen unterscheidbar, sondern auch robust gegenüber Rauschen, Verdeckung und gelegentlich schlechter Bildqualität sind. Das Design bleibt in Bezug auf Schichten und Parameter flach, was hilft, ein Überanpassen an verhältnismäßig kleine Videodatensätze zu vermeiden.
Tests an echten, überwachungsähnlichen Videos
Der Rahmen wird auf zwei weit verbreiteten Video-Benchmarks ausgewertet, PRID-2011 und iLIDS-VID, die kurze Gehsequenzen von Hunderten Personen enthalten, aufgenommen von Paaren räumlich getrennter Kameras. Die Studie untersucht sorgfältig verschiedene Designentscheidungen: den Austausch der GRU durch andere rekurrente Einheiten, die Änderung der Anzahl rekurrenter Schichten, die Variation der Art und Weise, wie Merkmale über die Zeit aggregiert werden, sowie das Ein- und Ausschalten der niedrigen bzw. hohen Zweige. In diesen Tests liefert eine einlagige GRU mit Mittelwert-Pooling und dem vollständigen mehrstufigen Aufbau konstant die beste Genauigkeit. Das Modell erreicht die Leistung vieler komplexerer rekurrenter und Siamese-Systeme und steht einigen auf Aufmerksamkeit basierenden Entwürfen in nichts nach, während es weit weniger Parameter und Rechenaufwand benötigt.
Effizienz für reale Einsätze
Über die Genauigkeit hinaus betont die Arbeit die Praktikabilität. Das gesamte Netzwerk verfügt nur über etwa ein bis zwei Millionen trainierbare Parameter – um Größenordnungen weniger als populäre tiefe Residual- oder transformer-basierte Backbones – und benötigt einen Bruchteil ihres Rechenaufwands pro Frame. Das macht es besser geeignet für den Einsatz auf Geräten mit begrenztem Speicher und Rechenleistung, etwa Edge-Servern in Kameranähe. Experimente zeigen außerdem, dass längere Galerie-Sequenzen, bei denen das System mehr Frames jeder gespeicherten Person sieht, die Erkennung deutlich verbessern, wenn auch mit linear steigendem Verarbeitungsaufwand. Die Autoren argumentieren, dass solche kompakten, sorgfältig gestalteten Architekturen zuverlässige Personenwiedererkennung liefern können, ohne den hohen Preis der derzeit größten Modelle.
Was das für alltägliche Überwachungssysteme bedeutet
Kurz gesagt zeigt dieses Papier, dass kluges Design reine Größe schlagen kann: Durch die Kombination flacher Bildanalyse, leichter Sequenzmodellierung und einer zweistufigen Sicht auf visuelle Ähnlichkeit ist es möglich, Personen über Kameras hinweg mit hoher Zuverlässigkeit zu verfolgen und zugleich das Modell klein und schnell zu halten. Für zukünftige Systeme, die auf vielen Kameras laufen müssen, oft mit engen Hardware- und Energiegrenzen, könnte dieser effiziente, mehrstufige Ansatz helfen, leistungsfähigere und verantwortungsvollere Videoanalytik in die Praxis zu bringen.
Zitation: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Schlüsselwörter: Personenwiedererkennung, Videoüberwachung, Siamese-Neuronale-Netzwerke, zeitliche Modellierung, effizientes Deep Learning