Clear Sky Science · de
Ein robustes Framework zur Generierung von Text‑zu‑SQL aus natürlicher Sprache mit dynamischen Strategien basierend auf LLMs
Alltägliche Fragen in Datenbankantworten verwandeln
Moderne Organisationen schwimmen in Daten, doch die meisten Menschen können nicht die technische Sprache sprechen, die nötig ist, um diese Daten abzufragen. Dieses Papier stellt TriSQL vor, ein System, das es Nutzern ermöglicht, Fragen in einfacher Sprache zu stellen und diese automatisch in präzise Datenbankbefehle zu übersetzen. Indem es genau steuert, wie große Sprachmodelle mit Komplexität umgehen, zielt das Framework darauf ab, den Datenzugriff sowohl genauer als auch verlässlicher zu machen — selbst bei den schwierigsten Fragestellungen.
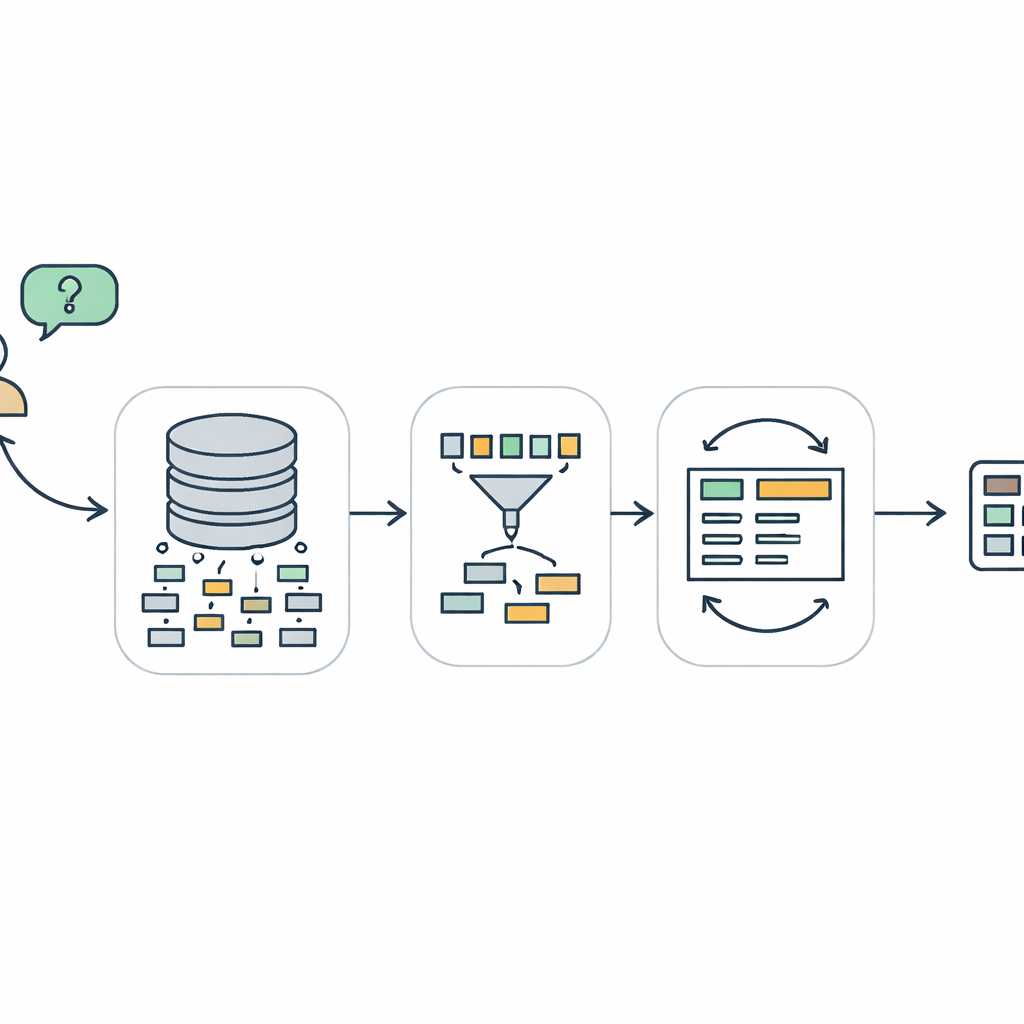
Warum das Sprechen mit Datenbanken so schwer ist
Wenn jemand eine Frage wie „Welche Kunden haben letzten Monat mehr als fünf Produkte gekauft?“ eintippt, muss ein Computer das in SQL übersetzen, die spezielle Sprache, die von den meisten Datenbanken verwendet wird. Diese Aufgabe, Text‑zu‑SQL genannt, klingt einfach, ist aber überraschend schwierig. Das System muss verstehen, was der Nutzer möchte, die richtigen Tabellen und Spalten in einer manchmal enormen und unordentlichen Datenbank finden und dann eine Abfrage erstellen, die sowohl strukturell gültig als auch dem ursprünglichen Anliegen treu ist. Frühere Systeme, einschließlich solcher, die von großen Sprachmodellen angetrieben werden, versagen oft, wenn Fragen viele Tabellen, verschachtelte Logik oder subtile Bedingungen enthalten. Sie können Abfragen erzeugen, die zwar ähnlich wie korrekte aussehen, sich aber beim Ausführen als nicht lauffähig erweisen oder falsche Ergebnisse liefern.
Ein dreistufiger Weg von Frage zu Abfrage
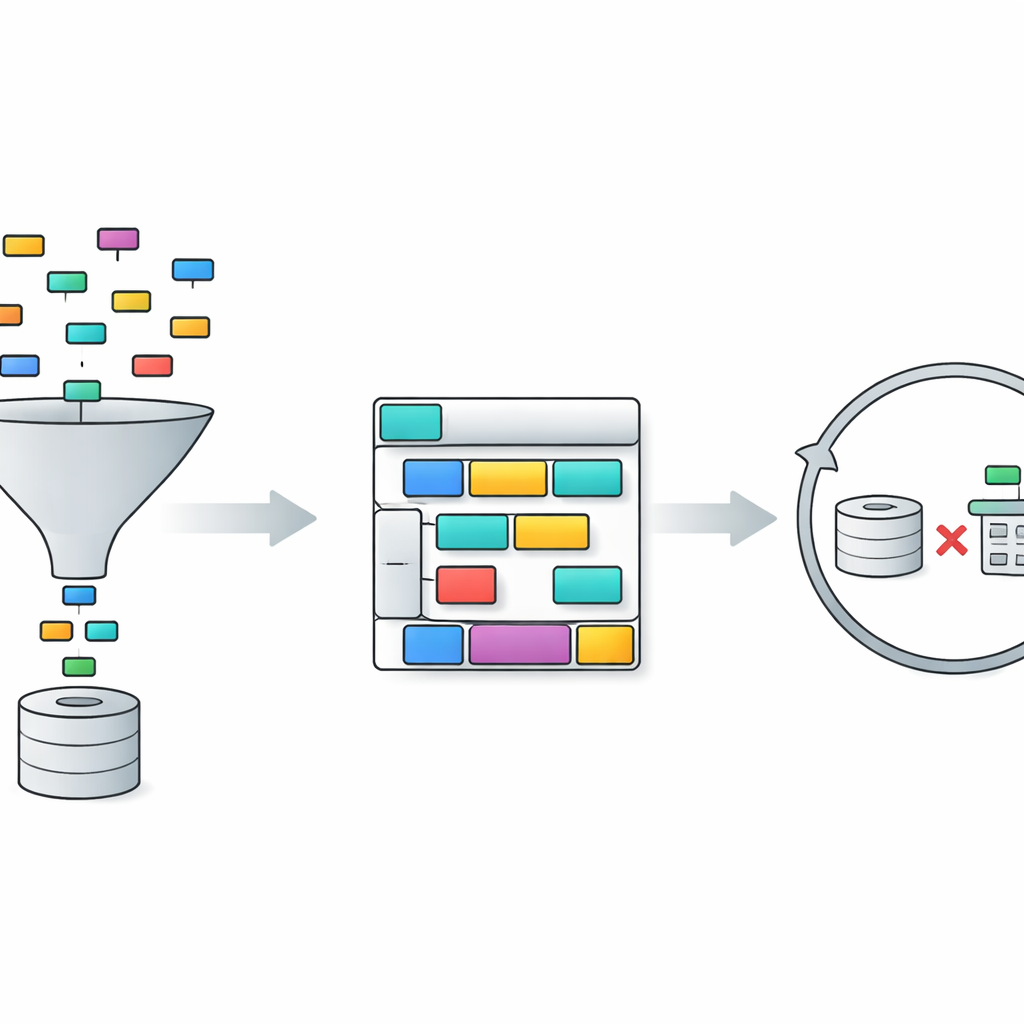
TriSQL begegnet diesen Problemen mit einer dreistufigen Pipeline. Zuerst betrachtet ein fragegeleiteter Selector die Worte des Nutzers und die vollständige Datenbankstruktur und entscheidet, welche Tabellen und Spalten tatsächlich relevant sind. Anstatt das Sprachmodell blind dem gesamten Schema auszusetzen, wird die Sicht auf nur die relevanten Teile eingeschränkt. Zweitens plant ein strukturbewusster Generator die Form der SQL‑Abfrage, bevor er Details ausfüllt. Er skizziert zunächst ein hochrangiges Gerüst — welche Klauseln nötig sind und wie sie zusammenpassen — und setzt dann konkrete Tabellen, Joins und Bedingungen ein. Dieser „erst Struktur, dann Inhalt“-Ansatz hilft, die strenge Grammatik von SQL zu bewahren, besonders bei langen und verschachtelten Abfragen. Schließlich prüft und verbessert ein komplexitätsbewusster Verfeinerer die erste Abfrage und verwendet dabei unterschiedliche Strategien, abhängig davon, wie schwierig die Frage erscheint.
Anpassen des Aufwands an die Schwierigkeit der Frage
Die Verfeinerungsphase ist der Bereich, in dem TriSQL besonders neuartige Nutzung großer Sprachmodelle zeigt. Das System bewertet, wie komplex jede Frage und jeder Entwurf der Abfrage sind, und berücksichtigt dabei Faktoren wie die Anzahl der verbundenen Tabellen, die Tiefe etwaiger Verschachtelungen und die Art der verwendeten Einschränkungen. Für einfache Fälle wendet es nur leichte Korrekturen an, etwa das Beheben kleiner Syntaxfehler. Bei mittleren Fällen reorganisiert es Klauseln und stellt sicher, dass die Abfrage mit dem gewählten Schema übereinstimmt. Bei den anspruchsvollsten Fragen ruft es das Sprachmodell für tiefere Schlussfolgerungen auf, zerlegt die Aufgabe manchmal in Teilaufgaben und führt alternative Abfragen aus. Entscheidend ist, dass TriSQL dann sowohl die ursprüngliche als auch die verfeinerte Abfrage gegen die Datenbank ausführt und ihr Verhalten — ob sie laufen, wie lange sie dauern und was sie zurückliefern — nutzt, um zu entscheiden, welche Version beibehalten werden soll oder ob ein weiterer Verfeinerungsdurchlauf versucht werden soll.
Das System einem Test unterziehen
Um zu prüfen, wie gut TriSQL funktioniert, testen die Autoren es auf einem weithin genutzten Benchmark namens Spider sowie auf mehreren schwierigeren Varianten, die Domänenwissen, ungewöhnliche Satzmuster und realistischere Abfragestrukturen einführen. Sie messen zwei Dinge: exact match, also ob der erzeugte SQL‑String identisch mit einer menschlich geschriebenen Referenz ist, und execution accuracy, also ob er bei Ausführung tatsächlich die richtige Antwort liefert. Über diese Datensätze hinweg erreicht TriSQL die bislang höchste gemeldete Execution‑Accuracy, während es beim Exact‑Match mit den besten vorherigen Systemen konkurriert. Es ist auch robuster: Wenn Fragen von einfach bis extrem schwer reichen, fällt die Leistung von TriSQL deutlich sanfter ab als bei konkurrierenden Methoden. Zusätzliche Experimente auf einem realen Datensatz zur Steuerung von Stromnetzen zeigen, dass dasselbe Framework nicht nur Datenabruf, sondern auch Insert-, Update-, Delete‑ und Tabellen‑Erstellungsbefehle verarbeiten kann. Pilot‑Anpassungen an Graphdatenbanken (Cypher) und MongoDB‑Pipelines deuten darauf hin, dass das dreistufige Design über klassisches SQL hinaus erweitert werden kann.
Was das für die alltägliche Datennutzung bedeutet
Kurz gesagt bringt uns diese Arbeit näher an eine Welt, in der Menschen mit komplexen Datenbanken so mühelos sprechen können, wie sie heute mit Suchmaschinen chatten. Indem sie sorgfältig auswählt, welche Teile der Datenbank berücksichtigt werden, indem sie die Struktur einer Abfrage plant, bevor die Details ausgefüllt werden, und indem sie die Nutzung großer Sprachmodelle an die Schwierigkeit jeder Frage anpasst, erzeugt TriSQL Abfragen, die mit höherer Wahrscheinlichkeit korrekt ausgeführt werden und die beabsichtigten Ergebnisse liefern. Zwar bleiben Herausforderungen — etwa der Umgang mit mehrdeutigen Fragen und unbekannten Datenbanken — bestehen, doch die Studie zeigt, dass ein durchdachtes, gestuftes Design natürliche Sprachschnittstellen zu Daten sowohl leistungsfähiger als auch vorhersagbarer für Alltagsnutzer machen kann.
Zitation: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Schlüsselwörter: text‑zu‑SQL, Schnittstellen in natürlicher Sprache, Datenbankabfragen, große Sprachmodelle, Abfrage‑Robustheit