Clear Sky Science · de
Ein Ansatz zum Umgang mit unausgewogenen Datensätzen durch Verschiebung der Grenze
Warum seltene Fälle in alltäglichen Daten wichtig sind
Von Bankenbetrug und medizinischen Diagnosen bis zur Vorhersage von Kundenabwanderung hängen viele Entscheidungen, die wir Computern überlassen, davon ab, seltene, aber entscheidende Ereignisse zu erkennen. In den meisten realen Datensätzen sind diese wichtigen Fälle zahlenmäßig von normalen Fällen weit übertroffen. Ein Modell, das überwiegend "Business as usual" sieht, kann gegenüber genau den Situationen blind werden, die uns am meisten interessieren. Dieses Papier stellt eine neue Methode vor, um solche schiefen Daten neu auszubalancieren, damit Lernalgorithmen den seltenen, hochwirksamen Fällen angemessene Aufmerksamkeit schenken.
Die verborgene Falle schief verteilter Daten
Wenn eine Art von Beispielen eine andere deutlich übertrifft, neigen Standardmethoden des maschinellen Lernens dazu, sich auf die Mehrheitsklasse zu konzentrieren und die Minderheit stillschweigend zu vernachlässigen. Ein System zur Vorhersage von Abwanderung könnte zum Beispiel fast alle als loyale Kunden einordnen und trotzdem eine hohe Genauigkeit ausweisen, einfach weil tatsächliche Abwanderer so selten sind. Ähnliche Probleme treten bei Unfallerkennung, Betrugsüberwachung und medizinischem Screening auf, wo positive Fälle rar, aber teuer zu übersehen sind. Traditionelle Lösungsansätze fallen in zwei Kategorien: den Lernalgorithmus so anpassen, dass er der Minderheit mehr "Beachtung" schenkt, oder die Daten selbst umgestalten, indem man einige Mehrheitsfälle entfernt (Undersampling) oder zusätzliche Minderheitsfälle erzeugt (Oversampling). Beliebte Oversampling‑Verfahren wie SMOTE erzeugen synthetische Minderheitsbeispiele, können jedoch unbeabsichtigt die empfindliche Randregion überfrachten, in der sich die beiden Klassen treffen.
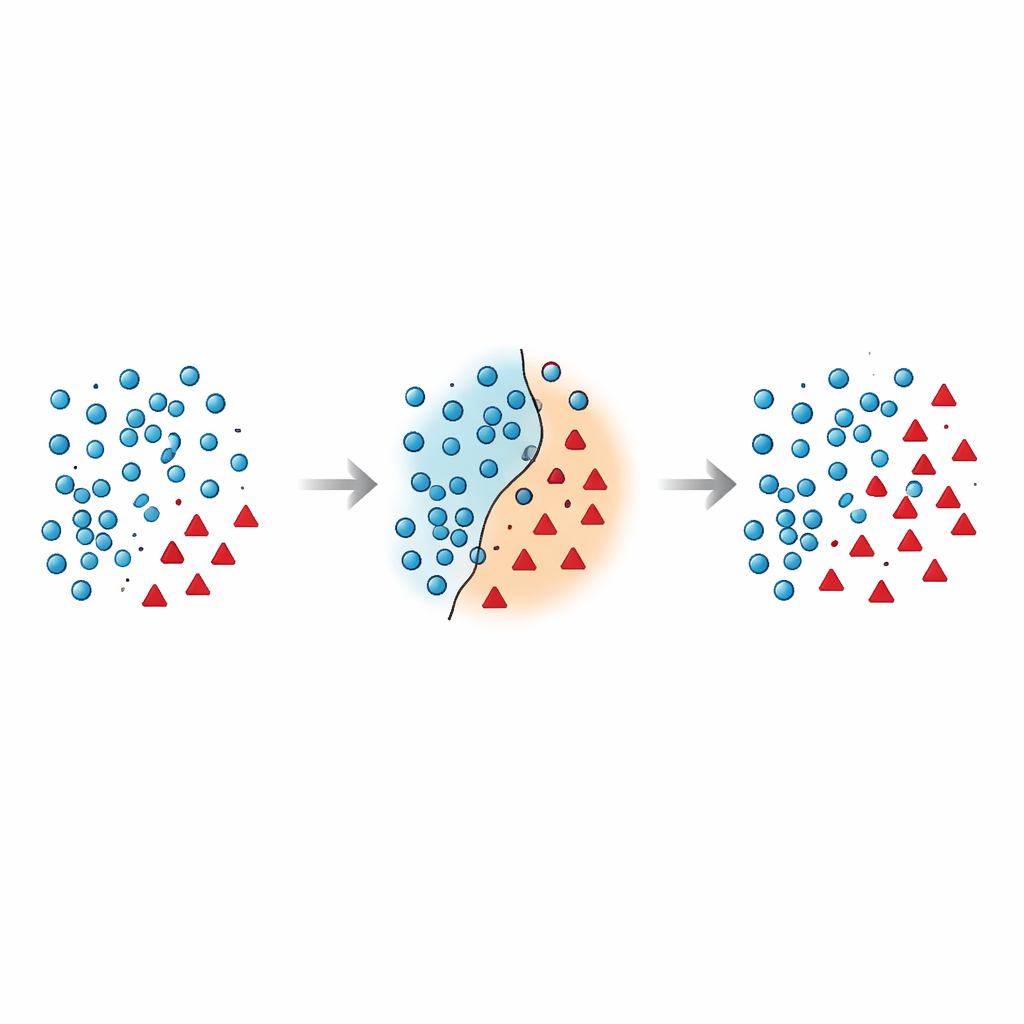
Warum die Grenze zwischen Gruppen so zerbrechlich ist
Die Autoren argumentieren, dass die gefährlichsten Fehler in der Nähe der Entscheidungsgrenze passieren – der Zone, in der Mehrheits‑ und Minderheitsfälle im Merkmalsraum überlappen. Viele bestehende Techniken fügen entweder synthetische Punkte in diese riskante Region ein, ohne sie zu bereinigen, oder sie löschen Daten aggressiv und entfernen dadurch versehentlich informative Beispiele. Jüngere Forschung versucht, dies mit geometrischen Einschränkungen, lokalen Dichteschätzungen oder Rauschfiltern zu zähmen, doch die meisten Methoden behandeln Minderheitspunkte an Ort und Stelle und überdenken selten, wie Mehrheitspunkte in Grenznähe gehandhabt werden sollten. Dadurch bleibt ein hartnäckiges Problem bestehen: überlappende und verrauschte Stichproben, die den Klassifikator verwirren und zu instabilen Vorhersagen führen, insbesondere bei neuen Daten.
Ein zweistufiges Verfahren zur Bereinigung der Grenze
Das Papier stellt Borderline Shifting Oversampling (BSO) vor, ein zweiphasiges Verfahren zur Umgestaltung der Daten, das explizit diese problematische Randregion ins Visier nimmt. Zuerst untersucht es die Nachbarschaft jedes Mehrheitsbeispiels, um zu entscheiden, ob es in einer sicheren Zone, an der Grenze oder an einem eindeutig falschen Ort (Rauschen) liegt. Mehrheitspunkte, die von Minderheitsnachbarn umgeben sind, werden entweder zugunsten der Minderheit umklassifiziert oder als Rauschen markiert und entfernt, wodurch die Grenze effektiv gereinigt und verschoben wird, sodass sie das zugrunde liegende Muster besser widerspiegelt. In der zweiten Phase erzeugt die Methode neue synthetische Minderheitspunkte mittels einer SMOTE‑ähnlichen Interpolation, jedoch nur in der Umgebung der Minderheitsstichproben nahe der verfeinerten Grenze. Indem neue Daten dort konzentriert werden, wo sie am informativsten sind, und offensichtlich verrauschte Stellen vermieden werden, baut BSO einen Trainingssatz auf, der sowohl in der Größe besser ausbalanciert als auch in der Struktur sauberer ist.
Wie die Methode im Test abschneidet
Um die praktische Wirksamkeit zu prüfen, bewerteten die Forschenden BSO an 30 Benchmark‑Datensätzen mit unterschiedlichen Graden von Ungleichgewicht und Überlappung. Sie verglichen es mit sieben weit verbreiteten Alternativen, darunter zufälliges Über‑ und Unterabtasten, SMOTE, Borderline‑SMOTE, NearMiss und zwei Hybridverfahren, die Oversampling mit Rauschbereinigung kombinieren (SMOTE‑Tomek und SMOTE‑ENN). Drei gängige Klassifikatoren – Support Vector Machines, Naive Bayes und Random Forests – wurden auf jedem neu bemusterten Datensatz trainiert. Anstelle der reinen Genauigkeit nutzte die Studie Metriken, die bei Ungleichgewicht aussagekräftiger sind, wie F1‑Score, G‑Mean, Recall, Precision und die Fläche unter der ROC‑Kurve (AUC). Über nahezu alle Datensätze und Klassifikatoren hinweg lieferte BSO höhere oder vergleichbare Werte bei geringerer Streuung, was bedeutet, dass seine Vorteile konsistent waren und nicht an ein bestimmtes Modell oder eine bestimmte Einstellung gebunden sind.
Was das für Entscheidungen in der Praxis bedeutet
Alltäglich gesprochen wirkt der Borderline Shifting‑Ansatz wie ein sorgfältiger Redakteur für unordentliche Daten: Er räumt verwirrende Beispiele in der Nähe der Trennlinie zwischen den Klassen auf und fügt dann genau genügend realistische Minderheitsfälle an den richtigen Stellen hinzu. Das Ergebnis ist, dass Lernalgorithmen seltener, aber wichtige Ereignisse besser erkennen, ohne durch verrauschte Überlappungen in die Irre geführt zu werden. Für Anwendungen wie Betrugserkennung, Unfallvorhersage oder medizinische Triage — wo das Übersehen eines Minderheitsfalls teuer sein kann — bietet diese Methode einen praktischen Weg, Modelle fairer, sensibler und verlässlicher zu machen, bei nur moderatem zusätzlichem Rechenaufwand.
Zitation: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Schlüsselwörter: Klassenungleichgewicht, Oversampling, Entscheidungsgrenze, Anomalieerkennung, Robustheit von maschinellem Lernen