Clear Sky Science · de
Eine Methode zur Zusammenstellung geographischer Objekte in Satellitenbildkarten auf Basis von Vektorkartendaten mittels Deep Learning
Warum es wichtig ist, was Karten zeigen
Online-Karten wirken oft wie Fenster zur realen Welt, doch das, was Sie von oben sehen, ist sorgfältig gestaltet. Satellitenbildkarten sind wertvoll, weil sie wie reale Orte aussehen; manchmal müssen wir jedoch sensible Einrichtungen verbergen, überladene Szenen bereinigen oder sicherstellen, dass verschiedene Kartentypen zueinander passen. Dieses Papier stellt einen neuen Weg vor, Satellitenbilder mithilfe künstlicher Intelligenz automatisch zu „bearbeiten“, sodass Gebäude und Straßen entfernt, hinzugefügt, verschoben oder umgeformt werden können, während das Bild weiterhin natürlich und überzeugend wirkt. 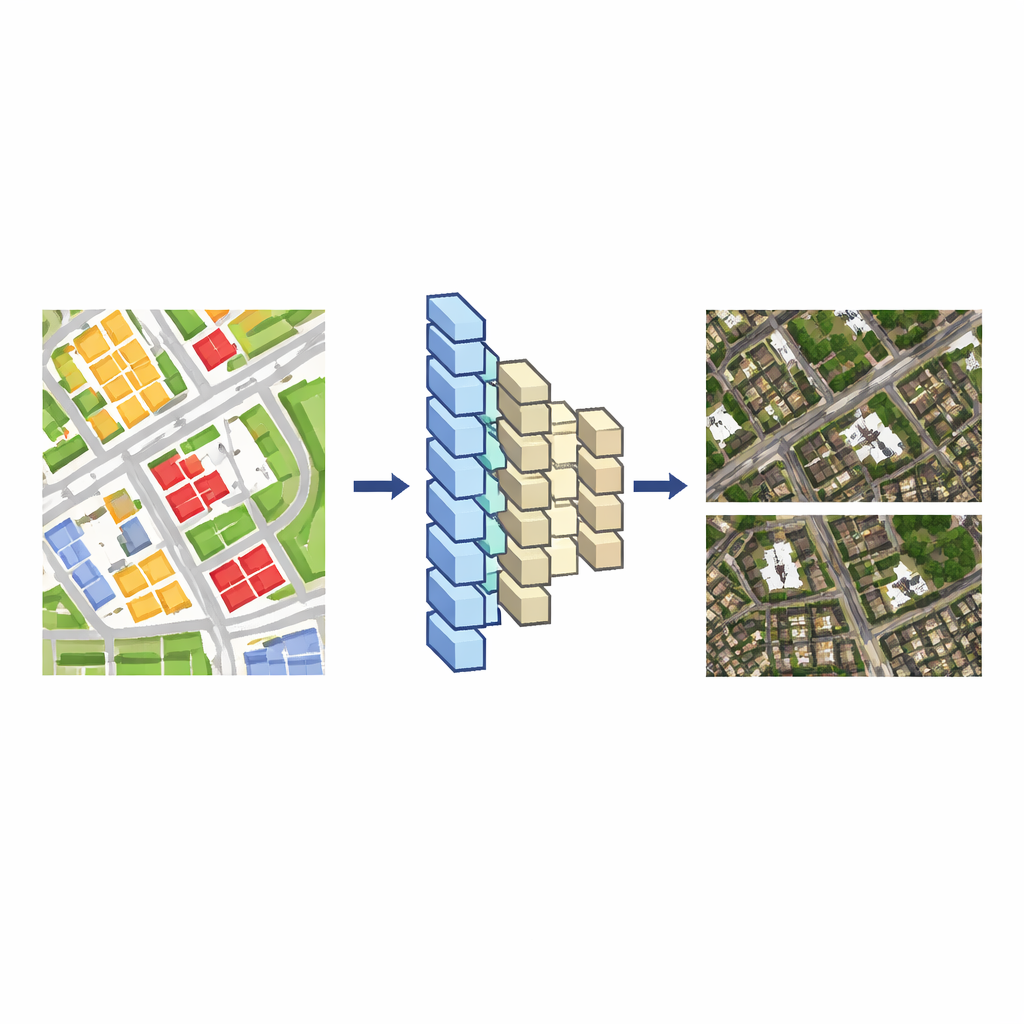
Von einfachen Zeichnungen zu realistischen Ansichten
Moderne Kartensysteme speichern meist zwei Arten geographischer Daten. Die eine ist das Satellitenbild selbst, ein dichtes Mosaik von Pixeln. Die andere ist eine Vektorkarte, eine sauberere Zeichnung aus Linien und Flächen, die Straßen, Gebäude, Flüsse und mehr markieren. Die Vektorkarte zu bearbeiten ist vergleichsweise einfach, aber das passende Satellitenbild per Hand zu ändern ist langsam und mühsam, weil die Pixel eines jeden Gebäudes in Schatten, Bäume und benachbarte Strukturen übergehen. Die zentrale Idee der Autoren ist, ein Deep-Learning-Modell zu lehren, diese Vektorzeichnungen in realistische Satellitenbilder zu übersetzen. Hat das Modell diese Verbindung erlernt, kann jede Änderung an der Vektorkarte automatisch in eine konsistente Änderung der Satellitenansicht umgesetzt werden.
Ein KI beibringen, sich Städte vorzustellen
Um diesen Übersetzer zu bauen, beginnen die Forschenden mit Gebieten, in denen eine Vektorkarte und ein Satellitenbild dieselbe Region in ähnlichem Maßstab abdecken. Sie teilen beides in viele kleine Kacheln, paaren jede Vektorkachel mit ihrer entsprechenden Bildkachel und nutzen diese Paare als Trainingsdaten. Ein Encoder–Decoder-Neuronales Netz – ähnlich den Werkzeugen, die für Bild-zu-Bild-Übersetzungen verwendet werden – lernt, wie die Anordnung farbiger Blöcke und Linien in der Vektorkachel mit Dächern, Straßen und Vegetation in der Satellitenkachel zusammenhängt. Sie vergleichen zwei verbreitete Netzwerkarchitekturen, UNet++ und Pix2Pix, und stellen fest, dass Pix2Pix satellitenähnliche Bilder erzeugt, die der Realität näherkommen und sich zuverlässig trainieren lassen; deshalb wird es ihr Basismodell.
Das Modell auf zu ändernde Orte fokussieren
Allein aus der ganzen Stadt zu lernen reicht nicht, wenn man bestimmte Objekte sauber anpassen möchte. Um die Fertigkeit des Modells in Zielbereichen zu schärfen, nutzen die Autoren Transfer Learning. Sie extrahieren zusätzliche Trainingskacheln, die die Gebäude oder Straßen umgeben, die sie bearbeiten wollen, und führen eine kurze zusätzliche Trainingsphase nur mit diesen lokalen Beispielen durch. Dieser Feinabstimmungsschritt verbessert deutlich, wie gut das Modell jene Nachbarschaften reproduziert, wodurch spätere Änderungen schärfer und präziser aussehen. 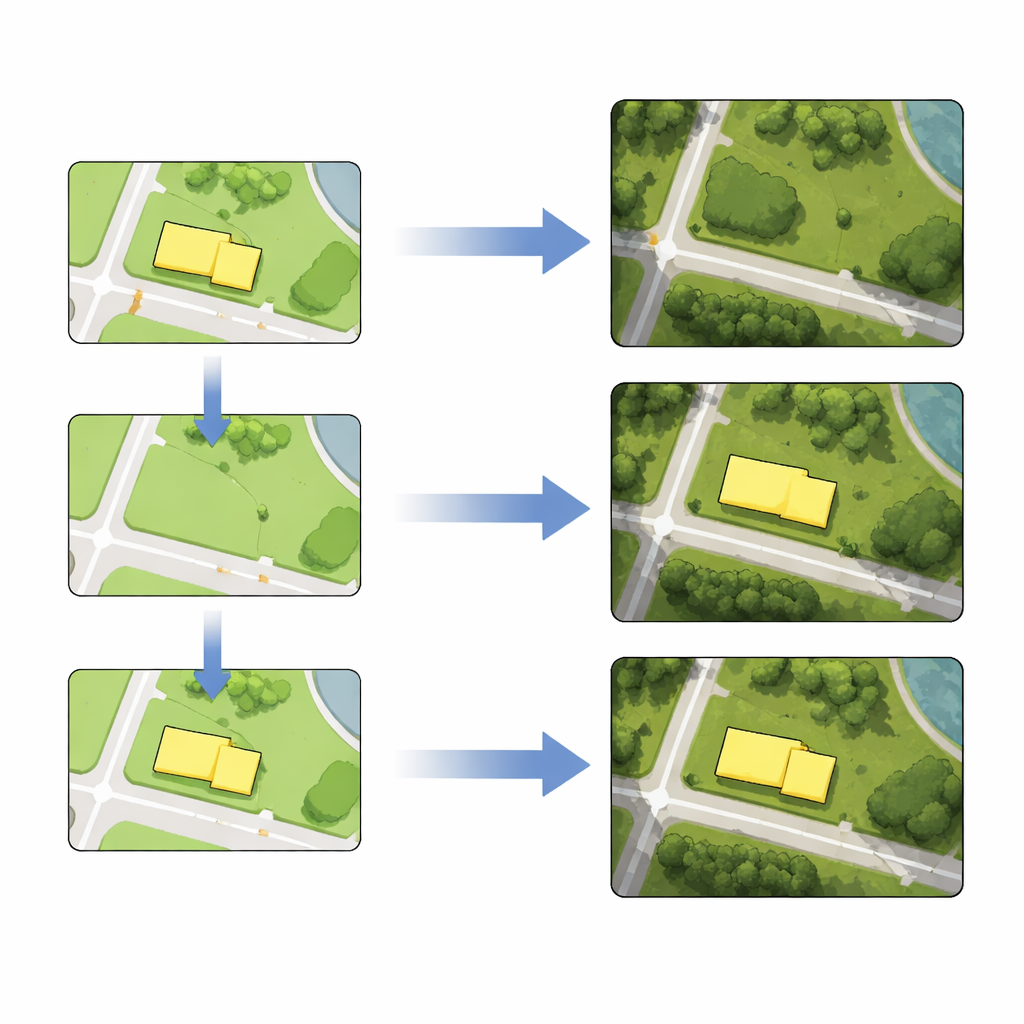
Gebäude und Straßen wie Kartenebenen bearbeiten
Mit dem feinabgestimmten Modell wird das Zusammenstellen von Satellitenbildkarten zu einem Dreischritt-Rezept. Zuerst bearbeitet eine Kartografin oder ein Kartograf die Vektorkarte: ein Gebäude löschen, eine neue Straße zeichnen, einen Block umformen oder ein Objekt an eine neue Position verschieben. Zweitens werden die bearbeiteten Vektorkacheln in das trainierte Netzwerk gespeist, das neue Satellitenkacheln generiert, die die beabsichtigte Änderung widerspiegeln und gleichzeitig Umgebung und Textur bewahren. Drittens ersetzen diese generierten Kacheln die ursprünglichen Bildkacheln. Anhand realer Daten aus Berlin demonstrieren die Autorinnen und Autoren alle vier Operationen – Löschung, Einfügung, Verzerrung und Verschiebung – sowohl für Gebäudegrundrisse als auch für Straßenlinien, einzeln oder in Chargen. Messungen zeigen, dass die Positionen bearbeiteter Objekte in den generierten Bildern nur um wenige Pixel von ihren Vektor-Pendants abweichen, eine Genauigkeit, die für viele Kartierungsaufgaben akzeptabel ist.
Was das für künftige Karten bedeutet
Einfach gesagt zeigt die Studie, dass, sobald eine KI gelernt hat, wie Vektorkarten und Satellitenbilder korrespondieren, man die einfache Zeichnung bearbeiten und das Modell die glaubwürdige Luftansicht passend nachmalen lassen kann. Das eröffnet die Möglichkeit maßgeschneiderter Satellitenbildkarten: sensible Orte zu verbergen, komplexe Szenen zu klären oder reale und imaginierte Räume wie Spielwelten und virtuelle Umgebungen zu verschmelzen. Gleichzeitig macht es auf die Macht – und das Risiko – der „Deepfake“-Geografie aufmerksam, in der realistisch wirkende Luftbilder nicht mehr zwangsläufig echte Fotografien der Welt sind.
Zitation: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
Schlüsselwörter: Satellitenbilder, Deep Learning, Kartenbearbeitung, Fernerkundung, Deepfake-Kartographie