Clear Sky Science · de
DeCon-Net: entkoppelte hierarchische Kontrastierung für die Objekterkennung im Fußball
Warum das Erkennen von Spielern und Ball schwieriger ist, als es scheint
Moderne Fußballübertragungen sind voll von Grafiken, Statistiken und Zeitlupen, die alle von Computersystemen gesteuert werden, die zunächst eine täuschend einfache Frage beantworten müssen: Wo sind in jedem Bild die Spieler und der Ball? Dieses Paper untersucht, warum führende KI‑Werkzeuge bei dieser Grundaufgabe in echten Spielen noch Probleme haben — und stellt eine neue Methode vor, DeCon‑Net, die die automatische Erkennung von Spielern und Ball deutlich zuverlässiger macht, insbesondere in unordentlichen, dicht gedrängten Szenen.
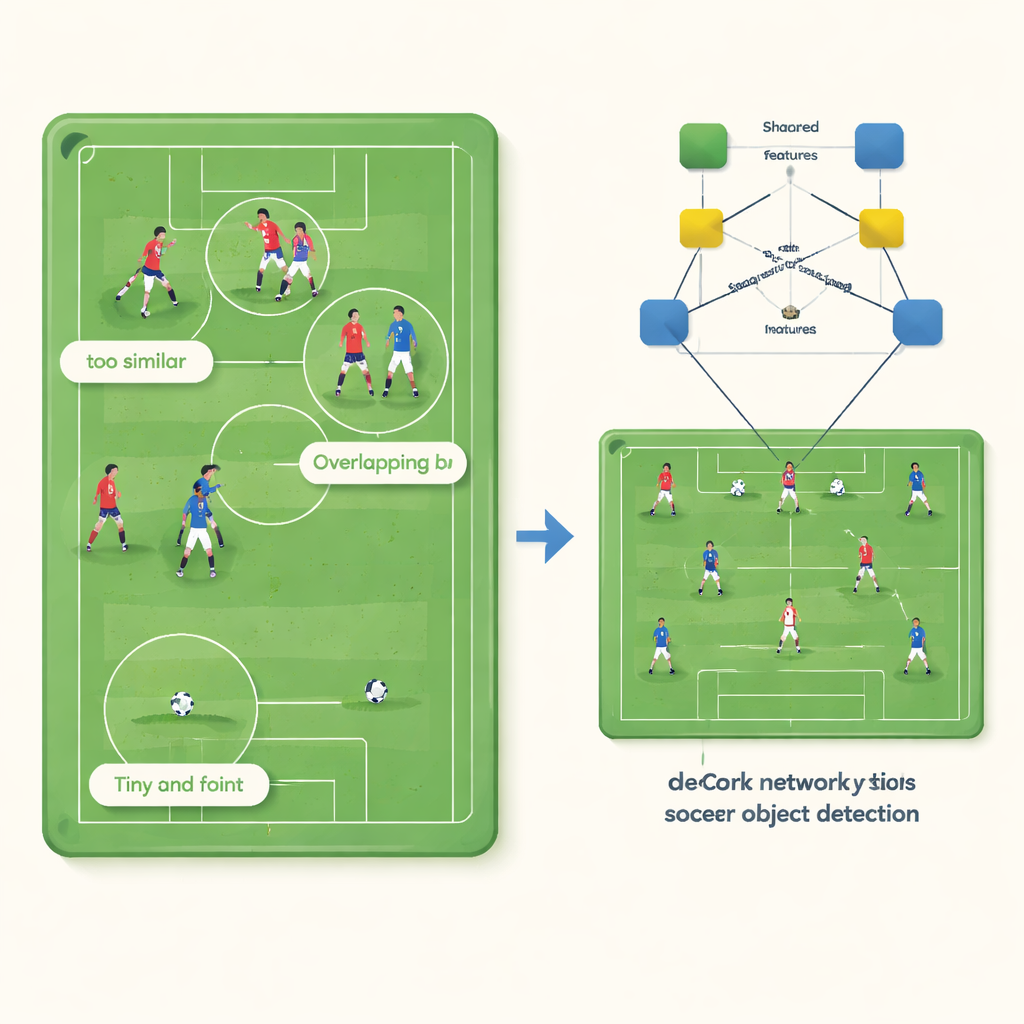
Drei versteckte Probleme in Fußballvideos
Auf den ersten Blick erscheint die Erkennung von Spielern und Ball einfach: Sie bewegen sich, haben erkennbare Formen und heben sich vom Spielfeld ab. Die Autoren zeigen jedoch, dass Standard‑Computer‑Vision‑Systeme unter drei miteinander verwobenen Problemen leiden. Erstens werden Teamkollegen mit identischen Trikots für den Algorithmus nahezu ununterscheidbar, weil ihre internen „Feature“-Beschreibungen zu fast identischen Punkten kollabieren. Zweitens zeichnen Detektoren in engen Zweikämpfen oft eine große Bounding‑Box um mehrere Personen statt einzelne Boxen für jede Person, weil Spieler sich stark überlappen. Drittens ist der Ball winzig — manchmal nur wenige Dutzend Pixel — und sein visuelles Signal ist so schwach, dass es von Grastextur und Spielerbewegung übertönt werden kann, wodurch das System ihn leicht übersieht.
Das Netzwerk lernen lassen, Dinge zu trennen
DeCon‑Net begegnet diesen Problemen, indem es verändert, wie ein neuronales Netzwerk das Gesehene in einem Bild darstellt. Anstatt dem Modell zu erlauben, für jedes Objekt eine vermischte Beschreibung zu lernen, teilen die Autoren diese Beschreibung in zwei komplementäre Teile auf. Ein Zweig erfasst, was Spieler desselben Teams gemeinsam haben — etwa Trikotfarbe —, während der andere Zweig sich auf das konzentriert, was jede einzelne Person einzigartig macht, wie Körperpose oder genaue Position. Ein spezieller Trainingstrick kehrt das Gradientensignal für den „individuellen“ Zweig um, wann immer das Netzwerk versucht, Team‑Informationen dort zu nutzen; dadurch lernt er, Trikotfarbe zu ignorieren und sich auf personenspezifische Hinweise zu konzentrieren. Die beiden Zweige werden dann adaptiv wieder zusammengeführt, sodass das System in einfachen Szenen stärker auf gemeinsame Merkmale und in dichten Szenen stärker auf individuelle Merkmale setzt.
Das Modell über Vergleiche lehren, nicht nur über Labels
Über diese geteilte Repräsentation hinaus verändert DeCon‑Net das Lernen selbst. Die Methode fügt einen hierarchischen „kontrastiven“ Trainingsschritt hinzu, der ständig Paare erkannter Objekte vergleicht. Paare, die bereits eindeutig verschieden sind, erhalten nur leichte Anpassungen, während Paare, die verwirrend ähnlich aussehen — etwa zwei nebeneinander stehende Teamkollegen — aggressiver trainiert werden, um sich im internen Raum des Netzwerks auseinanderzubewegen. Diese dreistufige Strategie beginnt mit einfachen Unterscheidungen, geht dann zu subtileren Unterschieden innerhalb eines Teams über und betrachtet schließlich Variationen zwischen verschiedenen Spielen und Übertragungsbedingungen. Um den winzigen Ball davor zu bewahren, übersehen zu werden, verstärkt die Methode außerdem den Einfluss sehr kleiner Objekte während des Trainings, sodass das Signal des Balls heraussticht, statt im Hintergrundrauschen zu verschwinden.
Von Laborbenchmarks zu echten Sportübertragungen
Die Forschenden testeten DeCon‑Net auf zwei anspruchsvollen Datensätzen: SportsMOT, das Fußball, Basketball und Volleyball umfasst, und SoccerNet‑Tracking, das aus echten TV‑Übertragungen mit Kamerazooms, Bewegungsunschärfe und häufigen Verdeckungen erstellt wurde. Über alle Tests hinweg erkannte DeCon‑Net Spieler und Ball genauer als weit verbreitete Systeme auf Basis von Faster R‑CNN, DETR und jüngeren tracking‑orientierten Methoden. Besonders beeindruckend waren die Verbesserungen beim Ball, dessen Erkennungsgenauigkeit im Vergleich zu starken Baselines um mehr als 40 Prozent anstieg. Das System hielt sich außerdem besser, wenn es auf einen anderen Datensatz angewendet wurde als den, auf dem es trainiert wurde, was darauf hindeutet, dass das geteilte Feature‑Design allgemeinere, wiederverwendbare Hinweise zu Spielszenen erfasst.
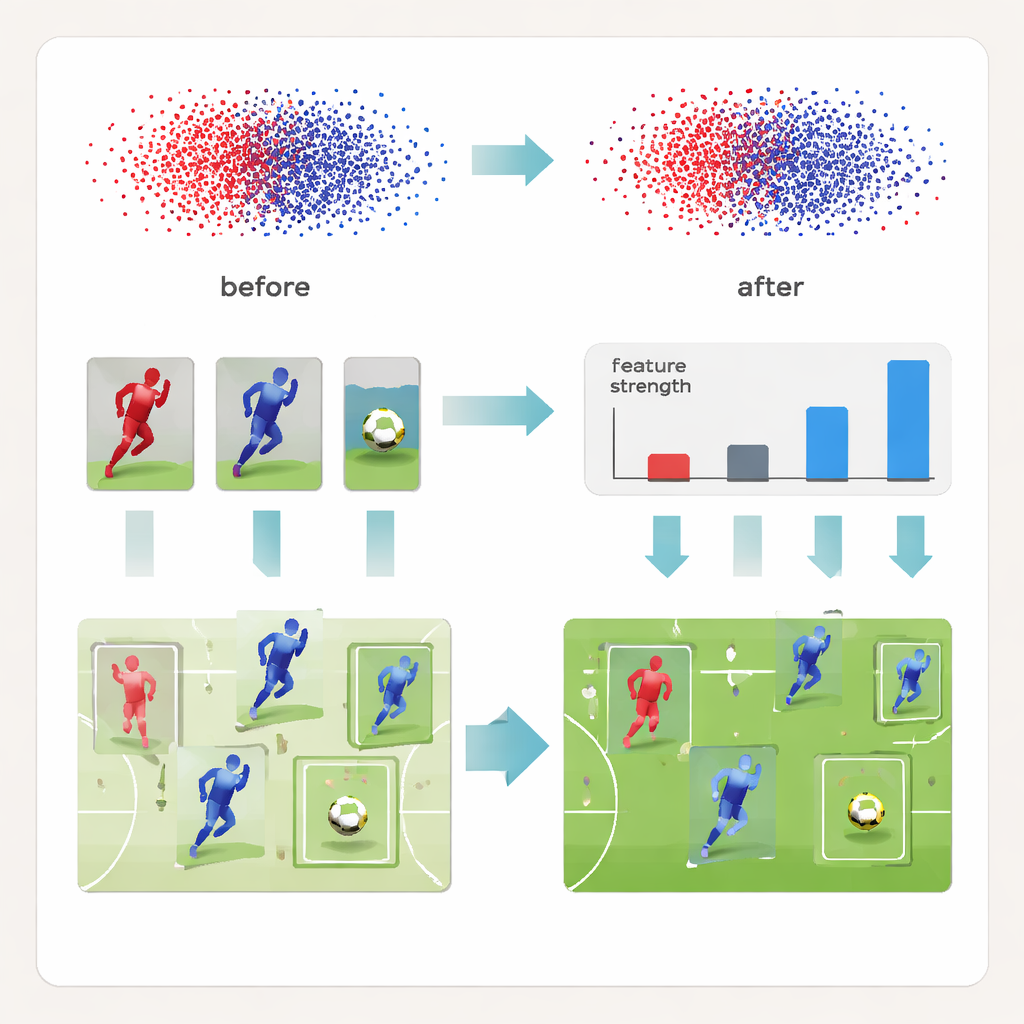
Was das für die Zukunft der Sportanalyse bedeutet
Einfach gesagt zeigt das Paper, dass viele aktuelle KI‑Systeme Fußball zu vereinfacht „sehen“: Sie fassen Mannschaftskameraden zusammen und ignorieren den Ball fast, wenn die Szene hektisch wird. DeCon‑Net setzt dem entgegen, indem es das Netzwerk zwingt, getrennt zu lernen, wer zu welchem Team gehört und wer welche individuelle Person ist, und gleichzeitig winzigen, leicht zu übersehenden Objekten mehr Aufmerksamkeit schenkt. Das Ergebnis ist eine präzisere, zuverlässigere Karte jedes Spielers und des Balls auf dem Feld, Bild für Bild. Diese Grundlage kann bessere taktische Analysen für Trainer, reichere Grafiken für Sender und genauere Statistiken für Fans ermöglichen und uns einem wirklich intelligenten, automatisierten Verständnis des Spiels näherbringen.
Zitation: Ouyang, Q., Du, T. & Li, Q. DeCon-Net: decoupled hierarchical contrast for soccer object detection. Sci Rep 16, 7571 (2026). https://doi.org/10.1038/s41598-026-39084-4
Schlüsselwörter: Fußball-Videoanalyse, Objekterkennung, Sportanalyse, Computer Vision, Ballverfolgung