Clear Sky Science · de
SwinCup-DiscNet: Ein Fusion-Transformer-Rahmen für die Glaukomdiagnose unter Verwendung von Papillen- und Tassenmerkmalen
Warum das wichtig ist, um Sehen zu erhalten
Glaukom ist eine der weltweit führenden Ursachen für irreversible Erblindung, verläuft aber oft schleichend, ohne Schmerz oder frühe Warnzeichen. Augenärzte können subtile Veränderungen im hinteren Augenbereich erkennen, bevor das Sehvermögen verloren geht, doch die manuelle Überprüfung aller Patienten ist langsam und gelegentlich inkonsistent. Diese Arbeit stellt SwinCup-DiscNet vor, ein neues System der künstlichen Intelligenz (KI), das Netzhautfotos auswertet, um Glaukom frühzeitig zu erkennen, und dabei klassische klinische Hinweise mit modernen Methoden des tiefen Lernens kombiniert. 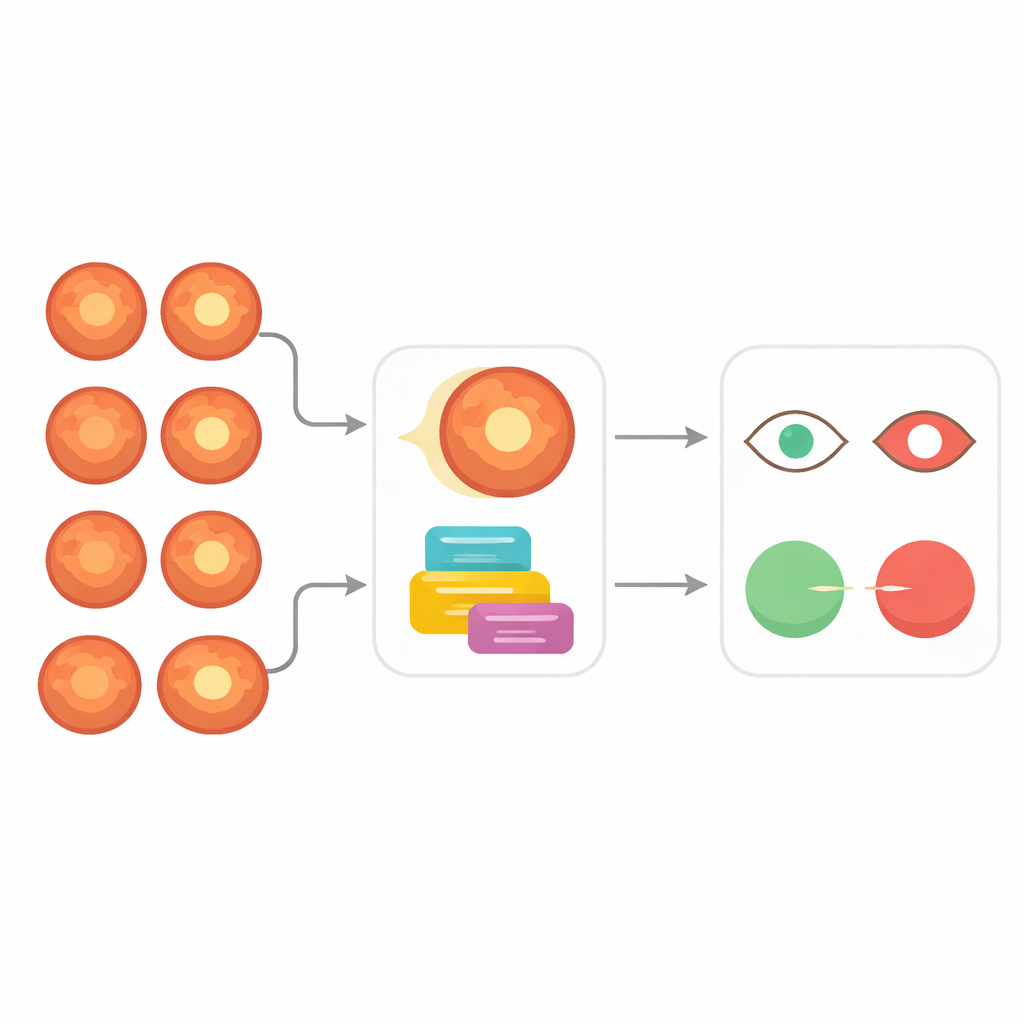
Ein Blick auf den Sehnerv im Auge
Um zu verstehen, was das System leistet, ist es hilfreich zu wissen, wie Glaukom üblicherweise entdeckt wird. Augenfachärzte untersuchen den Sehnervkopf, die Stelle, an der der das Sehvermögen leitende Nerv das Auge verlässt. In der Mitte dieser „Papille“ liegt eine hellere Vertiefung, die „Tasse“ genannt wird. Mit Fortschreiten des Glaukoms neigt die Tasse dazu, tiefer und breiter zu werden und den umliegenden Nervenrand aufzuzehren. Eine zentrale Kennzahl ist das Tassen-zu-Papillen-Verhältnis, das die Größe der Tasse mit der Größe der Papille vergleicht. Ein höheres Verhältnis weist häufig auf Schäden hin. Diese Kennzahl händisch auf Tausenden von Netzhautbildern zu messen ist mühsam, und selbst Experten können zu unterschiedlichen Bewertungen kommen. SwinCup-DiscNet automatisiert sowohl die Messung dieses Verhältnisses als auch die Gesamtbeurteilung, ob ein Auge wahrscheinlich ein Glaukom aufweist.
Eine zweigleisige KI, die Details und das große Ganze sieht
Das System folgt zwei parallelen Pfaden, wenn es ein Fundusbild der Netzhaut erhält. Zuerst isoliert ein Segmentierungszweig die Papille und die zentrale Tasse. Er nutzt ein spezialisiertes Netzwerk, bekannt als Attention U-Net, das lernt, die wichtigen Strukturen hervorzuheben und ablenkende Hintergrundmerkmale wie Blutgefäße und Beleuchtungsartefakte zu ignorieren. Sobald die Tassen- und Papillengrenzen identifiziert sind, glättet das System sie, legt saubere ovale Formen an und misst dann ihre vertikalen Ausmaße, um das vertikale Tassen-zu-Papillen-Verhältnis zu berechnen — ein klinisch vertrauter Marker für Glaukom.
Muster lernen, die über messbare Werte hinausgehen
Im zweiten Pfad betrachtet ein transformerbasierter Ast das gesamte Bild, ohne sich auf eine einzelne Kennzahl zu fokussieren. Dieser Zweig verwendet einen Swin Transformer, ein modernes tiefes Lernmodell, das das Bild in kleine Patches unterteilt und analysiert, wie diese über die gesamte Netzhaut hinweg zueinander in Beziehung stehen. Dabei erkennt es subtile Muster in Textur, Farbe und Struktur rund um den Sehnerv und angrenzende Regionen, die mit Glaukom in Verbindung stehen könnten, aber für Menschen schwer zu quantifizieren sind. Aus dieser globalen Sicht liefert das Modell eine Wahrscheinlichkeit dafür, dass das Bild von einer Person mit Glaukom stammt. 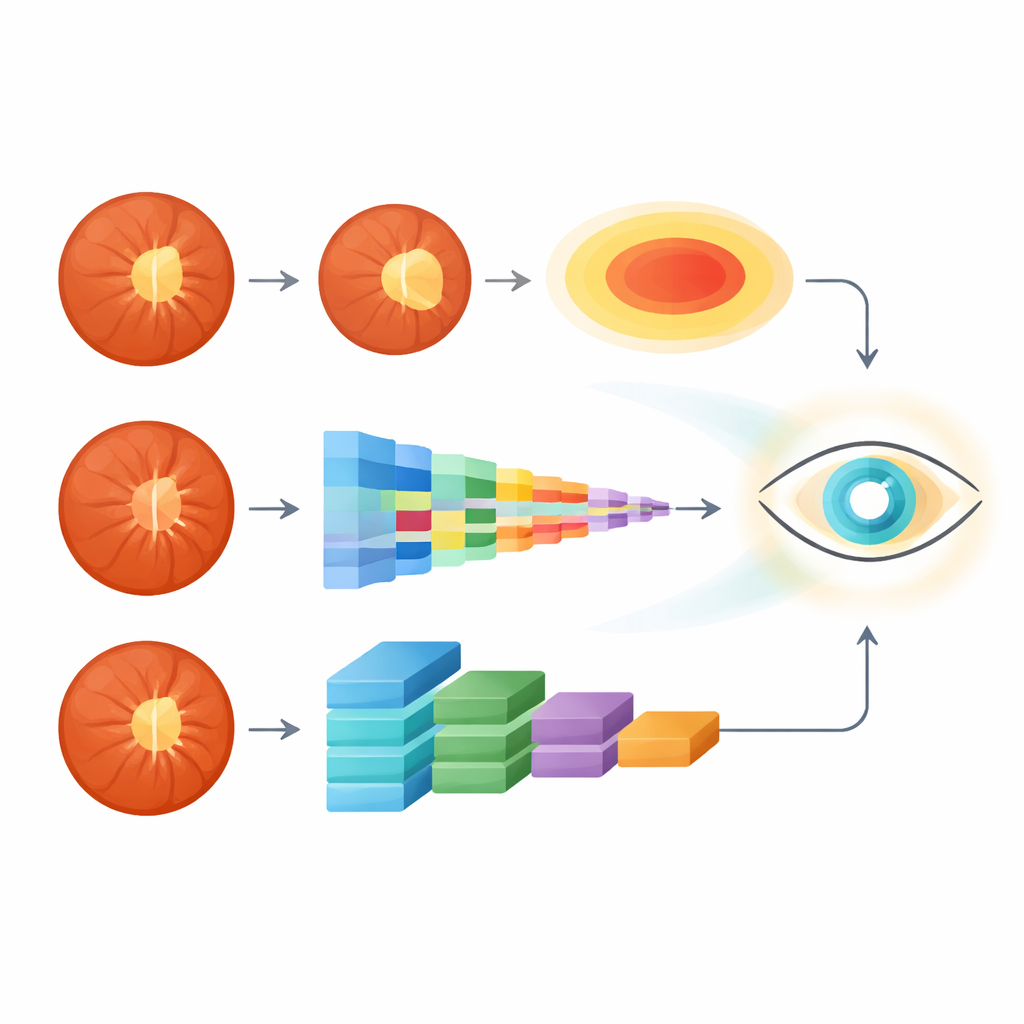
Vertrauenswürdige Hinweise mit KI-Intuition verbinden
Der Kern von SwinCup-DiscNet ist, wie es diese beiden Informationsquellen zusammenführt. Anstatt allein dem Tassen-zu-Papillen-Verhältnis oder nur der Wahrscheinlichkeit des Transformers zu vertrauen, verbindet das System beides mittels einer gewichteten Regel. Das Tassen-zu-Papillen-Verhältnis wird basierend auf seinem Verhalten in den Trainingsdaten normalisiert und dann mit der vom Modell gelernten Glaukom-Wahrscheinlichkeit zu einem einzigen Score kombiniert. Überschreitet dieser verschmolzene Score eine Schwelle, wird das Auge als glaukomatös klassifiziert; andernfalls wird es als normal eingestuft. Dieses Design verankert die Entscheidung in einer vertrauten klinischen Messgröße, nutzt aber gleichzeitig die reichhaltigeren Muster, die die KI erkennen kann. Das System überlagert außerdem die angepassten Papillen- und Tassenkonturen mit dem Originalbild, sodass Ärztinnen und Ärzten klar ersichtlich ist, welcher Bereich die Entscheidung beeinflusst hat.
Die Methode auf die Probe gestellt
Die Autoren bewerteten SwinCup-DiscNet an drei weit verbreiteten öffentlichen Datensätzen mit Netzhautbildern: LAG, ACRIMA und DRISHTI-GS. Diese Kollektionen unterscheiden sich in Kameratyp, Bildqualität und Patientenmix, was sie zu einer anspruchsvollen Testumgebung macht. In allen Datensätzen erreichte das neue System mindestens vergleichbare oder bessere Ergebnisse als traditionelle konvolutionale Netze und Methoden, die nur Tasse und Papille segmentieren. Es erzielte sehr hohe Segmentierungsqualität, geringe Fehler bei der Schätzung des Tassen-zu-Papillen-Verhältnisses und Klassifikationsgenauigkeiten nahe oder über 99 Prozent, mit starken Leistungskennlinien, die darauf hindeuten, dass gesunde und erkrankte Augen selten verwechselt werden. Eine Fehleranalyse zeigte, dass die meisten verbleibenden Fehlalarme Grenzfälle betrafen, bei denen die optische Tasse von Natur aus groß, aber nicht wirklich krankhaft war — ein Kompromiss, der im Screening oft akzeptabel ist.
Was das für zukünftige Augen-Screenings bedeutet
Kurz gesagt zeigt SwinCup-DiscNet, dass KI sowohl "wie ein Arzt denken" kann, indem sie etablierte Marker wie das Tassen-zu-Papillen-Verhältnis nutzt, als auch "über das Offensichtliche hinaussehen" kann, indem sie komplexe Muster in Netzhautbildern lernt. Durch die Kombination dieser Stärken liefert das System eine genaue und besser interpretierbare Glaukom-Vorsorge als viele bestehende Ansätze. Mit weiterer Prüfung an realen Klinikdaten und möglichen Erweiterungen zur Einstufung des Schweregrads könnte diese Art hybrider KI zu einer praktischen Unterstützung in Augenkliniken werden und dabei helfen, Glaukome früher zu erkennen und vermeidbare Erblindung zu verhindern.
Zitation: Chilukuri, R., Praveen, P., Gatla, R.K. et al. SwinCup-DiscNet: A fusion transformer framework for glaucoma diagnosis using optic disc and cup features. Sci Rep 16, 7920 (2026). https://doi.org/10.1038/s41598-026-39065-7
Schlüsselwörter: Glaukom, Retina-Bildgebung, Tiefes Lernen, Sehnerv, medizinisches Screening