Clear Sky Science · de
RFGLNet für domänen‑generalisierte semantische Segmentierung bei widrigen Wetterbedingungen mit frequenzbasierter Niedrigrang‑Verbesserung
Die Straße sehen, wenn das Wetter schlecht wird
Autonome Autos und Lieferroboter versprechen sicherere, effizientere Straßen — vorausgesetzt, sie können die Umgebung zuverlässig „sehen“. Regen, Nebel, Schnee und dunkle Nächte machen diese Wahrnehmung extrem schwierig: Kontrast geht verloren, es treten Störpunkte auf und die Konturen von Menschen, Autos und Bordsteinkanten werden unscharf. Diese Arbeit stellt RFGLNet vor, ein neues Computer‑Vision‑System, das die Wahrnehmung von Fahrzeugen auch bei schlechtestem Wetter schärf erhalten soll.

Warum Maschinen bei schlechtem Wetter geblendet werden
Die heutigen Systeme für autonomes Fahren stützen sich oft auf semantische Segmentierung, bei der ein Algorithmus jedem Pixel eines Bildes eine Klasse wie Straße, Auto, Fußgänger oder Gebäude zuweist. Bei klarem Tageslicht erledigen moderne neuronale Netze das sehr gut. Unter starkem Regen oder dichtem Nebel verlieren Bilder jedoch Helligkeit, nehmen Rauschen auf und weisen verschwommene Objektgrenzen auf. Es ist extrem teuer, riesige Datensätze für jede erdenkliche Wetterbedingung zu sammeln und zu annotieren, weshalb die meisten Systeme hauptsächlich auf normalen, sonnigen Bildern trainiert werden. Treten unbekannte Stürme oder Schneefälle auf, bricht die Leistung stark ein. Frühere Ansätze versuchten entweder zuerst die Bilder zu säubern und dann zu segmentieren oder die Modelle an bestimmte Zielbedingungen anzupassen. Beide Strategien sind oft brüchig, langsam oder zu abhängig von gelabelten Schlechtwetterdaten.
Ein neues Netzwerk, gebaut für harte Bedingungen
RFGLNet begegnet dem Problem mit einer anderen Strategie: Es lernt ausschließlich aus standardmäßigen Tageslicht‑Straßenszenen, generalisiert aber auf eine breite Palette harscher Bedingungen. Die Autoren bauen auf DINOv2 auf, einem großen, vortrainierten visuellen Modell, das bekannt dafür ist, reichhaltige Szenenstrukturen zu erfassen. Statt diesen schweren Backbone von Grund auf neu zu trainieren, frieren sie seine Parameter ein und ergänzen eine leichtgewichtige Reihe von Modulen. Diese Module fungieren als intelligente Adapter, die die internen Repräsentationen des Backbones so umformen, dass sie weniger durch visuelle Störungen wie Schneeflocken, Regentropfen oder Dunkelheit verwirrt werden. Das Ergebnis ist ein System mit nur 4,32 Millionen trainierbaren Parametern — winzig im Vergleich zu typischen Vision‑Modellen — das dennoch lernt, mit Wetter umzugehen, das es während des Trainings nie gesehen hat.
Wie das Netzwerk lernt, Wetter zu filtern
Die erste Innovation von RFGLNet ist ein Niedrigrangmodul, das in jede Schicht des eingefrorenen Backbones eingesteckt wird. Vor dem Training führt dieses Modul ein mathematisches Verfahren namens Singulärwertzerlegung auf einer simulierten Merkmalsmatrix durch. Dadurch erhält es eine Menge kompakter Komponenten, die von Beginn an grob der Struktur von DINOv2s internen Merkmalen entsprechen, anstatt bei zufälligem Rauschen zu starten. Während des Trainings werden diese Komponenten feinjustiert, sodass das Modul die Backbone‑Merkmale sanft für die neue Aufgabe korrigieren kann, ohne das Kernwissen zu stören. Anschließend wendet das Netzwerk einen auf der Fourier‑Transformation basierenden Attention‑Block an, der die Merkmale in den Frequenzbereich verschiebt. Dort repräsentieren breitbandige, langsam veränderliche Strukturen meist sinnvolle Objekte, während scharfe, erratische Muster oft Wetterrauschen entsprechen. Durch Unterdrückung hochfrequenter Störungen und Verstärkung glatterer Komponenten stärkt das System das globale Szenenverständnis und dämpft gleichzeitig Störeinflüsse.
Details schärfen, ohne sich ablenken zu lassen
Selbst mit sauberen Global‑Features bleiben kleine Details wie Fahrstreifenmarkierungen, Zaunlatten und die Silhouette eines weit entfernten Fußgängers bei schlechtem Wetter anfällig für Unschärfe. Um dem zu begegnen, führen die Autoren ein gruppiertes räumliches Attention‑Modul im Decoder‑Teil des Netzes ein. Anstatt alle Feature‑Kanäle gemeinsam zu behandeln, teilt es sie in Gruppen und lernt für jede Gruppe eigene räumliche Gewichtskarten. Kanäle, die wichtige Strukturen wie Kanten enthalten, können so hervorgehoben werden, während von Rauschen dominierte Kanäle gedämpft werden. Diese gruppenspezifischen Karten werden zu einer globalen räumlichen Gewichtung verschmolzen, die feine Details stärkt und Objektgrenzen über mehrere Auflösungen hinweg schärft. Effektiv lernt RFGLNet, wo genau hingeschaut werden sollte und wo störende Nebel‑ oder Regentropfen ignoriert werden können.
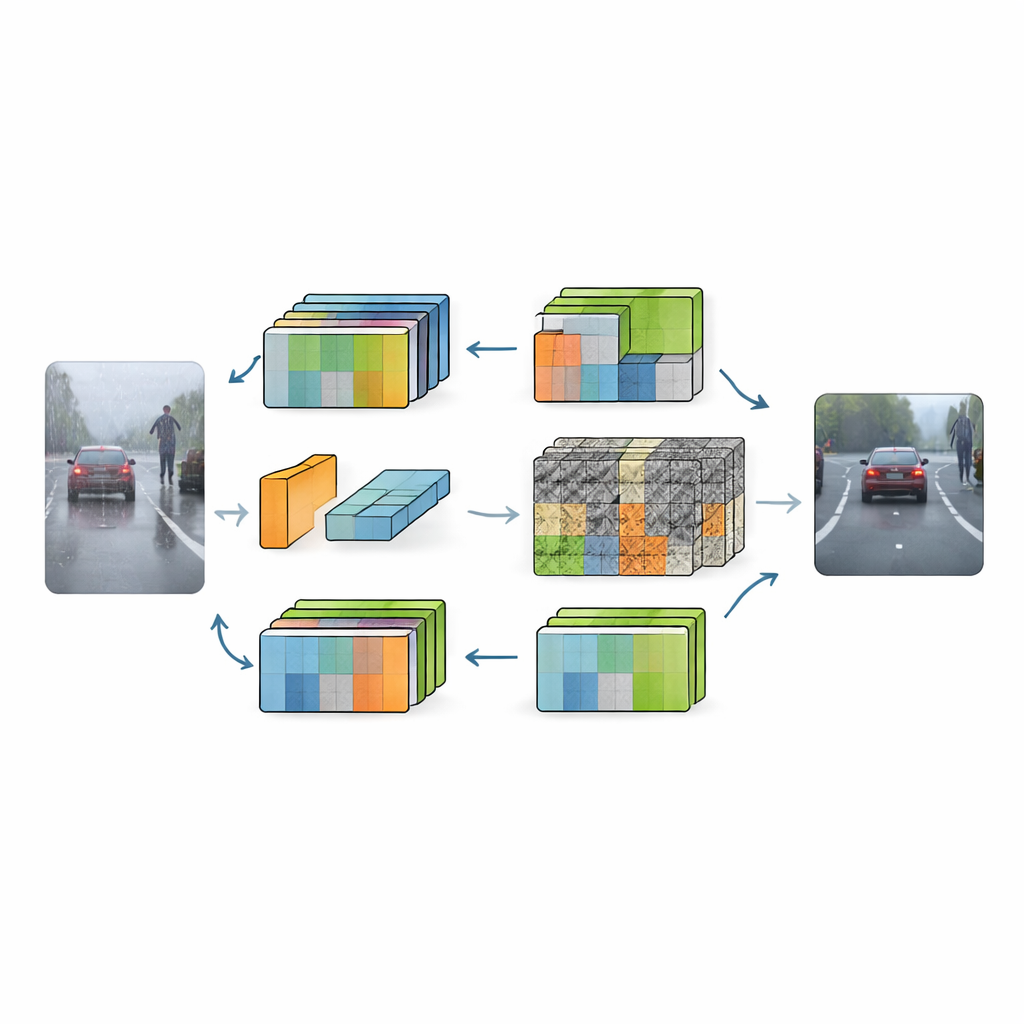
Ergebnisse in realen, herausfordernden Straßenszenen
Um ihren Ansatz zu testen, trainierten die Forschenden RFGLNet auf dem bekannten Cityscapes‑Datensatz mit klaren Tageslicht‑Stadtszenen und evaluierten es anschließend auf dem ACDC‑Datensatz, der Regen, Schnee, Nebel und Nachtfahrten fokussiert. Ohne jemals ACDC‑Labels während des Trainings zu sehen, erzielte RFGLNet eine mittlere Intersection over Union von 78,3 Prozent — und übertraf damit mehrere führende Methoden zur Domänengeneralisierung und -anpassung, von denen viele größer und rechenintensiver sind. Besonders stark war es bei schwer zu segmentierenden Klassen wie Mauern und Zäunen, deren Kanten bei widrigem Wetter leicht verloren gehen. Gleichzeitig lief das Modell effizient auf einer einzelnen handelsüblichen GPU und verarbeitete Dutzende Bilder pro Sekunde, eine Schlüsselforderung für Echtzeit‑Fahrsysteme.
Klarere Sicht für sicherere Autonomie
Für Nicht‑Spezialisten lautet die Quintessenz: RFGLNet zeigt, wie bestehende Vision‑Backbones für sicherere Autonomie verbessert werden können, ohne jede erdenkliche Wetterlage endlos nachzutrainieren. Durch die Kombination kompakter Niedrigrang‑Anpassung, frequenzbasierter Rauschfilterung und gruppierter räumlicher Attention lernt das System, wesentliche Szenenstruktur zu bewahren und wetterbedingtes Durcheinander zu beseitigen. Wenn solche Methoden weiter reifen und auf breiteren Sammlungen realer Bedingungen trainiert werden, könnten sie selbstfahrenden Autos und Robotern helfen, auch bei Dunkelheit und schlechtem Wetter eine verlässliche Situationswahrnehmung zu behalten.
Zitation: Ye, X., Shi, X. & Li, Y. RFGLNet for adverse weather domain-generalized semantic segmentation with frequency low-rank enhancement. Sci Rep 16, 8253 (2026). https://doi.org/10.1038/s41598-026-39052-y
Schlüsselwörter: autonomes Fahren, Wahrnehmung bei widrigem Wetter, semantische Segmentierung, Robustheit in der Computer Vision, Domänengeneralisierung