Clear Sky Science · de
Große Sprachmodelle zeigen Dunning‑Kruger‑ähnliche Effekte beim mehrsprachigen Faktencheck
Warum guter Faktencheck für alle wichtig ist
Fehlinformationen verbreiten sich heute schneller denn je und prägen, was Menschen über Gesundheit, Politik, Wissenschaft und den Alltag glauben. Viele Plattformen und Redaktionen setzen zunehmend auf künstliche Intelligenz — vor allem große Sprachmodelle (LLMs) — um virale Behauptungen auf ihren Wahrheitsgehalt zu prüfen. Diese Studie stellt eine auf den ersten Blick einfache, aber entscheidende Frage: Wenn wir diese Systeme Fakten beurteilen lassen, wie oft liegen sie richtig, wie sicher treten sie auf und ändert sich das je nach Sprache und Region?
Wie die Forschenden KI an realen Gerüchten testeten
Anstatt künstliche Beispiele zu erfinden, bauten die Autorinnen und Autoren ihre Tests aus 5.000 echten Behauptungen auf, die professionelle Faktencheck‑Organisationen weltweit bereits untersucht hatten. Diese Behauptungen deckten 47 Sprachen ab und stammten sowohl aus dem Globalen Norden als auch aus dem Globalen Süden und spiegeln so die unordentliche, multikulturelle Realität von Online‑Gerüchten wider. Es wurden nur Aussagen mit klaren „wahr“‑ oder „falsch“‑Urteilen einbezogen — jeweils von mehreren Faktencheckern bestätigt — wodurch eine belastbare Referenzbasis entstand.
Dann ließen sie neun weit verbreitete Sprachmodelle — von kleineren Open‑Source‑Systemen bis zu fortgeschrittenen kommerziellen Modellen — auf jede Behauptung los. Um zu spiegeln, wie Menschen tatsächlich mit Chatbots sprechen, bestanden die meisten Eingaben aus einfachen Fragen wie „Ist das wahr?“ oder „Ist das falsch?“, jeweils in der gleichen Sprache wie die Behauptung. Eine vierte, eher professionell gestaltete Konfiguration nutzte eine detaillierte Anleitung auf Englisch, die das Modell in einen virtuellen Faktenchecker verwandelte und strukturierte Ausgaben verlangte. Menschliche Annotatorinnen und Annotatoren lasen die Antworten der Modelle sorgfältig und klassifizierten sie als Aussage, die die Behauptung für wahr, falsch hält oder sich weigert, ein klares Urteil abzugeben.
Nicht nur richtig oder falsch messen, sondern auch wann man „Ich weiß nicht“ sagt
Das Team zählte nicht nur Treffer und Fehlentscheidungen. Sie nutzten drei zentrale Messgrößen, um das Verhalten der Modelle zu erfassen. Erstens betrachtete die „selektive Genauigkeit“, wie oft ein Modell richtig lag, wenn es tatsächlich Stellung bezog und eine Behauptung als wahr oder falsch einstufte. Zweitens wertete die „abstention‑freundliche Genauigkeit“ es als akzeptabel — sogar wünschenswert — dass das Modell Unsicherheit eingesteht, anstatt zu raten; das ist in sensiblen Bereichen wie Medizin oder Wahlen wichtig. Drittens erfasste die „Sicherheitsrate“, wie oft ein Modell überhaupt eine definitive Antwort gab, als groben Indikator dafür, wie selbstsicher es auftrat.
Die professionellere Eingabe mit schrittweiser Anleitung erhöhte konsistent die Genauigkeit über alle Modelle hinweg. Gleichzeitig zeigte sich ein Interessenkonflikt: Kleinere Modelle wurden oft entscheidungsfreudiger, ohne zuverlässiger zu werden, während größere Modelle die Struktur nutzten, um seltener, aber bessere Antworten zu geben. Alltäglichere, chatähnliche Eingaben führten zu vorsichtigerem Verhalten, besonders bei schwächeren Modellen, senkten aber auch teilweise deren Genauigkeit.
Wenn weniger fähige Systeme sich selbstsicherer geben
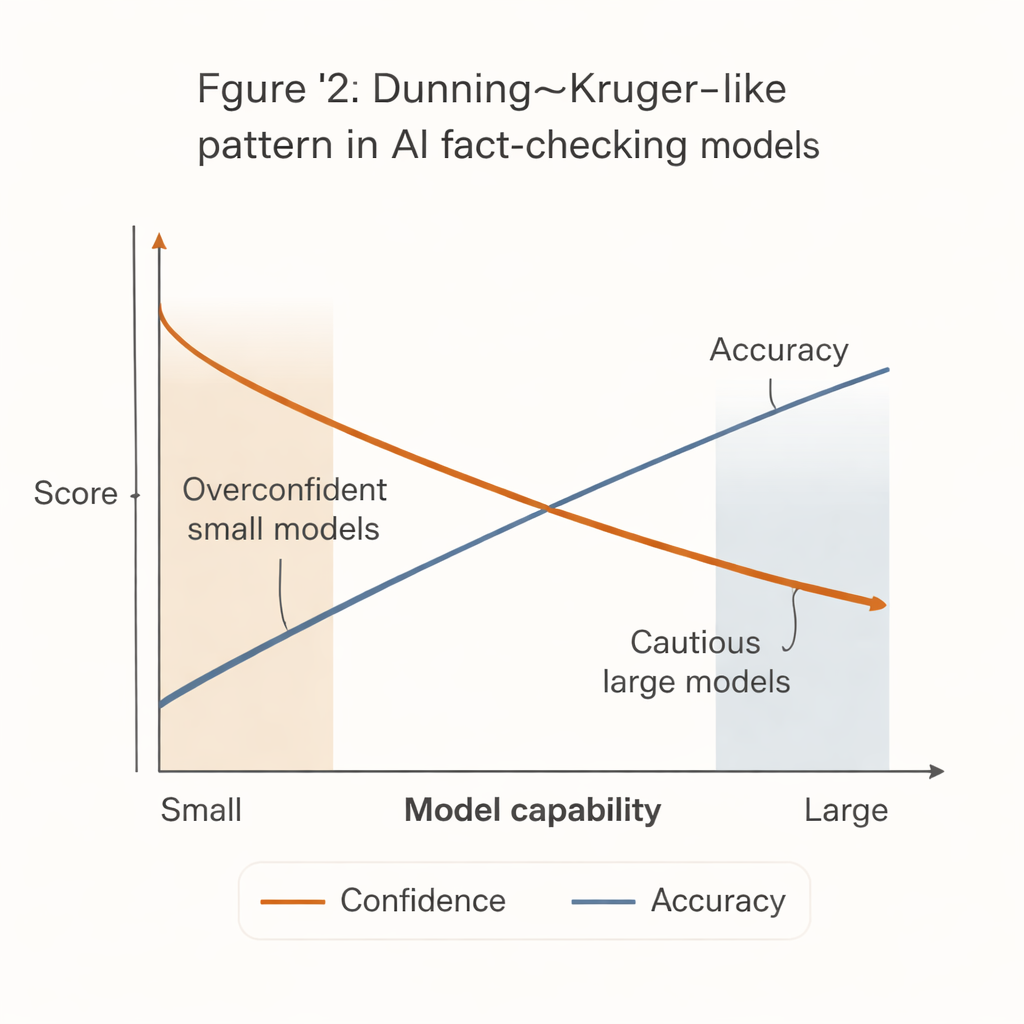
Ein auffälliges Muster trat auf, das dem bekannten Dunning‑Kruger‑Effekt aus der Psychologie ähnelt: Die am wenigsten leistungsfähigen Systeme traten am selbstsichersten auf. Kleine, kostengünstige Modelle neigten dazu, bei der Mehrzahl der Behauptungen feste Urteile zu fällen, allerdings mit deutlich geringerer Genauigkeit. Im Gegensatz dazu waren die stärksten Modelle — etwa fortgeschrittene GPT‑Versionen — bei ihren Zusagen deutlich genauer, zögerten jedoch viel eher, insbesondere bei schwierigen oder mehrdeutigen Aussagen.
Diese „Sicherheits‑Kompetenz‑Lücke“ hat reale Folgen. Viele finanzschwache Redaktionen, zivilgesellschaftliche Gruppen und lokale Faktencheck‑Stellen können sich die leistungsfähigsten KI‑Systeme nicht leisten. Sie werden eher kleinere, billigere Modelle einsetzen, die zwar entschlossen wirken, aber häufiger falsch liegen. Wenn solche Werkzeuge in Arbeitsabläufe oder Community‑Moderationssysteme ohne sorgfältige Schutzmaßnahmen integriert werden, könnten sie Fehlinformationen verstärken, indem sie selbstbewusste, aber falsche Faktenchecks erzeugen.
Ungleiche Leistung je nach Sprache und Region
Die Studie zeigt außerdem, dass diese Systeme nicht für alle gleich gut funktionieren. In mehreren großen Sprachen erzielten Modelle in der Regel die besten Ergebnisse bei englischen Behauptungen und leicht schlechtere bei Portugiesisch und Hindi. Größere Modelle reagierten in nicht‑englischen Sprachen tendenziell vorsichtiger, übertrafen aber dennoch kleinere Modelle in der Genauigkeit. Beim Vergleich von Behauptungen aus dem Globalen Norden und dem Globalen Süden stolperten die meisten Modelle häufiger über letztere. Kleinere Systeme blieben oft zuversichtlich, während ihre Genauigkeit sank, wohingegen große Modelle stärkere Einbrüche in der Selbstsicherheit, aber kleinere Einbußen in der Korrektheit zeigten — ein Indiz dafür, dass sie ihre eigene Unsicherheit eher wahrnahmen und zurückhielten.
Was das für die Zukunft vertrauenswürdiger KI‑Werkzeuge bedeutet
Für Nichtfachleute ist die Kernbotschaft klar: Die heutigen KI‑Faktenchecker sind weit davon entfernt, gleichwertig zu sein, und die am leichtesten zugänglichen können am irreführendsten sein. Leistungsfähige Modelle können vorsichtig und genau sein, sind aber teuer und manchmal übermäßig zögerlich. Schwächere Modelle sind mutig, aber eher fehleranfällig, besonders außerhalb des Englischen und bei Geschichten aus dem Globalen Süden. Die Autorinnen und Autoren plädieren dafür, dass KI Menschliche Faktenchecker unterstützen, aber nicht ersetzen sollte, und dass politische sowie gestalterische Entscheidungen auf bessere Kalibrierung — also Systeme darin zu schulen, wann sie schweigen sollten — und einen gerechteren Zugang zu hochwertigen Werkzeugen abzielen müssen. Andernfalls könnte dieselbe Technologie, die Fehlinformationen bekämpfen soll, die Informationsungleichheiten vertiefen, die sie lösen will.
Zitation: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Schlüsselwörter: Fehlinformationen, Faktencheck, große Sprachmodelle, KI‑Selbstsicherheit, mehrsprachige Verzerrung