Clear Sky Science · de
Eine humanoide Steuerstrategie basierend auf Deep Reinforcement Learning für verbesserten Komfort bei Rehabilitationsrobotern für die unteren Gliedmaßen
Roboter, die Menschen wieder das Gehen ermöglichen
Wenn jemand nach einem Schlaganfall oder einer Rückenmarksverletzung Probleme beim Gehen hat, kann die Therapie langsam, ermüdend und unbequem sein. Rehabilitationsroboter für die unteren Gliedmaßen sind dafür ausgelegt, die Beine der Patientin oder des Patienten während der Übung zu stützen und zu führen, doch die heutigen Maschinen wirken oft steif und "robotisch". Diese Studie untersucht, wie man diesen Robotern durch fortgeschrittene Lernalgorithmen ein menschlicheres "Gehirn" geben kann, um das Training sanfter, natürlicher und letztlich effektiver für die Patientinnen und Patienten zu machen.
Warum Gehübungen sich natürlich anfühlen müssen
Mit alternden Bevölkerungen leben immer mehr Menschen mit ernsthaften Gehproblemen, und viele wenden sich der robotergestützten Rehabilitation zu. Traditionelle Roboter folgen vorprogrammierten Beinstrukturen und verwenden einfache Regelkreise zur Bewegung der Gelenke. Zwar sind diese Methoden zuverlässig, sie stoßen jedoch an ihre Grenzen angesichts der unordentlichen Realität menschlicher Bewegung: Jeder Gang ist etwas anders, und ein starrer Roboter kann in einer Weise ziehen oder drücken, die sich unbehaglich oder schmerzhaft anfühlt. Die Autoren argumentieren, dass damit Rehabilitation gut funktioniert, der Roboter nicht nur die Patientin oder den Patienten aufrecht und in Bewegung halten, sondern sich auch an natürliche Gangmuster anpassen und die auf den Körper wirkenden Kräfte minimieren muss.
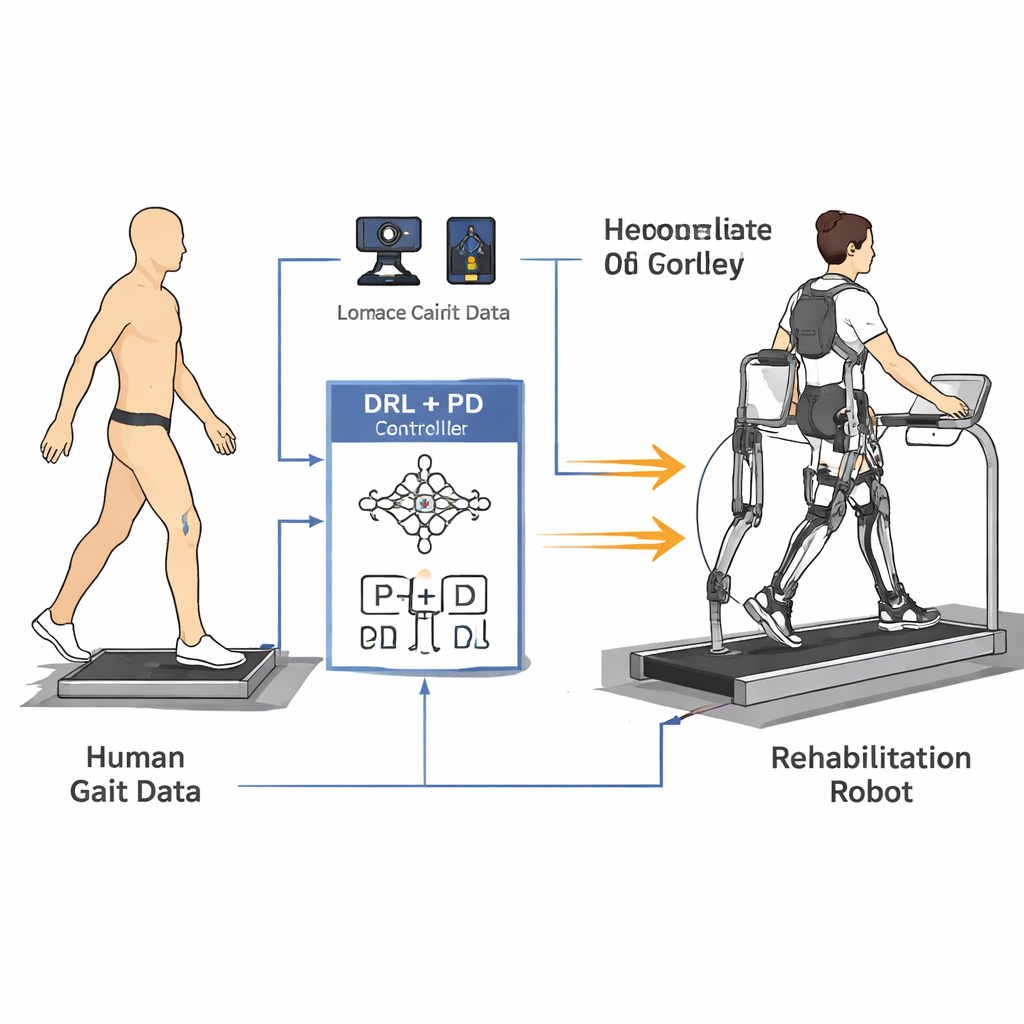
Vom echten menschlichen Schritt lernen
Um dem Roboter beizubringen, wie Menschen tatsächlich gehen, bauten die Forschenden zunächst ein vereinfachtes mathematisches Modell von Beinen und Rumpf. Anschließend zeichneten sie Gangdaten von fünf gesunden Probanden mit einem hochpräzisen 3D-Bewegungsaufzeichnungssystem und Kraftplatten im Boden auf. Reflektierende Marker an Hüfte, Knie, Knöchel und Rumpf ermöglichten es, zu berechnen, wie sich jedes Gelenk während eines vollständigen Schritts bewegte, während Sensoren unter den Füßen maßen, mit welcher Kraft jedes Bein auf den Boden drückte. Aus diesen Messungen erstellten sie glatte Referenzkurven für Hüft- und Kniewinkel und verfolgten, wie sich Gelenkkräfte im Zeitverlauf änderten, sodass sowohl die Form als auch der Rhythmus normalen Gehens erfasst wurden.
Ein klügerer Regler, der dennoch sicher bleibt
Kern der Arbeit ist eine neue "humanoide" Steuerstrategie, die Deep Reinforcement Learning (DRL) mit einem klassischen Proportional-Differential-(PD-)Regler kombiniert. DRL ist eine Form künstlicher Intelligenz, bei der ein virtueller Agent Aktionen ausprobiert, die Ergebnisse beobachtet und durch Maximierung eines Belohnungssignals schrittweise herausfindet, was am besten funktioniert. In diesem Fall sitzt der Agent „auf“ dem PD-Regler: Er sieht die Gelenkwinkel und -geschwindigkeiten des Roboters und entscheidet, welche Drehmomente anzuwenden sind, während die PD-Schicht sicherstellt, dass die Gelenke nicht weit von sicheren, menschenähnlichen Zielwinkeln abweichen. Die Belohnungsfunktion ist sorgfältig formuliert, um stabiles Vorwärtsgehen zu fördern und alles zu bestrafen, was sich für eine Patientin oder einen Patienten unangenehm anfühlen würde — etwa ruckartige Bewegungen, große Kräfte in den Gelenken oder unsichere Haltungen wie übermäßiges Vorlehnen oder geringe Fußfreiheit.
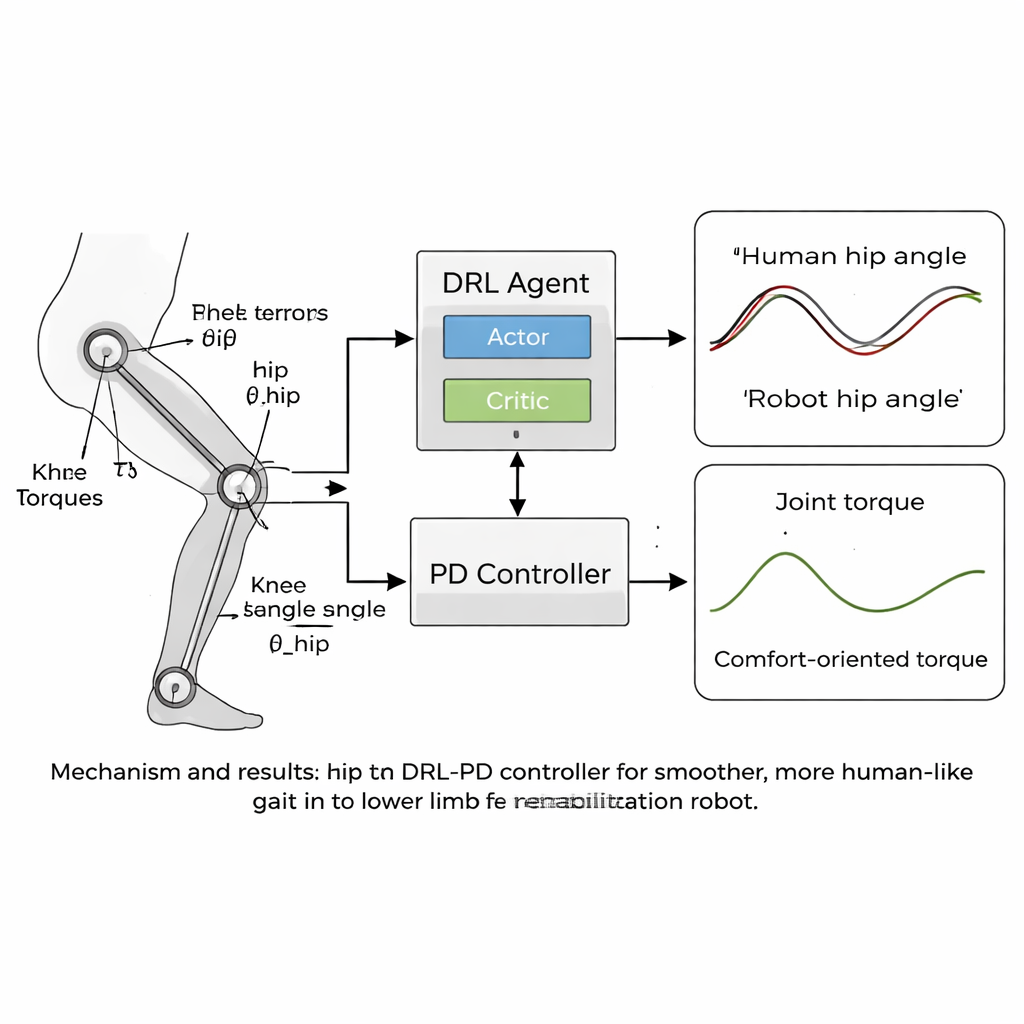
Sanftere Bewegungen, näher am menschlichen Gang
Das Team testete seinen Ansatz in Computersimulationen mit einem Modell eines Rehabilitationsroboters für die unteren Gliedmaßen, dessen Hüft- und Kniegelenke den Gangdaten entsprachen. Über Tausende von Trainingsdurchläufen lernte der DRL-PD-Regler, einen wiederkehrenden Gehzyklus zu erzeugen, in dem die Gelenkwinkel die menschlichen Referenzmuster eng nachfolgten. Die Hüften und Knie des Roboters bewegten sich in regelmäßigen, stabilen Schleifen, ein Zeichen für einen zuverlässigen, reproduzierbaren Gang. Entscheidend war, dass die zum Antreiben der Gelenke benötigten Drehmomente im Vergleich zu einem Standard-PD-Regler glatter und kleiner wurden. Quantitative Messungen zeigten, dass die Trackingfehler auf nur wenige Hundertstel Radiant sanken und die Änderungsrate der Gelenkdrehmomente — ein Indikator dafür, wie "ruckartig" die Kräfte für eine Patientin oder einen Patienten wirken würden — um mehr als die Hälfte reduziert wurde. Der Regler blieb außerdem stabil, selbst als die Beinmassen des Modells um mehrere Prozent variiert wurden, was darauf hindeutet, dass er reale Unterschiede zwischen Nutzerinnen und Nutzern tolerieren könnte.
Was das für zukünftige Reha-Roboter bedeutet
Für Nichtfachleute ist die Kernaussage einfach: Indem man einem Roboter erlaubt, Rhythmus und Grenzen des menschlichen Gehens aus echten Daten zu lernen, und ihn dafür belohnt, sanft und gleichmäßig zu sein, lassen sich Maschinen entwickeln, die Menschen beim Gehtraining auf eine natürlicher und weniger belastende Weise unterstützen. Patientinnen und Patienten sind möglicherweise eher bereit, längere und häufigere Sitzungen durchzuführen, wenn der Roboter mit ihnen statt gegen sie arbeitet. Obwohl die aktuellen Ergebnisse aus Simulationen stammen und für das Training leistungsstarke Rechner benötigen, kann der Regler nach abgeschlossener Lernphase effizient auf realen Geräten laufen. Die Autorinnen und Autoren sehen diese Arbeit als einen Schritt hin zu personalisierten, adaptiven Rehabilitationsrobotern, die sich an den individuellen Gang und die Komfortbedürfnisse jeder Patientin und jedes Patienten anpassen und dadurch Recovery und Lebensqualität verbessern könnten.
Zitation: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Schlüsselwörter: Rehabilitationsroboter, Gangtraining, Deep Reinforcement Learning, Exoskelett, Patientenkomfort